“Kilépünk az információ korából, és belépünk az ajánlás korába.”
Mint sok gépi tanulási technika, az ajánlórendszer is a felhasználók korábbi viselkedése alapján készít előrejelzést. Pontosabban, a múltbeli tapasztalatok alapján megjósolja a felhasználó preferenciáját egy elemkészletre vonatkozóan. Egy ajánlórendszer létrehozásához a két legnépszerűbb megközelítés a tartalomalapú és a kollaboratív szűrés.
A tartalomalapú megközelítéshez az elemek saját jellemzőiről kellő mennyiségű információra van szükség, nem pedig a felhasználók interakcióira és visszajelzéseire. Ilyen lehet például a filmek attribútumai, mint a műfaj, az év, a rendező, a színész stb. vagy a cikkek szöveges tartalma, amelyet természetes nyelvi feldolgozás alkalmazásával lehet kinyerni. A kollaboratív szűrésnek viszont semmi másra nincs szüksége, csak a felhasználók történelmi preferenciájára egy elemkészletre vonatkozóan. Mivel történeti adatokon alapul, az alapvető feltételezés itt az, hogy azok a felhasználók, akik a múltban egyetértettek, általában a jövőben is egyetértenek. Ami a felhasználói preferenciát illeti, azt általában két kategória fejezi ki. Explicit Rating, a felhasználó által egy elemnek adott értékelés egy csúszó skálán, például 5 csillag a Titanicnak. Ez a felhasználók legközvetlenebb visszajelzése arról, hogy mennyire tetszik nekik egy elem. Implicit értékelés, közvetett módon utal a felhasználók preferenciájára, mint például az oldalmegtekintések, kattintások, vásárlási rekordok, hogy meghallgatnak-e egy zeneszámot vagy sem, és így tovább. Ebben a cikkben közelebbről megvizsgálom a kollaboratív szűrést, amely az ajánlórendszerek hagyományos és hatékony eszköze.
A kollaboratív szűrés standard módszere a Nearest Neighborhood algoritmus néven ismert. Létezik felhasználó alapú CF és elem alapú CF. Nézzük először a felhasználó alapú CF-et. Van egy n × m értékelési mátrixunk, amelyben a felhasználó uᵢ, i = 1, …n és a tétel pⱼ, j=1, …m szerepel. Most meg akarjuk jósolni az rᵢⱼ értékelést, ha az i célfelhasználó nem nézte/értékelte a j elemet. A folyamat a következő: kiszámítjuk az i célfelhasználó és az összes többi felhasználó közötti hasonlóságokat, kiválasztjuk a legjobb X hasonló felhasználót, és súlyként az X hasonló felhasználó értékeléseinek súlyozott átlagát vesszük.


Míg a különböző emberek különböző kiindulási alapokkal rendelkeznek az értékelések adásakor, egyesek általában hajlamosak magas pontszámokat adni, mások elég szigorúak annak ellenére, hogy elégedettek a tételekkel. Ennek a torzításnak az elkerülése érdekében a súlyozott átlag kiszámításakor kivonhatjuk az egyes felhasználók összes elemre vonatkozó átlagos értékelését, és a célfelhasználó esetében visszaadhatjuk, ami az alábbiakban látható.

A hasonlóság kiszámításának két módja a Pearson-korreláció és a koszinusz hasonlóság.
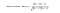

Lényegében, az ötlet lényege, hogy megkeressük a célfelhasználóhoz leginkább hasonló felhasználókat (legközelebbi szomszédok), és egy elem értékelését úgy súlyozzuk, mint a célfelhasználónak az adott elem értékelésének előrejelzését.
Nem tudunk semmit magukról az elemekről és a felhasználókról, úgy gondoljuk, hogy két felhasználó hasonló, ha ugyanazt az elemet hasonlóan értékelik . Analóg módon az elemalapú CF esetében azt mondjuk, hogy két elem hasonló, ha hasonló értékelést kaptak ugyanattól a felhasználótól. Ezután egy célfelhasználóra vonatkozó előrejelzést készítünk egy elemre vonatkozóan azáltal, hogy kiszámítjuk a legtöbb X hasonló elemre vonatkozó értékelések súlyozott átlagát ettől a felhasználótól. Az Item-based CF egyik legfontosabb előnye a stabilitás, ami azt jelenti, hogy egy adott tétel értékelései nem változnak jelentősen az idő múlásával, ellentétben az emberi ízléssel.

