“Vi forlader informationsalderen og går ind i anbefalingernes tidsalder.”
Som mange andre maskinlæringsteknikker forudsiger et anbefalingssystem brugernes historiske adfærd. Specifikt er det at forudsige brugernes præferencer for et sæt af varer baseret på tidligere erfaringer. For at opbygge et anbefalingssystem er de to mest populære tilgange indholdsbaserede og kollaborativ filtrering.
Indholdsbaseret tilgang kræver en god mængde oplysninger om varernes egne egenskaber i stedet for at bruge brugernes interaktioner og tilbagemeldinger. Det kan f.eks. være filmattributter som genre, årstal, instruktør, skuespiller osv. eller tekstindholdet i artikler, der kan udtrækkes ved at anvende Natural Language Processing. Collaborative Filtering har på den anden side ikke brug for andet end brugernes historiske præferencer for et sæt af artikler. Fordi det er baseret på historiske data, er den centrale antagelse her, at de brugere, der har været enige tidligere, har en tendens til også at være enige i fremtiden. Med hensyn til brugerpræferencer udtrykkes det normalt ved hjælp af to kategorier. Eksplicit rating, er en vurdering, som en bruger giver et emne på en glidende skala, som f.eks. 5 stjerner for Titanic. Dette er den mest direkte feedback fra brugerne for at vise, hvor meget de kan lide en vare. Implicit Rating antyder indirekte brugernes præferencer, f.eks. sidevisninger, klik, købsposter, om man lytter til et musiknummer eller ej osv. I denne artikel vil jeg se nærmere på collaborative filtering, som er et traditionelt og kraftfuldt værktøj til anbefalingssystemer.
Standardmetoden for Collaborative Filtering er kendt som Nearest Neighborhood-algoritmen. Der er brugerbaseret CF og elementbaseret CF. Lad os først se på brugerbaseret CF. Vi har en n × m matrix af vurderinger med brugeren uᵢ, i = 1, …n og elementet pⱼ, j=1, …m. Nu ønsker vi at forudsige bedømmelsen rᵢⱼ, hvis målbrugeren i ikke har set/bedømt et element j. Processen består i at beregne lighederne mellem målbrugeren i og alle andre brugere, udvælge de X bedste lignende brugere og tage det vægtede gennemsnit af bedømmelserne fra disse X brugere med ligheder som vægte.


Mens forskellige mennesker kan have forskellige udgangspunkter, når de giver vurderinger, nogle mennesker har en tendens til at give høje karakterer generelt, andre er ret strenge, selv om de er tilfredse med emnerne. For at undgå denne skævhed kan vi trække hver brugers gennemsnitlige bedømmelse af alle elementer fra, når vi beregner det vægtede gennemsnit, og tilføje det igen for målbrugeren, vist som nedenfor.

To måder at beregne lighed på er Pearsonkorrelation og cosinuslignende lighed.
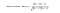

Grundende, idéen er at finde de brugere, der ligner din målbruger mest (nærmeste naboer), og vægte deres vurderinger af et emne som en forudsigelse af målbrugerens vurdering af dette emne.
Og uden at vide noget om emner og brugere selv, mener vi, at to brugere ligner hinanden, når de giver det samme emne lignende vurderinger . Tilsvarende siger vi for Item-baseret CF, at to elementer ligner hinanden, når de har modtaget lignende vurderinger fra den samme bruger. Derefter foretager vi en forudsigelse for en målbruger om et emne ved at beregne det vægtede gennemsnit af vurderinger af de mest X lignende emner fra denne bruger. En vigtig fordel ved Item-baseret CF er stabiliteten, som består i, at vurderingerne af en given vare ikke ændrer sig væsentligt med tiden, i modsætning til menneskers smag.

Der er en hel del begrænsninger ved denne metode. Den håndterer ikke sparsomhed godt, når ingen i nabolaget har vurderet et emne, som er det, man forsøger at forudsige for målbrugeren. Den er heller ikke beregningseffektiv som væksten af antallet af brugere og produkter.
Matrix Factorization
Da sparsomhed og skalerbarhed er de to største udfordringer for standard CF-metoden, kommer der en mere avanceret metode, der dekomponerer den oprindelige sparsomme matrix til lavdimensionelle matricer med latente faktorer/karakteristika og mindre sparsomhed. Det er Matrix Factorization.
Suden at løse problemerne med sparsomhed og skalerbarhed er der en intuitiv forklaring på, hvorfor vi har brug for lavdimensionelle matricer til at repræsentere brugernes præferencer. En bruger gav gode vurderinger til filmen Avatar, Gravity og Inception. Det er ikke nødvendigvis 3 forskellige meninger, men viser, at denne bruger måske er tilhængere af sci-fi-film, og der kan være mange flere sci-fi-film, som denne bruger kunne lide. I modsætning til specifikke film udtrykkes latente egenskaber ved hjælp af attributter på højere niveau, og Sci-Fi-kategorien er en af de latente egenskaber i dette tilfælde. Det, som matrixfaktorisering i sidste ende giver os, er, hvor meget en bruger er på linje med et sæt af latente egenskaber, og hvor meget en film passer ind i dette sæt af latente egenskaber. Fordelen ved det i forhold til standard nærmest naboskab er, at selv om to brugere ikke har vurderet de samme film, er det stadig muligt at finde ligheden mellem dem, hvis de deler den samme underliggende smag, igen latente funktioner.
For at se, hvordan en matrix bliver faktoriseret, er den første ting at forstå Singular Value Decomposition (SVD). Baseret på lineær algebra kan enhver reel matrix R dekomponeres i 3 matricer U, Σ og V. Hvis vi fortsætter med at bruge filmeksemplet, er U en n × r bruger-latent egenskabs-matrix, V er en m × r film-latent egenskabs-matrix. Σ er en r × r diagonal matrix, der indeholder de singulære værdier af den oprindelige matrix, og som simpelthen repræsenterer, hvor vigtig en bestemt funktion er for at forudsige brugerpræferencer.

