« Nous quittons l’âge de l’information et entrons dans l’âge de la recommandation. »
Comme beaucoup de techniques d’apprentissage automatique, un système de recommandation fait des prédictions basées sur les comportements historiques des utilisateurs. Plus précisément, il s’agit de prédire la préférence des utilisateurs pour un ensemble d’éléments en fonction de leur expérience passée. Pour construire un système de recommandation, les deux approches les plus populaires sont basées sur le contenu et le filtrage collaboratif.
L’approche basée sur le contenu nécessite une bonne quantité d’informations sur les caractéristiques propres des éléments, plutôt que d’utiliser les interactions et les retours des utilisateurs. Par exemple, il peut s’agir d’attributs de films tels que le genre, l’année, le réalisateur, l’acteur, etc. ou du contenu textuel des articles qui peut être extrait en appliquant le traitement du langage naturel. Le filtrage collaboratif, quant à lui, n’a besoin de rien d’autre que les préférences historiques des utilisateurs sur un ensemble d’éléments. Parce qu’il est basé sur des données historiques, l’hypothèse de base ici est que les utilisateurs qui ont été d’accord dans le passé ont tendance à l’être aussi dans le futur. En termes de préférence des utilisateurs, elle est généralement exprimée par deux catégories. L’évaluation explicite est une note donnée par un utilisateur à un élément sur une échelle mobile, comme 5 étoiles pour Titanic. Il s’agit de la réaction la plus directe des utilisateurs pour montrer à quel point ils aiment un produit. La notation implicite, suggère indirectement la préférence des utilisateurs, comme les pages vues, les clics, les achats, l’écoute ou non d’un morceau de musique, etc. Dans cet article, je vais examiner de près le filtrage collaboratif qui est un outil traditionnel et puissant pour les systèmes de recommandation.
La méthode standard du filtrage collaboratif est connue sous le nom d’algorithme du plus proche voisinage. Il existe des FC basés sur l’utilisateur et des FC basés sur l’élément. Examinons d’abord le CF basé sur l’utilisateur. Nous avons une matrice n × m d’évaluations, avec l’utilisateur uᵢ, i = 1, …n et l’élément pⱼ, j=1, …m. Maintenant, nous voulons prédire la note rᵢⱼ si l’utilisateur cible i n’a pas regardé/noté un élément j. Le processus consiste à calculer les similarités entre l’utilisateur cible i et tous les autres utilisateurs, à sélectionner les X meilleurs utilisateurs similaires, et à prendre la moyenne pondérée des notes de ces X utilisateurs avec les similarités comme poids.


Alors que différentes personnes peuvent avoir différentes bases de référence lorsqu’elles donnent des notes, certaines personnes ont tendance à donner des notes élevées en général, d’autres sont assez strictes même si elles sont satisfaites des articles. Pour éviter ce biais, nous pouvons soustraire la note moyenne de chaque utilisateur pour tous les éléments lors du calcul de la moyenne pondérée, et la rajouter pour l’utilisateur cible, comme indiqué ci-dessous.

Deux façons de calculer la similarité sont la corrélation de Pearson et la similarité en cosinus.
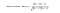

Basiquement, l’idée est de trouver les utilisateurs les plus similaires à votre utilisateur cible (plus proches voisins) et de pondérer leurs évaluations d’un élément comme la prédiction de l’évaluation de cet élément pour l’utilisateur cible.
Sans rien savoir des items et des utilisateurs eux-mêmes, nous pensons que deux utilisateurs sont similaires lorsqu’ils donnent des notes similaires au même item . Analogiquement, pour la FC basée sur les items, nous disons que deux items sont similaires lorsqu’ils ont reçu des évaluations similaires d’un même utilisateur. Ensuite, nous ferons une prédiction pour un utilisateur cible sur un élément en calculant la moyenne pondérée des évaluations sur la plupart des X éléments similaires de cet utilisateur. L’un des principaux avantages de la FC basée sur les éléments est la stabilité, c’est-à-dire que les évaluations sur un élément donné ne changeront pas de manière significative au fil du temps, contrairement aux goûts des êtres humains.

