“Stiamo lasciando l’era dell’informazione ed entrando nell’era della raccomandazione.”
Come molte tecniche di apprendimento automatico, un recommender system fa previsioni basate sui comportamenti storici degli utenti. In particolare, si tratta di prevedere la preferenza dell’utente per un insieme di articoli in base all’esperienza passata. Per costruire un sistema di raccomandazione, i due approcci più popolari sono Content-based e Collaborative Filtering.
L’approccio basato sul contenuto richiede una buona quantità di informazioni sulle caratteristiche degli articoli, piuttosto che usare le interazioni e i feedback degli utenti. Per esempio, possono essere gli attributi dei film come il genere, l’anno, il regista, l’attore ecc. o il contenuto testuale degli articoli che possono essere estratti applicando il Natural Language Processing. Il Collaborative Filtering, d’altra parte, non ha bisogno di nient’altro se non delle preferenze storiche degli utenti su un insieme di articoli. Poiché si basa su dati storici, il presupposto fondamentale qui è che gli utenti che hanno concordato in passato tendono a concordare anche in futuro. In termini di preferenza dell’utente, di solito è espressa da due categorie. Valutazione esplicita, è un tasso dato da un utente ad un elemento su una scala scorrevole, come 5 stelle per Titanic. Questo è il feedback più diretto da parte degli utenti per mostrare quanto gli piace un elemento. La valutazione implicita, suggerisce la preferenza degli utenti indirettamente, come le visualizzazioni della pagina, i clic, i record di acquisto, se ascoltare o meno un brano musicale, e così via. In questo articolo, darò uno sguardo da vicino al filtraggio collaborativo che è uno strumento tradizionale e potente per i sistemi di raccomandazione.
Il metodo standard di filtraggio collaborativo è noto come algoritmo Neighborhood. Ci sono CF basati sugli utenti e CF basati sugli elementi. Guardiamo prima il CF basato sull’utente. Abbiamo una matrice n × m di valutazioni, con utente uᵢ, i = 1, …n e articolo pⱼ, j=1, …m. Ora vogliamo predire il rating rᵢⱼ se l’utente target i non ha guardato/valutato un elemento j. Il processo è quello di calcolare le somiglianze tra l’utente target i e tutti gli altri utenti, selezionare i primi X utenti simili, e prendere la media ponderata dei rating da questi X utenti con le somiglianze come pesi.


Mentre persone diverse possono avere basi diverse quando danno valutazioni, alcune persone tendono a dare punteggi alti in generale, altre sono piuttosto severe anche se sono soddisfatte degli articoli. Per evitare questa distorsione, possiamo sottrarre la valutazione media di ogni utente di tutti gli articoli quando si calcola la media ponderata, e aggiungerla di nuovo per l’utente target, come mostrato di seguito.

Due modi per calcolare la similarità sono la Correlazione di Pearson e la Similarità Coseno.
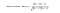

In sostanza, l’idea è di trovare gli utenti più simili al vostro utente target (vicini più vicini) e pesare le loro valutazioni di un elemento come la previsione della valutazione di questo elemento per l’utente target.
Senza sapere nulla degli elementi e degli utenti stessi, pensiamo che due utenti siano simili quando danno valutazioni simili allo stesso elemento. Analogamente, per la CF basata sugli articoli, diciamo che due articoli sono simili quando hanno ricevuto valutazioni simili da uno stesso utente. Quindi, faremo una previsione per un utente target su un articolo calcolando la media ponderata delle valutazioni sulla maggior parte degli articoli simili X di questo utente. Un vantaggio chiave della CF basata sugli elementi è la stabilità, cioè che le valutazioni su un dato elemento non cambieranno significativamente nel tempo, a differenza dei gusti degli esseri umani.

Ci sono alcune limitazioni di questo metodo. Non gestisce bene la sparsità quando nessuno nel quartiere ha valutato un elemento che è quello che si sta cercando di predire per l’utente target. Inoltre, non è efficiente dal punto di vista computazionale con la crescita del numero di utenti e prodotti.
Fattorizzazione della matrice
Siccome la sparsità e la scalabilità sono le due maggiori sfide per il metodo CF standard, arriva un metodo più avanzato che decompone la matrice rada originale in matrici bidimensionali con fattori/caratteristiche latenti e meno sparsità. Questa è la fattorizzazione della matrice.
Oltre a risolvere i problemi di sparsità e scalabilità, c’è una spiegazione intuitiva del perché abbiamo bisogno di matrici bidimensionali per rappresentare le preferenze degli utenti. Un utente ha dato buone valutazioni ai film Avatar, Gravity e Inception. Non sono necessariamente 3 opinioni separate, ma mostrano che questo utente potrebbe essere a favore dei film di fantascienza e ci potrebbero essere molti altri film di fantascienza che questo utente vorrebbe. A differenza dei film specifici, le caratteristiche latenti sono espresse da attributi di livello superiore, e la categoria Sci-Fi è una delle caratteristiche latenti in questo caso. Ciò che la fattorizzazione della matrice alla fine ci dà è quanto un utente è allineato con un insieme di caratteristiche latenti, e quanto un film si adatta a questo insieme di caratteristiche latenti. Il vantaggio rispetto al nearest neighborhood standard è che anche se due utenti non hanno valutato gli stessi film, è ancora possibile trovare la somiglianza tra loro se condividono i gusti di fondo simili, di nuovo le caratteristiche latenti.
Per vedere come una matrice viene fattorizzata, la prima cosa da capire è la Decomposizione del Valore Singolare (SVD). Basandosi sull’algebra lineare, qualsiasi matrice reale R può essere decomposta in 3 matrici U, Σ e V. Continuando a usare l’esempio del film, U è una matrice n × r di caratteristiche latenti dell’utente, V è una matrice m × r di caratteristiche latenti del film. Σ è una matrice diagonale r × r contenente i valori singolari della matrice originale, che rappresenta semplicemente quanto sia importante una specifica caratteristica per prevedere la preferenza dell’utente.