Ez a módszer elég sok korlátot tartalmaz. Nem kezeli jól a ritkaságot, amikor a környéken senki sem értékelt olyan elemet, amit a célfelhasználó számára próbál megjósolni. Emellett nem számítási hatékony, mivel a felhasználók és a termékek száma növekszik.
Mátrix-faktorizáció
Mivel a ritkaság és a skálázhatóság a két legnagyobb kihívás a standard CF-módszer számára, jön egy fejlettebb módszer, amely az eredeti ritka mátrixot alacsony dimenziós mátrixokra bontja, látens faktorokkal/jellemzőkkel és kisebb ritkasággal. Ez a mátrix-faktorizáció.
A ritkaság és a skálázhatóság problémáinak megoldása mellett van egy intuitív magyarázat arra, hogy miért van szükségünk alacsony dimenziós mátrixokra a felhasználók preferenciáinak reprezentálásához. Egy felhasználó jó értékelést adott az Avatar, a Gravitáció és az Inception című filmeknek. Ezek nem feltétlenül 3 különálló vélemény, hanem azt mutatják, hogy ez a felhasználó a sci-fi filmek híve lehet, és lehet, hogy még sok olyan sci-fi film van, amit ez a felhasználó szeretne. A konkrét filmekkel ellentétben a látens jellemzőket magasabb szintű attribútumok fejezik ki, és ebben az esetben a Sci-Fi kategória az egyik látens jellemző. A mátrixfaktorizáció végül azt adja meg, hogy egy felhasználó mennyire igazodik a látens jellemzők egy halmazához, és hogy egy film mennyire illik bele ebbe a látens jellemzők halmazába. Ennek előnye a szabványos legközelebbi szomszédsággal szemben az, hogy még ha két felhasználó nem is értékelt azonos filmeket, akkor is meg lehet találni a hasonlóságot közöttük, ha hasonló a mögöttes ízlésük, ismét látens jellemzők.
Hogy lássuk, hogyan faktorizálódik egy mátrix, először a Singular Value Decomposition(SVD) fogalmát kell megérteni. A lineáris algebra alapján bármely valós R mátrix 3 mátrixra bontható: U, Σ és V. Folytatva a filmes példát, U egy n × r felhasználói látens jellemzőmátrix, V egy m × r filmes látens jellemzőmátrix. Σ egy r × r diagonális mátrix, amely az eredeti mátrix szinguláris értékeit tartalmazza, és egyszerűen azt mutatja, hogy egy adott jellemző mennyire fontos a felhasználói preferencia előrejelzésében.

A Σ értékeit csökkenő abszolút érték szerint rendezve és a Σ mátrixot az első k dimenzióra( k szinguláris érték) csonkítva, a mátrixot A mátrixként rekonstruálhatjuk. A k kiválasztásánál ügyelni kell arra, hogy A képes legyen az eredeti R mátrixon belüli variancia nagy részét megragadni, így A az R közelítése, A ≈ R. Az A és az R közötti különbség az a hiba, amelyet minimalizálni kell. Ez pontosan a Principle Component Analysis gondolata.

Ha az R mátrix sűrű, U és V könnyen faktorizálható analitikusan. A filmminősítések mátrixa azonban szuper ritkás. Bár vannak imputációs módszerek a hiányzó értékek kitöltésére , mi egy programozási megközelítéshez fordulunk, hogy csak éljünk ezekkel a hiányzó értékekkel, és megtaláljuk az U és V faktor mátrixokat. Ahelyett, hogy R-t SVD-n keresztül faktorizálnánk, megpróbáljuk közvetlenül megtalálni U-t és V-t azzal a céllal, hogy amikor U-t és V-t visszaszorozzuk, a kimeneti R’ mátrix az R legközelebbi közelítése, és nem többé egy ritka mátrix. Ezt a numerikus közelítést általában a nemnegatív mátrix faktorizálással érjük el az ajánlórendszerek esetében, mivel a minősítésekben nincsenek negatív értékek.
Lásd az alábbi képletet. Az adott felhasználóra és elemre vonatkozó előrejelzett értékelést tekintve az i elemet qᵢ vektorként, az u felhasználót pedig pᵤ vektorként jegyezzük fel úgy, hogy e két vektor szorzata az u felhasználó i elemre vonatkozó előrejelzett értékelése. Ez az érték az R’ mátrixban az u sorban és az i oszlopban szerepel.


