”Olemme jättämässä tiedon aikakauden ja siirtymässä suositusten aikakauteen.”
Monien koneoppimistekniikoiden tapaan suosittelujärjestelmä tekee ennusteita käyttäjien historiallisen käyttäytymisen perusteella. Tarkemmin sanottuna sen tehtävänä on ennustaa käyttäjän mieltymys joukon kohteita kohtaan aikaisempien kokemusten perusteella. Suosittelujärjestelmän rakentamiseksi kaksi suosituinta lähestymistapaa ovat sisältöpohjainen ja kollaboratiivinen suodatus.
Sisältöpohjainen lähestymistapa vaatii hyvän määrän tietoa kohteiden omista ominaisuuksista sen sijaan, että se käyttäisi käyttäjien vuorovaikutusta ja palautetta. Se voi olla esimerkiksi elokuvan ominaisuuksia, kuten genre, vuosi, ohjaaja, näyttelijä jne., tai artikkelien tekstisisältöä, joka voidaan poimia soveltamalla luonnollisen kielen käsittelyä. Yhteistyösuodatus taas ei tarvitse mitään muuta kuin käyttäjien historialliset mieltymykset kohteiden joukosta. Koska se perustuu historiatietoihin, keskeisenä oletuksena on, että aiemmin samaa mieltä olleet käyttäjät ovat yleensä samaa mieltä myös tulevaisuudessa. Käyttäjien mieltymykset ilmaistaan yleensä kahdella luokalla. Eksplisiittinen luokitus on käyttäjän antama arvosana kohteelle liukuvalla asteikolla, kuten 5 tähteä Titanicille. Tämä on käyttäjien suorinta palautetta siitä, kuinka paljon he pitävät kohteesta. Implisiittinen luokitus, viittaa käyttäjien mieltymyksiin epäsuorasti, kuten sivunäkymiin, klikkauksiin, ostotietueisiin, musiikkikappaleen kuuntelemiseen vai kuuntelematta jättämiseen ja niin edelleen. Tässä artikkelissa tarkastelen tarkemmin yhteistoiminnallista suodatusta, joka on perinteinen ja tehokas työkalu suosittelujärjestelmissä.
Yhteistoiminnallisen suodatuksen vakiomenetelmä tunnetaan nimellä Nearest Neighborhood -algoritmi. On olemassa käyttäjäpohjaista CF:ää ja kohdepohjaista CF:ää. Tarkastellaan ensin käyttäjäpohjaista CF:ää. Meillä on n × m-matriisi luokituksista, jossa on käyttäjä uᵢ, i = 1, …n ja kohde pⱼ, j=1, …m. Nyt haluamme ennustaa arvosanan rᵢⱼ, jos kohdekäyttäjä i ei ole katsonut/arvostellut kohdetta j. Prosessi on laskea samankaltaisuudet kohdekäyttäjän i ja kaikkien muiden käyttäjien välillä, valita X suurinta samankaltaista käyttäjää ja ottaa painotettuna keskiarvona arvosanat näiltä X käyttäjältä, joilla on samankaltaisuudet painoina.


Vaikka eri ihmisillä voi olla erilaiset lähtökohdat arvosanoja antaessaan, joillakin ihmisillä on taipumus antaa yleisesti ottaen korkeita pisteitä, jotkut taas ovat melko tiukkoja, vaikka ovatkin tyytyväisiä kohteisiin. Välttääksemme tämän vääristymän voimme vähentää kunkin käyttäjän kaikkien kohteiden keskimääräisen arvosanan laskettaessa painotettua keskiarvoa ja lisätä sen takaisin kohdekäyttäjälle, mikä näkyy alla.

Kaksi tapaa laskea samankaltaisuus ovat Pearsonin korrelaatio (Pearson Correlation) ja kosinusmainen samanlaisuus (Cosine Similarity).
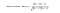

PERUSTIEDOT ideana on löytää kohdekäyttäjän kanssa samankaltaisimmat käyttäjät (lähimmät naapurit) ja painottaa heidän kohteensa arvosanoja kohdekäyttäjän kyseisen kohteen arvosanan ennusteena.
Tietämättä mitään itse kohteista ja käyttäjistä, ajattelemme, että kaksi käyttäjää on samankaltaisia, kun ne antavat samalle kohteelle samankaltaiset arvosanat . Vastaavasti kohdepohjaisessa CF:ssä sanomme, että kaksi kohdetta ovat samankaltaisia, kun ne ovat saaneet samalta käyttäjältä samankaltaiset arvosanat. Tämän jälkeen teemme kohdekäyttäjän kohdetta koskevan ennusteen laskemalla kyseisen käyttäjän X samankaltaisimman kohteen arvosanojen painotetun keskiarvon. Yksi Item-based CF:n tärkeimmistä eduista on vakaus, joka tarkoittaa sitä, että tietyn kohteen arvosanat eivät muutu merkittävästi ajan myötä, toisin kuin ihmisten makutottumukset.