Per ordinare i valori di Σ per valore assoluto decrescente e troncare la matrice Σ alle prime k dimensioni (k valori singolari), possiamo ricostruire la matrice come matrice A. La selezione di k dovrebbe fare in modo che A sia in grado di catturare la maggior parte della varianza all’interno della matrice originale R, in modo che A sia l’approssimazione di R, A ≈ R. La differenza tra A e R è l’errore che dovrebbe essere minimizzato. Questo è esattamente il pensiero della Principle Component Analysis.

Quando la matrice R è densa, U e V potrebbero essere facilmente fattorizzati analiticamente. Tuttavia, una matrice di valutazioni di film è super sparsa. Anche se ci sono alcuni metodi di imputazione per riempire i valori mancanti, ci rivolgeremo ad un approccio di programmazione per convivere con quei valori mancanti e trovare le matrici fattoriali U e V. Invece di fattorizzare R tramite SVD, cerchiamo di trovare direttamente U e V con l’obiettivo che quando U e V vengono moltiplicati insieme la matrice di uscita R’ sia l’approssimazione più vicina a R e non più una matrice rada. Questa approssimazione numerica si ottiene di solito con la fattorizzazione di matrici non negative per i sistemi di raccomandazione, dato che non ci sono valori negativi nelle valutazioni.
Vedi la formula qui sotto. Guardando la valutazione prevista per uno specifico utente e articolo, l’articolo i è notato come un vettore qᵢ, e l’utente u è notato come un vettore pᵤ tale che il prodotto del punto di questi due vettori è la valutazione prevista per l’utente u sull’articolo i. Questo valore è presentato nella matrice R’ alla riga u e alla colonna i.


Come troviamo qᵢ e pᵤ ottimali? Come la maggior parte dei compiti di apprendimento automatico, viene definita una funzione di perdita per minimizzare il costo degli errori.

rᵤᵢ è la vera valutazione dalla matrice originale utente-item. Il processo di ottimizzazione consiste nel trovare la matrice P ottimale composta dal vettore pᵤ e la matrice Q composta dal vettore qᵢ al fine di minimizzare l’errore quadratico tra le valutazioni previste rᵤᵢ’ e le valutazioni vere rᵤᵢ. Inoltre, è stata aggiunta la regolarizzazione L2 per prevenire l’overfitting dei vettori utente e articolo. È anche abbastanza comune aggiungere il termine bias che di solito ha 3 componenti principali: valutazione media di tutti gli elementi μ, valutazione media dell’elemento i meno μ (nota come bᵤ), valutazione media data dall’utente u meno u (nota come bᵢ).

Ottimizzazione
Alcuni algoritmi di ottimizzazione sono stati popolari per risolvere la fattorizzazione non negativa. Alternative Least Square è uno di questi. Poiché la funzione di perdita non è convessa in questo caso, non c’è modo di raggiungere un minimo globale, mentre può ancora raggiungere una grande approssimazione trovando minimi locali. L’alternativa Least Square consiste nel mantenere costante la matrice del fattore utente, regolare la matrice del fattore articolo prendendo le derivate della funzione di perdita e impostandola uguale a 0, e poi impostare la matrice del fattore articolo costante mentre si regola la matrice del fattore utente. Ripetete il processo cambiando e regolando le matrici avanti e indietro fino alla convergenza. Se si applica il modello NMF di Scikit-learn, si vedrà che ALS è il solutore predefinito da utilizzare, che è anche chiamato Coordinate Descent. Pyspark offre anche pacchetti di decomposizione piuttosto ordinati che forniscono una maggiore flessibilità di sintonizzazione di ALS stesso.
Alcuni pensieri
Il filtraggio collaborativo fornisce un forte potere predittivo per i sistemi di raccomandazione, e richiede il minor numero di informazioni allo stesso tempo. Tuttavia, ha alcune limitazioni in alcune situazioni particolari.
In primo luogo, i gusti sottostanti espressi dalle caratteristiche latenti non sono in realtà interpretabili perché non ci sono proprietà dei metadati legate al contenuto. Per esempio, un film non deve necessariamente essere un genere come lo Sci-Fi nel mio esempio. Può essere quanto è motivante la colonna sonora, quanto è buona la trama, e così via. Il filtraggio collaborativo manca di trasparenza e spiegabilità di questo livello di informazione.
D’altra parte, il filtraggio collaborativo si trova di fronte ad un avvio a freddo. Quando arriva un nuovo articolo, finché non deve essere valutato da un numero sostanziale di utenti, il modello non è in grado di fare alcuna raccomandazione personalizzata. Allo stesso modo, per gli elementi della coda che non hanno ottenuto troppi dati, il modello tende a dare meno peso su di loro e hanno bias di popolarità raccomandando gli elementi più popolari.
Di solito è una buona idea avere algoritmi di ensemble per costruire un modello di apprendimento automatico più completo, come la combinazione di filtraggio basato sul contenuto aggiungendo alcune dimensioni di parole chiave che sono spiegabili, ma dovremmo sempre considerare il compromesso tra modello / complessità computazionale e l’efficacia del miglioramento delle prestazioni.