Cette méthode présente pas mal de limites. Elle ne gère pas bien la sparsité lorsque personne dans le voisinage n’a évalué un élément qui est ce que vous essayez de prédire pour l’utilisateur cible. En outre, il n’est pas efficace en termes de calcul comme la croissance du nombre d’utilisateurs et de produits.
Matrix Factorization
Puisque la sparsité et l’évolutivité sont les deux plus grands défis pour la méthode CF standard, il vient une méthode plus avancée qui décompose la matrice clairsemée d’origine à des matrices de faible dimension avec des facteurs latents / caractéristiques et moins de sparsité. C’est la factorisation matricielle.
En dehors de la résolution des problèmes de sparsité et d’évolutivité, il y a une explication intuitive de la raison pour laquelle nous avons besoin de matrices à faible dimension pour représenter la préférence des utilisateurs. Un utilisateur a donné de bonnes notes aux films Avatar, Gravity et Inception. Il ne s’agit pas nécessairement de trois opinions distinctes, mais cela montre que cet utilisateur pourrait être en faveur des films de science-fiction et qu’il pourrait y avoir beaucoup d’autres films de science-fiction qu’il aimerait. Contrairement aux films spécifiques, les caractéristiques latentes sont exprimées par des attributs de plus haut niveau, et la catégorie Sci-Fi est l’une des caractéristiques latentes dans ce cas. Ce que la factorisation matricielle nous donne finalement, c’est le degré d’alignement d’un utilisateur sur un ensemble de caractéristiques latentes, et le degré de correspondance d’un film avec cet ensemble de caractéristiques latentes. L’avantage de cette méthode par rapport au voisinage le plus proche standard est que même si deux utilisateurs n’ont pas noté les mêmes films, il est toujours possible de trouver la similarité entre eux s’ils partagent les mêmes goûts sous-jacents, à nouveau des caractéristiques latentes.
Pour voir comment une matrice est factorisée, la première chose à comprendre est la décomposition en valeurs singulières(SVD). Sur la base de l’algèbre linéaire, toute matrice réelle R peut être décomposée en 3 matrices U, Σ et V. En continuant à utiliser l’exemple du film, U est une matrice de caractéristiques latentes utilisateur n × r, V est une matrice de caractéristiques latentes film m × r. Σ est une matrice diagonale r × r contenant les valeurs singulières de la matrice originale, représentant simplement l’importance d’une caractéristique spécifique pour prédire la préférence de l’utilisateur.

Pour trier les valeurs de Σ par valeur absolue décroissante et tronquer la matrice Σ aux k premières dimensions( k valeurs singulières), nous pouvons reconstruire la matrice comme matrice A. La sélection de k doit s’assurer que A est capable de capturer la plupart de la variance dans la matrice originale R, de sorte que A est l’approximation de R, A ≈ R. La différence entre A et R est l’erreur qui est censée être minimisée. C’est exactement la pensée de l’analyse en composantes principales.

Lorsque la matrice R est dense, U et V pourraient être facilement factorisés analytiquement. Cependant, une matrice d’évaluations de films est très éparse. Bien qu’il existe des méthodes d’imputation pour combler les valeurs manquantes, nous nous tournerons vers une approche de programmation pour vivre avec ces valeurs manquantes et trouver les matrices de facteurs U et V. Au lieu de factoriser R via SVD, nous essayons de trouver U et V directement dans le but que lorsque U et V sont multipliés ensemble, la matrice de sortie R’ soit la plus proche approximation de R et non plus une matrice éparse. Cette approximation numérique est généralement obtenue avec la factorisation de matrice non négative pour les systèmes de recommandation puisqu’il n’y a pas de valeurs négatives dans les évaluations.
Voir la formule ci-dessous. En regardant la notation prédite pour un utilisateur et un élément spécifiques, l’élément i est noté comme un vecteur qᵢ, et l’utilisateur u est noté comme un vecteur pᵤ tel que le produit scalaire de ces deux vecteurs est la notation prédite pour l’utilisateur u sur l’élément i. Cette valeur est présentée dans la matrice R’ à la ligne u et à la colonne i.