Tässä menetelmässä on melko paljon rajoituksia. Se ei käsittele hyvin harvalukuisuutta, kun kukaan lähipiirissä ei ole arvioinut kohdetta, jota yritetään ennustaa kohdekäyttäjälle. Se ei myöskään ole laskennallisesti tehokas käyttäjien ja tuotteiden määrän kasvaessa.
Matrix Factorization
Koska harvinaisuus ja skaalautuvuus ovat kaksi suurinta haastetta tavalliselle CF-menetelmälle, se tulee kehittyneemmällä menetelmällä, joka hajottaa alkuperäisen harvan matriisin matala-ulotteisiksi matriiseiksi, joissa on latentteja tekijöitä/ominaisuuksia ja vähemmän harvinaisuutta. Kyseessä on matriisifaktorointi.
Harvinaisuuden ja skaalautuvuuden ongelmien ratkaisemisen lisäksi on intuitiivinen selitys sille, miksi tarvitsemme matalaulotteisia matriiseja edustamaan käyttäjien mieltymyksiä. Käyttäjä antoi hyvät arvosanat elokuville Avatar, Gravity ja Inception. Ne eivät välttämättä ole kolme erillistä mielipidettä, vaan osoittavat, että tämä käyttäjä saattaa suosia scifi-elokuvia ja että voi olla paljon muitakin scifi-elokuvia, joista tämä käyttäjä pitäisi. Toisin kuin tietyt elokuvat, latentit ominaisuudet ilmaistaan korkeamman tason ominaisuuksilla, ja Sci-Fi-luokka on tässä tapauksessa yksi latentti ominaisuus. Matriisifaktorointi antaa meille lopulta tulokseksi sen, kuinka paljon käyttäjä on linjassa latenttien piirteiden joukon kanssa ja kuinka paljon elokuva sopii tähän latenttien piirteiden joukkoon. Sen etuna tavalliseen lähimpään naapurustoon verrattuna on se, että vaikka kaksi käyttäjää ei olisikaan arvioinut samoja elokuvia, on silti mahdollista löytää samankaltaisuus heidän väliltään, jos heillä on samankaltainen perimmäinen maku, jälleen latentit piirteet.
Katsoaksemme, miten matriisi faktoroidaan, ensimmäinen asia, joka on ymmärrettävä, on singulaarinen arvojen hajottaminen (SVD). Lineaarialgebran perusteella mikä tahansa reaalimatriisi R voidaan hajottaa kolmeksi matriisiksi U, Σ ja V. Elokuvaesimerkin avulla U on n × r-käyttäjä-latentti ominaisuusmatriisi, V on m × r-elokuva-latentti ominaisuusmatriisi. Σ on r × r -diagonaalimatriisi, joka sisältää alkuperäisen matriisin singulaariarvot ja kuvaa yksinkertaisesti sitä, kuinka tärkeä tietty ominaisuus on käyttäjän mieltymysten ennustamisessa.

Lajitellaksemme Σ:n arvot pienenevän absoluuttisen arvon mukaan ja typistääksemme matriisin Σ ensimmäisiin k ulottuvuuteen( k singulaarista arvoa), voimme rekonstruoida matriisin matriisiksi A. K:n valinnalla on varmistettava, että A pystyy vangitsemaan suurimman osan alkuperäisen matriisin R varianssista, joten A on R:n approksimaatio, A ≈ R. A:n ja R:n välinen erotus on virhe, joka odotetaan minimoitavan. Tämä on juuri periaatekomponenttianalyysin ajatus.

Kun matriisi R on tiheä, U ja V voitaisiin helposti faktoroida analyyttisesti. Elokuva-arvioiden matriisi on kuitenkin erittäin harva. Vaikka on olemassa joitakin imputaatiomenetelmiä puuttuvien arvojen täyttämiseksi , siirrymme ohjelmointimenetelmään, jossa vain elämme näiden puuttuvien arvojen kanssa ja löydämme faktorimatriisit U ja V. Sen sijaan, että faktoroisimme R:n SVD:n avulla, yritämme löytää U:n ja V:n suoraan tavoitteenamme on, että kun U ja V kerrotaan takaisin yhteen, tulostematriisi R’ on lähin approksimaatio R:stä eikä enää harva matriisi. Tämä numeerinen approksimaatio saavutetaan yleensä suosittelujärjestelmissä ei-negatiivisten matriisien faktoroinnilla, koska arvosanoissa ei ole negatiivisia arvoja.
Katso alla olevaa kaavaa. Kun tarkastellaan ennustettua arvosanaa tietylle käyttäjälle ja kohteelle, kohde i merkitään vektoriksi qᵢ ja käyttäjä u merkitään vektoriksi pᵤ siten, että näiden kahden vektorin pistepotentiaali on käyttäjän u ennustettu arvosana kohteelle i. Tämä arvo esitetään matriisissa R’ rivillä u ja sarakkeessa i.


