“Estamos deixando a idade da informação e entrando na idade da recomendação”
Como muitas técnicas de aprendizagem de máquinas, um sistema de recomendação faz previsões baseadas nos comportamentos históricos dos usuários. Especificamente, é para prever a preferência do usuário por um conjunto de itens com base na experiência passada. Para construir um sistema de recomendação, as duas abordagens mais populares são Filtragem baseada no conteúdo e Filtragem colaborativa.
A abordagem baseada no conteúdo requer uma boa quantidade de informações dos próprios recursos dos itens, ao invés de usar as interações e feedbacks dos usuários. Por exemplo, podem ser atributos de filmes como gênero, ano, diretor, ator, etc., ou conteúdo textual de artigos que podem ser extraídos através da aplicação do Processamento de Linguagem Natural. A Filtragem Colaborativa, por outro lado, não precisa de mais nada, exceto a preferência histórica dos usuários em um conjunto de itens. Por ser baseado em dados históricos, a suposição central aqui é que os usuários que concordaram no passado tendem a concordar também no futuro. Em termos de preferência do usuário, ela normalmente é expressa por duas categorias. A Classificação Explícita, é uma taxa dada por um usuário a um item numa escala móvel, como 5 estrelas para o Titanic. Este é o feedback mais direto dos usuários para mostrar o quanto eles gostam de um item. Implicit Rating, sugere que os usuários preferem indiretamente, tais como visualizações de páginas, cliques, compra de discos, ouvir ou não uma faixa musical, e assim por diante. Neste artigo, vou dar uma olhada de perto na filtragem colaborativa que é uma ferramenta tradicional e poderosa para sistemas de recomendação.
O método padrão de Filtragem Colaborativa é conhecido como algoritmo de Bairro Mais Próximo. Existem CF baseados no usuário e CF baseados em itens. Vamos primeiro analisar o CF baseado no usuário. Temos uma matriz n × m de classificações, com o usuário uᵢ, i = 1, …n e item pⱼ, j=1, …m. Agora queremos prever a classificação rᵢⱼ se o usuário alvo i não observou/atribuiu um item j. O processo é calcular as semelhanças entre o usuário alvo i e todos os outros usuários, selecionar os X principais usuários similares e pegar a média ponderada das classificações desses X usuários com semelhanças como pesos.


Embora diferentes pessoas possam ter diferentes linhas de base ao dar classificações, algumas pessoas tendem a dar classificações geralmente altas, algumas são bastante rígidas mesmo que estejam satisfeitas com os itens. Para evitar este viés, podemos subtrair a classificação média de cada usuário de todos os itens ao calcular a média ponderada, e adicioná-la de volta para o usuário alvo, mostrado como abaixo.

Duas formas de calcular similaridade são a Correlação Pearson e a Similaridade Cosina.
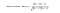

Basicamente, a idéia é encontrar os usuários mais similares ao seu usuário alvo (vizinhos mais próximos) e ponderar suas classificações de um item como a previsão da classificação deste item para o usuário alvo.
Sem saber nada sobre os itens e os próprios usuários, pensamos que dois usuários são semelhantes quando dão ao mesmo item classificações semelhantes . Analogamente, para CF baseado no item, dizemos que dois itens são similares quando eles receberam classificações similares de um mesmo usuário. Então, faremos uma previsão para um usuário alvo em um item calculando a média ponderada das classificações na maioria dos X itens semelhantes deste usuário. Uma vantagem chave do CF baseado em itens é a estabilidade que é que as classificações em um determinado item não mudarão significativamente no tempo, ao contrário dos gostos dos seres humanos.

Existem bastantes limitações deste método. Ele não lida bem com a sparsity quando ninguém na vizinhança classificou um item que é o que você está tentando prever para o usuário alvo. Além disso, não é computacional eficiente como o crescimento do número de usuários e produtos.
Matrix Factorization
Desde que sparsity e escalabilidade são os dois maiores desafios para o método CF padrão, ele vem um método mais avançado que decompõe a matriz esparsa original em matrizes de baixa dimensão com fatores/características latentes e menos sparsity. Isto é Matriz de Factorização.
Beside resolvendo as questões de sparsity e escalabilidade, há uma explicação intuitiva de porque precisamos de matrizes de baixa dimensão para representar a preferência dos usuários. Um usuário deu boas avaliações ao filme Avatar, Gravity, e Inception. Eles não são necessariamente 3 opiniões separadas, mas mostram que esse usuário pode ser a favor dos filmes de ficção científica e pode haver muito mais filmes de ficção científica que esse usuário gostaria. Ao contrário de filmes específicos, os recursos latentes são expressos por atributos de nível mais alto, e a categoria Sci-Fi é um dos recursos latentes neste caso. O que a factorização matricial eventualmente nos dá é o quanto um usuário está alinhado com um conjunto de recursos latentes e o quanto um filme se encaixa nesse conjunto de recursos latentes. A vantagem disso sobre a vizinhança padrão mais próxima é que mesmo que dois usuários não tenham classificado nenhum filme igual, ainda é possível encontrar a semelhança entre eles se eles compartilharem os gostos subjacentes semelhantes, novamente características latentes.
Para ver como uma matriz sendo fatorizada, a primeira coisa a entender é a Decomposição de Valor Singular (SVD). Baseado na Álgebra Linear, qualquer matriz real R pode ser decomposta em 3 matrizes U, Σ, e V. Continuando usando o exemplo do filme, U é uma matriz de características n × r, V é uma matriz de características m × r. Σ é uma matriz diagonal de r × r contendo os valores singulares da matriz original, representando simplesmente a importância de uma característica específica para prever a preferência do utilizador.