Comment trouver les qᵢ et pᵤ optimaux ? Comme la plupart des tâches d’apprentissage automatique, une fonction de perte est définie pour minimiser le coût des erreurs.

rᵤᵢ est les vraies évaluations de la matrice originale utilisateur-élément. Le processus d’optimisation consiste à trouver la matrice optimale P composée du vecteur pᵤ et la matrice Q composée du vecteur qᵢ afin de minimiser l’erreur quadratique totale entre les évaluations prédites rᵤᵢ’ et les vraies évaluations rᵤᵢ. De plus, une régularisation L2 a été ajoutée pour empêcher l’ajustement excessif des vecteurs d’utilisateurs et d’éléments. Il est également assez courant d’ajouter un terme de biais qui a généralement 3 composantes principales : note moyenne de tous les éléments μ, note moyenne de l’élément i moins μ(notée bᵤ), note moyenne donnée par l’utilisateur u moins u(notée bᵢ).

Optimisation
Quelques algorithmes d’optimisation ont été populaires pour résoudre la factorisation non négative. La méthode des moindres carrés alternatifs est l’un d’entre eux. Puisque la fonction de perte est non-convexe dans ce cas, il n’y a aucun moyen d’atteindre un minimum global, alors qu’il peut toujours atteindre une grande approximation en trouvant des minimums locaux. La méthode alternative des moindres carrés consiste à maintenir constante la matrice du facteur utilisateur, à ajuster la matrice du facteur élémentaire en prenant les dérivées de la fonction de perte et en la fixant à 0, puis à maintenir constante la matrice du facteur élémentaire tout en ajustant la matrice du facteur utilisateur. Répétez le processus en changeant et en ajustant les matrices dans les deux sens jusqu’à convergence. Si vous appliquez le modèle Scikit-learn NMF, vous verrez que ALS est le solveur par défaut à utiliser, qui est également appelé Coordinate Descent. Pyspark offre également des paquets de décomposition assez soignés qui fournissent plus de flexibilité de réglage de l’ALS lui-même.
Pensées
Le filtrage collaboratif fournit un fort pouvoir prédictif pour les systèmes de recommandation, et nécessite le moins d’informations en même temps. Cependant, il présente quelques limites dans certaines situations particulières.
Premièrement, les goûts sous-jacents exprimés par les caractéristiques latentes ne sont en fait pas interprétables car il n’y a pas de propriétés liées au contenu des métadonnées. Pour un film par exemple, il ne s’agit pas nécessairement d’un genre comme la science-fiction dans mon exemple. Il peut s’agir de la motivation de la bande sonore, de la qualité de l’intrigue, etc. Le filtrage collaboratif manque de transparence et d’explicabilité de ce niveau d’information.
D’autre part, le filtrage collaboratif est confronté au démarrage à froid. Lorsqu’un nouvel élément arrive, jusqu’à ce qu’il doive être évalué par un nombre substantiel d’utilisateurs, le modèle n’est pas en mesure de faire des recommandations personnalisées . De même, pour les éléments de la queue qui n’ont pas obtenu trop de données, le modèle a tendance à leur donner moins de poids et à avoir un biais de popularité en recommandant des éléments plus populaires.
C’est généralement une bonne idée d’avoir des algorithmes d’ensemble pour construire un modèle d’apprentissage automatique plus complet, comme la combinaison du filtrage basé sur le contenu en ajoutant certaines dimensions de mots-clés qui sont explicables, mais nous devrions toujours considérer le compromis entre la complexité du modèle/du calcul et l’efficacité de l’amélioration de la performance.