>
>
Miten löydämme optimaaliset qᵢ ja pᵤ? Kuten useimmissa koneoppimistehtävissä, määritellään häviöfunktio virheiden kustannusten minimoimiseksi.

rᵤᵢ on todelliset arvosanat alkuperäisestä käyttäjä-artikkelimatriisista. Optimointiprosessissa etsitään optimaalinen matriisi P, joka muodostuu vektorista pᵤ, ja matriisi Q, joka muodostuu vektorista qᵢ, jotta ennustettujen arvosanojen rᵤᵢ’ ja todellisten arvosanojen rᵤᵢ välinen neliövirheen summa minimoidaan. Lisäksi on lisätty L2-regularisointi käyttäjä- ja kohdevektoreiden liiallisen sovittamisen estämiseksi. On myös varsin tavallista lisätä bias-termi, jolla on yleensä kolme pääkomponenttia: kaikkien kohteiden keskimääräinen luokitus μ, kohteen i keskimääräinen luokitus vähennettynä μ:llä (merkitään nimellä bᵤ), käyttäjän u antama keskimääräinen luokitus vähennettynä u:lla (merkitään nimellä bᵢ).

Optimointi
Ei-negatiivisen kertolaskun ratkaisemiseen on suosittu muutamia optimointialgoritmeja. Vaihtoehtoinen pienin neliö on yksi niistä. Koska häviöfunktio on tässä tapauksessa ei-konveksaalinen, globaalia minimiä ei voida saavuttaa, mutta paikallisia minimejä etsimällä voidaan silti saavuttaa hyvä approksimaatio. Vaihtoehtoisessa pienimmän neliösumman menetelmässä käyttäjätekijämatriisi pidetään vakiona, kohdetekijämatriisia säädetään ottamalla häviöfunktion derivaatta ja asettamalla se 0:ksi ja asetetaan sitten kohdetekijämatriisi vakioksi samalla kun käyttäjätekijämatriisia säädetään. Toista prosessi vaihtamalla ja säätämällä matriiseja edestakaisin, kunnes konvergenssi on saavutettu. Jos käytät Scikit-learn NMF-mallia, näet, että ALS on oletusarvoisesti käytettävä ratkaisija, jota kutsutaan myös nimellä Coordinate Descent. Pyspark tarjoaa myös melko siistejä hajotuspaketteja, jotka tarjoavat enemmän viritysjoustavuutta kuin itse ALS.
Joitakin ajatuksia
Yhteistyösuodatus tarjoaa vahvan ennustuskyvyn suosittelujärjestelmiin ja vaatii samalla vähiten tietoa. Sillä on kuitenkin muutama rajoitus joissakin erityistilanteissa.
Ensiksi, latenttien piirteiden ilmaisemat taustalla olevat makutottumukset eivät itse asiassa ole tulkittavissa, koska metatiedoissa ei ole sisältöön liittyviä ominaisuuksia. Elokuvaesimerkin kohdalla ei välttämättä tarvitse olla genre kuten Sci-Fi esimerkissäni. Se voi olla se, kuinka motivoiva ääniraita on, kuinka hyvä juoni on ja niin edelleen. Yhteistoiminnallisesta suodatuksesta puuttuu tämän tietotason läpinäkyvyys ja selitettävyys.
Toisaalta yhteistoiminnallinen suodatus kohtaa kylmäkäynnistyksen. Kun uusi kohde on tulossa, ennen kuin sen on arvioitava huomattava määrä käyttäjiä, malli ei pysty tekemään mitään henkilökohtaisia suosituksia . Vastaavasti kohteiden hännältä, jotka eivät ole saaneet liikaa dataa, mallilla on taipumus antaa niille vähemmän painoarvoa ja sillä on suosioharha suosittelemalla suositellumpia kohteita.
On yleensä hyvä ajatus käyttää ensemble-algoritmeja kattavamman koneoppimismallin rakentamiseksi, kuten sisältöpohjaisen suodatuksen yhdistäminen lisäämällä joitain avainsanojen ulottuvuuksia, jotka ovat selitettävissä, mutta meidän pitäisi aina harkita kompromissia mallin/laskennallisen monimutkaisuuden ja suorituskyvyn parantamisen tehokkuuden välillä.
Mallin/laskennallisen monimutkaisuuden ja suorituskyvyn parantamisen tehokkuuden välillä.