”Vi lämnar informationens tidsålder och går in i rekommendationernas tidsålder.”
Som många tekniker för maskininlärning gör ett rekommendationssystem förutsägelser baserade på användarnas tidigare beteenden. Specifikt handlar det om att förutsäga användarens preferenser för en uppsättning objekt baserat på tidigare erfarenheter. De två mest populära metoderna för att bygga ett rekommendationssystem är innehållsbaserad och kollaborativ filtrering.
Innehållsbaserad metod kräver en god mängd information om artiklarnas egna egenskaper, snarare än att använda användarnas interaktioner och återkopplingar. Det kan till exempel vara filmattribut som genre, årtal, regissör, skådespelare osv. eller textuellt innehåll i artiklar som kan extraheras med hjälp av Natural Language Processing. Collaborative Filtering behöver å andra sidan inget annat än användarnas historiska preferenser för en uppsättning artiklar. Eftersom det bygger på historiska data är det centrala antagandet här att de användare som tidigare har varit överens tenderar att också vara överens i framtiden. När det gäller användarnas preferenser brukar de uttryckas i två kategorier. Explicit betygsättning, är ett betyg som en användare ger ett objekt på en glidande skala, t.ex. 5 stjärnor för Titanic. Detta är den mest direkta feedbacken från användarna för att visa hur mycket de tycker om ett objekt. Implicit betygsättning: Användarnas preferenser anges indirekt, t.ex. genom sidvisningar, klick, köp, om man lyssnar på ett musikstycke eller inte, och så vidare. I den här artikeln kommer jag att titta närmare på kollaborativ filtrering som är ett traditionellt och kraftfullt verktyg för rekommendationssystem.
Standardmetoden för kollaborativ filtrering är känd som Nearest Neighborhood-algoritmen. Det finns användarbaserad CF och objektsbaserad CF. Låt oss först titta på användarbaserad CF. Vi har en n × m matris av betyg, med användaren uᵢ, i = 1, …n och objektet pⱼ, j=1, …m. Nu vill vi förutsäga betyget rᵢⱼ om målanvändaren i inte har tittat på/betygsatt objektet j. Processen går ut på att beräkna likheterna mellan målanvändaren i och alla andra användare, välja ut de X mest likartade användarna och ta det vägda genomsnittet av betygen från dessa X användare med likheterna som vikter.


Och olika människor kan ha olika utgångspunkter när de ger betyg, vissa människor tenderar att ge höga betyg generellt, andra är ganska stränga även om de är nöjda med artiklarna. För att undvika denna bias kan vi subtrahera varje användares genomsnittliga betyg för alla objekt när vi beräknar det vägda genomsnittet och lägga till det igen för målanvändaren, vilket visas nedan.

Två sätt att beräkna likhet är Pearsons korrelation och Cosinus likhet.
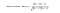

Grundläggande, tanken är att hitta de användare som är mest lika målanvändaren (närmaste grannar) och vikta deras betyg på ett objekt som en förutsägelse av målanvändarens betyg på detta objekt.
Och utan att veta något om objekt och användare tror vi att två användare är lika varandra när de ger samma objekt liknande betyg . På motsvarande sätt säger vi för artikelbaserad CF att två artiklar är likartade när de har fått liknande betyg av samma användare. Därefter gör vi en förutsägelse för en målanvändare om ett objekt genom att beräkna det vägda genomsnittet av betyg på de X mest likartade objekten från denna användare. En viktig fördel med artikelbaserad CF är stabiliteten, vilket innebär att betygsättningen av en viss artikel inte kommer att förändras avsevärt med tiden, till skillnad från människans smak.

Det finns en hel del begränsningar med denna metod. Den hanterar inte sparsamhet bra när ingen i grannskapet har betygsatt ett objekt som är det du försöker förutsäga för målanvändaren. Dessutom är den inte beräkningseffektiv som tillväxten av antalet användare och produkter.
Matrix Factorization
Med tanke på att gleshet och skalbarhet är de två största utmaningarna för standard CF-metoden, kommer det en mer avancerad metod som dekomponerar den ursprungliga glesa matrisen till lågdimensionella matriser med latenta faktorer/egenskaper och mindre gleshet. Det är Matrix Factorization.
Förutom att lösa problemen med sparsamhet och skalbarhet finns det en intuitiv förklaring till varför vi behöver lågdimensionella matriser för att representera användarnas preferenser. En användare gav bra betyg till filmerna Avatar, Gravity och Inception. Det är inte nödvändigtvis tre separata åsikter, men de visar att denna användare kanske föredrar sci-fi-filmer och att det kan finnas många fler sci-fi-filmer som denne användare skulle gilla. Till skillnad från specifika filmer uttrycks latenta egenskaper av attribut på högre nivå, och Sci-Fi-kategorin är en av de latenta egenskaperna i det här fallet. Det som matrisfaktorisering slutligen ger oss är hur mycket en användare är anpassad till en uppsättning latenta egenskaper och hur mycket en film passar in i denna uppsättning latenta egenskaper. Fördelen med den jämfört med standardiserade närmsta grannskap är att även om två användare inte har betygsatt samma filmer, är det fortfarande möjligt att hitta likheten mellan dem om de har samma underliggande smak, återigen latenta egenskaper.
För att se hur en matris faktoriseras, är det första man måste förstå Singular Value Decomposition (SVD). Baserat på linjär algebra kan alla verkliga matriser R dekomponeras i tre matriser U, Σ och V. Om vi fortsätter att använda filmexemplet är U en n × r matris för latenta egenskaper hos användaren och V en m × r matris för latenta egenskaper hos filmen. Σ är en r × r diagonalmatris som innehåller originalmatrisens singulära värden och som helt enkelt representerar hur viktig en viss funktion är för att förutsäga användarens preferenser.