Hogyan találjuk meg az optimális qᵢ és pᵤ értékeket? Mint a legtöbb gépi tanulási feladatnál, a hibaköltség minimalizálására veszteségfüggvényt definiálunk.

rᵤᵢ a valódi értékelések az eredeti felhasználó-elem mátrixból. Az optimalizálási folyamat célja a pᵤ vektorból álló P mátrix és a qᵢ vektorból álló Q mátrix megtalálása annak érdekében, hogy minimalizáljuk az rᵤᵢ’ előrejelzett értékelések és a rᵤᵢᵢ valódi értékelések közötti négyzetes hiba összegét. A felhasználói és elemvektorok túlillesztésének megakadályozása érdekében L2 regularizációt is alkalmaztunk. Elég gyakori a torzítás kifejezés hozzáadása is, amelynek általában 3 fő összetevője van: az összes elem átlagos értékelése μ, az i elem átlagos értékelése mínusz μ (bᵤ), az u felhasználó által adott átlagos értékelés mínusz u (bᵢ).

Optimalizálás
A nemnegatív faktorizáció megoldására néhány optimalizációs algoritmus népszerű. Az alternatív legkisebb négyzet az egyik közülük. Mivel a veszteségfüggvény ebben az esetben nem konvex, nem lehet globális minimumot elérni, ugyanakkor a lokális minimumok megtalálásával még mindig nagyszerű közelítést lehet elérni. Az alternatív legkisebb négyzet az, hogy a felhasználói faktor mátrixot állandó értéken tartjuk, az elemtényező mátrixot a veszteségfüggvény deriváltjainak vételével és 0-val való egyenlővé tételével állítjuk be, majd az elemtényező mátrixot állandó értékre állítjuk, miközben a felhasználói faktor mátrixot állítjuk be. Ismételje meg a folyamatot a mátrixok ide-oda váltogatásával és beállításával a konvergenciáig. Ha a Scikit-learn NMF modellt alkalmazza, látni fogja, hogy az ALS az alapértelmezett megoldó, amelyet koordinátaszintű leszállásnak is neveznek. A Pyspark is elég takaros dekompozíciós csomagokat kínál, amely nagyobb hangolási rugalmasságot biztosít magának az ALS-nek.
Egy pár gondolat
A kollaboratív szűrés erős előrejelző erőt biztosít az ajánlórendszerek számára, és ugyanakkor a legkevesebb információt igényli. Néhány különleges helyzetben azonban van néhány korlátja.
Először is, a látens jellemzők által kifejezett mögöttes ízlések valójában nem értelmezhetőek, mivel a metaadatoknak nincsenek tartalmi tulajdonságai. A filmek esetében például nem feltétlenül kell műfajnak lennie, mint a példámban szereplő Sci-Fi. Lehet, hogy mennyire motiváló a filmzene, mennyire jó a cselekmény, és így tovább. A kollaboratív szűrés az információ ezen szintjének átláthatóságának és megmagyarázhatóságának hiánya.
A kollaboratív szűrés viszont hidegindítással szembesül. Amikor egy új elem érkezik, amíg azt jelentős számú felhasználónak kell értékelnie, a modell nem képes személyre szabott ajánlásokat tenni . Hasonlóképpen, a farokelemek esetében, amelyek nem kaptak túl sok adatot, a modell hajlamos kisebb súlyt adni rájuk, és népszerűségi torzítással rendelkezik azáltal, hogy népszerűbb elemeket ajánl.
Az együttes algoritmusok általában jó ötlet egy átfogóbb gépi tanulási modell felépítéséhez, például a tartalomalapú szűrés kombinálásához a magyarázható kulcsszavak néhány dimenziójának hozzáadásával, de mindig figyelembe kell vennünk a modell/számítási komplexitás és a teljesítményjavulás hatékonysága közötti kompromisszumot.
Meg kell fontolnunk a modell/számítási komplexitás és a teljesítményjavulás hatékonysága közötti kompromisszumot.