Para ordenar os valores de Σ diminuindo o valor absoluto e truncando a matriz Σ para as primeiras k dimensões ( k valores singulares), podemos reconstruir a matriz como matriz A. A seleção de k deve garantir que A seja capaz de capturar a maior parte da variância dentro da matriz R original, de modo que A seja a aproximação de R, A ≈ R. A diferença entre A e R é o erro que se espera que seja minimizado. Este é exatamente o pensamento de Principle Component Analysis.

Quando a matriz R é densa, U e V poderiam ser facilmente fatorizados analiticamente. No entanto, uma matriz de classificações de filmes é super esparsa. Embora existam alguns métodos de imputação para preencher os valores em falta, vamos recorrer a uma abordagem de programação para viver apenas com esses valores em falta e encontrar matrizes de fatores U e V. Ao invés de fatorizar R via SVD, estamos tentando encontrar U e V diretamente com o objetivo de que quando U e V se multiplicam de volta, a matriz de saída R’ é a aproximação mais próxima de R e não mais uma matriz esparsa. Esta aproximação numérica é normalmente alcançada com a Factorização da Matriz Não-Negativa para sistemas recomendados uma vez que não há valores negativos nas classificações.
Veja a fórmula abaixo. Olhando para a classificação prevista para usuário e item específicos, o item i é notado como um vetor qᵢ, e o usuário u é notado como um vetor pᵤ de tal forma que o produto ponto destes dois vetores é a classificação prevista para o usuário u no item i. Este valor é apresentado na matriz R’ na linha u e coluna i.


>
Como encontramos o melhor qᵢ e pᵤ? Como a maioria das tarefas de aprendizagem da máquina, uma função de perda é definida para minimizar o custo dos erros.

rᵤᵢ é a verdadeira classificação da matriz original de itens do usuário. O processo de otimização é encontrar a matriz ótima P composta pelo vetor pᵤ e a matriz Q composta pelo vetor qᵢ a fim de minimizar o erro quadrático da soma entre as classificações previstas rᵤᵢ’ e as classificações verdadeiras rᵤᵢ. Além disso, a regularização L2 foi adicionada para evitar o ajuste excessivo dos vetores de usuário e de item. É também bastante comum adicionar o termo bias que normalmente tem 3 componentes principais: classificação média de todos os itens μ, classificação média do item i menos μ(anotado como bᵤ), classificação média dada pelo usuário u menos u(anotado como bᵢ).

Optimização
Poucos algoritmos de otimização têm sido populares para resolver a Factorização Não-Negativa. O Quadrado Mínimo Alternativo é um deles. Como a função de perda é não-convexa neste caso, não há como alcançar um mínimo global, enquanto ainda pode alcançar uma grande aproximação ao encontrar mínimos locais. Alternativa ao Quadrado Mínimo é manter constante a matriz de fatores do usuário, ajustar a matriz de fatores de item tomando a função derivada da perda e definindo-a igual a 0, e então definir a matriz de fatores de item constante enquanto ajusta a matriz de fatores do usuário. Repita o processo mudando e ajustando matrizes para frente e para trás até a convergência. Se você aplicar o modelo Scikit-learn NMF, você verá que o ALS é o solucionador padrão a ser usado, que também é chamado de Descendente de Coordenadas. Pyspark também oferece pacotes de decomposição bem arrumados que fornecem mais flexibilidade de ajuste do próprio ALS.
alguns Pensamentos
Filtragem Colaborativa fornece um forte poder preditivo para sistemas recomendados, e requer o mínimo de informação ao mesmo tempo. Contudo, tem algumas limitações em algumas situações particulares.
Primeiro, os gostos subjacentes expressos pelas características latentes não são na verdade interpretáveis porque não há propriedades relacionadas ao conteúdo dos metadados. Por exemplo, no meu exemplo, não é necessariamente um gênero como Sci-Fi. Pode ser a motivação da trilha sonora, a qualidade da trama, etc. Collaborative Filtering é a falta de transparência e explicabilidade deste nível de informação.
Por outro lado, Collaborative Filtering é confrontado com um arranque a frio. Quando um novo item entra, até ter que ser classificado por um número substancial de usuários, o modelo não é capaz de fazer nenhuma recomendação personalizada . Da mesma forma, para itens da cauda que não obtiveram muitos dados, o modelo tende a dar menos peso sobre eles e a ter viés de popularidade, recomendando itens mais populares.
É geralmente uma boa idéia ter algoritmos de conjunto para construir um modelo mais abrangente de aprendizagem da máquina, como combinar filtragem baseada em conteúdo, adicionando algumas dimensões de palavras-chave que são explicáveis, mas devemos sempre considerar o tradeoff entre modelo/complexidade computacional e a eficácia da melhoria de desempenho.