For at sortere værdierne i Σ efter faldende absolut værdi og afkortet matrix Σ til de første k dimensioner( k singulære værdier), kan vi rekonstruere matrixen som matrix A. Valget af k skal sikre, at A er i stand til at fange størstedelen af variansen inden for den oprindelige matrix R, således at A er en tilnærmelse af R, A ≈ R. Forskellen mellem A og R er den fejl, der forventes at blive minimeret. Dette er præcis tanken bag Principle Component Analysis.

Når matrix R er tæt, vil U og V let kunne faktoriseres analytisk. En matrix af filmvurderinger er imidlertid super sparsom. Selv om der findes nogle imputeringsmetoder til at udfylde manglende værdier , vil vi anvende en programmeringsmetode til at leve med de manglende værdier og finde faktormatricerne U og V. I stedet for at faktorisere R via SVD forsøger vi at finde U og V direkte med det mål, at når U og V ganges sammen igen, er udgangsmatricen R’ den nærmeste tilnærmelse af R og ikke længere en sparsom matrix. Denne numeriske tilnærmelse opnås normalt med Non-Negative Matrix Factorization til anbefalingssystemer, da der ikke er negative værdier i vurderinger.
Se nedenstående formel. Hvis man ser på den forudsagte bedømmelse for en bestemt bruger og genstand, noteres genstand i som en vektor qᵢ, og bruger u noteres som en vektor pᵤ, således at prikproduktet af disse to vektorer er den forudsagte bedømmelse for bruger u på genstand i. Denne værdi præsenteres i matrixen R’ i række u og kolonne i.


Hvordan finder vi optimale qᵢ og pᵤ? Som de fleste maskinlæringsopgaver defineres en tabsfunktion for at minimere omkostningerne ved fejl.

rᵤᵢ er de sande bedømmelser fra den oprindelige bruger-emne-matrix. Optimeringsprocessen går ud på at finde den optimale matrix P bestående af vektor pᵤ og matrix Q bestående af vektor qᵢ for at minimere den samlede kvadratfejl mellem de forudsagte bedømmelser rᵤᵢ’ og de sande bedømmelser rᵤᵢ. Der er også tilføjet L2-regularisering for at forhindre overtilpasning af bruger- og emnevektorer. Det er også ret almindeligt at tilføje bias-udtryk, som normalt har 3 hovedkomponenter: gennemsnitlig bedømmelse af alle elementer μ, gennemsnitlig bedømmelse af element i minus μ(noteret som bᵤ), gennemsnitlig bedømmelse givet af brugeren u minus u(noteret som bᵢ).

Optimering
Et par optimeringsalgoritmer har været populære til at løse Non-Negative Factorization. Alternative Least Square er en af dem. Da tabsfunktionen er ikke-konveks i dette tilfælde, er der ingen mulighed for at nå et globalt minimum, mens den stadig kan nå en stor tilnærmelse ved at finde lokale minima. Alternative Least Square består i at holde brugerfaktormatricen konstant, justere elementfaktormatricen ved at tage derivater af tabsfunktionen og sætte den lig med 0, og derefter sætte elementfaktormatricen konstant, mens man justerer brugerfaktormatricen. Gentag processen ved at skifte og justere matricerne frem og tilbage, indtil der er konvergens. Hvis du anvender Scikit-learn NMF-modellen, vil du se, at ALS er standardløseren, som også kaldes Coordinate Descent (koordinatafstigning). Pyspark tilbyder også ret pæne dekompositionspakker, der giver mere tuning fleksibilitet af ALS selv.
Nogle tanker
Collaborative Filtering giver en stærk forudsigelseskraft til anbefalingssystemer og kræver samtidig de færreste oplysninger. Det har dog et par begrænsninger i nogle særlige situationer.
For det første kan de underliggende smagspunkter, der udtrykkes af latente egenskaber, faktisk ikke fortolkes, fordi der ikke er indholdsrelaterede egenskaber ved metadata. For film eksempel, det behøver ikke nødvendigvis at være genre som Sci-Fi i mit eksempel. Det kan være, hvor motiverende soundtracket er, hvor godt plottet er osv. Collaborative Filtering er mangel på gennemsigtighed og forklarbarhed af dette informationsniveau.
På den anden side står Collaborative Filtering over for koldstart. Når et nyt emne kommer ind, indtil det skal vurderes af et betydeligt antal brugere, er modellen ikke i stand til at lave nogen personlige anbefalinger . Tilsvarende, for elementer fra halen, der ikke fik for mange data, har modellen tendens til at give mindre vægt på dem og har popularitetsbias ved at anbefale mere populære elementer.
Det er normalt en god idé at have ensemblealgoritmer til at opbygge en mere omfattende maskinlæringsmodel som f.eks. at kombinere indholdsbaseret filtrering ved at tilføje nogle dimensioner af nøgleord, der kan forklares, men vi bør altid overveje afvejningen mellem model/computerkompleksitet og effektiviteten af ydelsesforbedring.