För att sortera värdena i Σ efter minskande absolut värde och förkorta matrisen Σ till de första k dimensionerna( k singulära värden) kan vi rekonstruera matrisen som matris A. Valet av k bör se till att A kan fånga upp största delen av variansen inom den ursprungliga matrisen R, så att A är en approximation av R, A ≈ R. Skillnaden mellan A och R är det fel som förväntas minimeras. Detta är exakt tanken med Principle Component Analysis.

När matrisen R är tät kan U och V lätt faktoriseras analytiskt. En matris med filmbetyg är dock supertät. Även om det finns vissa imputeringsmetoder för att fylla i saknade värden kommer vi att använda oss av en programmeringsmetod för att leva med de saknade värdena och hitta faktormatriserna U och V. Istället för att faktorisera R via SVD försöker vi hitta U och V direkt med målet att när U och V multipliceras tillbaka till varandra är utgångsmatrisen R’ den närmaste approximationen av R och inte längre en sparsam matris. Denna numeriska approximation uppnås vanligtvis med Non-Negative Matrix Factorization för rekommendationssystem eftersom det inte finns några negativa värden i betyg.
Se formeln nedan. Om man tittar på det förutspådda betyget för en specifik användare och ett specifikt objekt, noteras objekt i som en vektor qᵢ, och användare u noteras som en vektor pᵤ så att punktprodukten av dessa två vektorer är det förutspådda betyget för användare u på objekt i. Detta värde presenteras i matrisen R’ i raden u och kolumnen i.


Hur hittar vi de optimala qᵢ och pᵤ? Liksom de flesta maskininlärningsuppgifter definieras en förlustfunktion för att minimera felkostnaden.

rᵤᵢ är de verkliga betygssiffrorna från den ursprungliga matrisen för användares och föremål. Optimeringsprocessen går ut på att hitta den optimala matrisen P som består av vektorn pᵤ och matrisen Q som består av vektorn qᵢ för att minimera summakvadratfelet mellan de förutsagda värderingarna rᵤᵢ’ och de sanna värderingarna rᵤᵢ. Dessutom har L2-regularisering lagts till för att förhindra överanpassning av användar- och artikelvektorer. Det är också ganska vanligt att lägga till termen bias som vanligtvis har tre huvudkomponenter: genomsnittligt betyg för alla objekt μ, genomsnittligt betyg för objekt i minus μ(noteras som bᵤ), genomsnittligt betyg som ges av användaren u minus u(noteras som bᵢ).

Optimering
Ett par optimeringsalgoritmer har varit populära för att lösa icke-negativ faktorisering. Alternative Least Square är en av dem. Eftersom förlustfunktionen är icke-konvex i det här fallet finns det inget sätt att nå ett globalt minimum, medan den ändå kan nå en bra approximation genom att hitta lokala minima. Alternative Least Square är att hålla användarfaktormatrisen konstant, justera artikelfaktormatrisen genom att ta derivat av förlustfunktionen och sätta den lika med 0, och sedan sätta artikelfaktormatrisen konstant samtidigt som man justerar användarfaktormatrisen. Upprepa processen genom att växla och justera matriserna fram och tillbaka tills konvergens uppnås. Om du tillämpar Scikit-learn NMF-modellen kommer du att se att ALS är den standardlösare som används, vilket också kallas Coordinate Descent. Pyspark erbjuder också ganska snygga dekompositionspaket som ger mer inställningsflexibilitet för ALS själv.
Några tankar
Collaborative Filtering ger en stark prediktiv förmåga för rekommendationssystem, och kräver samtidigt minst information. Det har dock några begränsningar i vissa speciella situationer.
För det första är de underliggande smaker som uttrycks av latenta egenskaper faktiskt inte tolkningsbara eftersom det inte finns några innehållsrelaterade egenskaper hos metadata. För film exempel behöver det inte nödvändigtvis vara genre som Sci-Fi i mitt exempel. Det kan vara hur motiverande soundtracket är, hur bra handlingen är och så vidare. Collaborative Filtering saknar transparens och förklarbarhet för denna informationsnivå.
Å andra sidan står Collaborative Filtering inför en kallstart. När ett nytt objekt kommer in, tills det måste betygsättas av ett betydande antal användare, kan modellen inte göra några personliga rekommendationer . På samma sätt tenderar modellen att ge mindre vikt åt objekt från svansen som inte fick så mycket data och har en popularitetsbias genom att rekommendera mer populära objekt.
Det är vanligtvis en bra idé att ha ensemblealgoritmer för att bygga en mer omfattande maskininlärningsmodell, t.ex. genom att kombinera innehållsbaserad filtrering genom att lägga till vissa dimensioner av nyckelord som kan förklaras, men vi bör alltid överväga avvägningen mellan modellens/beräkningskomplexitet och effektiviteten i prestandaförbättringarna.