«Estamos dejando la era de la información y entrando en la era de la recomendación»
Al igual que muchas técnicas de aprendizaje automático, un sistema de recomendación hace predicciones basadas en los comportamientos históricos de los usuarios. En concreto, se trata de predecir la preferencia del usuario por un conjunto de artículos basándose en la experiencia pasada. Para construir un sistema de recomendación, los dos enfoques más populares son el basado en el contenido y el filtrado colaborativo.
El enfoque basado en el contenido requiere una buena cantidad de información de las características propias de los artículos, en lugar de utilizar las interacciones y los comentarios de los usuarios. Por ejemplo, pueden ser atributos de las películas como el género, el año, el director, el actor, etc., o el contenido textual de los artículos que puede extraerse aplicando el Procesamiento del Lenguaje Natural. El filtrado colaborativo, en cambio, no necesita nada más que la preferencia histórica de los usuarios sobre un conjunto de artículos. Dado que se basa en datos históricos, la suposición principal es que los usuarios que han estado de acuerdo en el pasado tienden a estarlo también en el futuro. En cuanto a la preferencia de los usuarios, suele expresarse mediante dos categorías. Calificación explícita, es la puntuación que da un usuario a un artículo en una escala móvil, como 5 estrellas para Titanic. Es la respuesta más directa de los usuarios para mostrar cuánto les gusta un artículo. La Calificación Implícita, sugiere la preferencia de los usuarios de forma indirecta, como las visitas a la página, los clics, los registros de compra, la escucha o no de una pista musical, etc. En este artículo, echaré un vistazo al filtrado colaborativo que es una herramienta tradicional y poderosa para los sistemas de recomendación.
El método estándar de filtrado colaborativo se conoce como algoritmo de vecindad más cercana. Hay CF basado en el usuario y CF basado en el ítem. Veamos primero el CF basado en el usuario. Tenemos una matriz n × m de valoraciones, con el usuario uᵢ, i = 1, …n y el elemento pⱼ, j=1, …m. Ahora queremos predecir la calificación rᵢⱼ si el usuario objetivo i no vio/calificó un artículo j. El proceso consiste en calcular las similitudes entre el usuario objetivo i y todos los demás usuarios, seleccionar los X usuarios más similares y tomar la media ponderada de las calificaciones de estos X usuarios con similitudes como pesos.


Mientras que diferentes personas pueden tener diferentes líneas de base a la hora de dar valoraciones, algunas personas tienden a dar puntuaciones altas en general, otras son bastante estrictas aunque estén satisfechas con los artículos. Para evitar este sesgo, podemos restar la valoración media de cada usuario de todos los artículos al calcular la media ponderada, y volver a sumarla para el usuario objetivo, como se muestra a continuación.

Dos formas de calcular la similitud son la correlación de Pearson y la similitud del coseno.
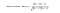

Básicamente, la idea es encontrar los usuarios más parecidos a tu usuario objetivo (vecinos más cercanos) y ponderar sus valoraciones de un artículo como la predicción de la valoración de este artículo para el usuario objetivo.
Sin saber nada sobre los artículos y los propios usuarios, pensamos que dos usuarios son similares cuando dan al mismo artículo valoraciones similares . De forma análoga, para el CF basado en artículos, decimos que dos artículos son similares cuando han recibido valoraciones similares de un mismo usuario. Entonces, haremos una predicción para un usuario objetivo sobre un artículo calculando la media ponderada de las valoraciones de la mayoría de los X artículos similares de este usuario. Una de las principales ventajas de la CF basada en artículos es la estabilidad, es decir, que las valoraciones de un artículo determinado no cambiarán significativamente con el tiempo, a diferencia de los gustos de los seres humanos.

Este método tiene bastantes limitaciones. No maneja bien la escasez cuando nadie en el vecindario calificó un artículo que es lo que se está tratando de predecir para el usuario objetivo. Además, no es eficiente desde el punto de vista computacional a medida que crece el número de usuarios y productos.
Factorización matricial
Dado que la escasez y la escalabilidad son los dos mayores desafíos para el método estándar de CF, surge un método más avanzado que descompone la matriz escasa original en matrices de baja dimensión con factores/características latentes y menos escasez. Esto es la Factorización Matricial.
Además de resolver los problemas de escasez y escalabilidad, hay una explicación intuitiva de por qué necesitamos matrices de baja dimensión para representar las preferencias de los usuarios. Un usuario dio buenas calificaciones a la película Avatar, Gravity e Inception. No son necesariamente 3 opiniones distintas, sino que muestran que este usuario podría estar a favor de las películas de ciencia ficción y que puede haber muchas más películas de ciencia ficción que le gusten a este usuario. A diferencia de las películas específicas, las características latentes se expresan mediante atributos de nivel superior, y la categoría de ciencia ficción es una de las características latentes en este caso. Lo que la factorización matricial nos proporciona finalmente es en qué medida un usuario está alineado con un conjunto de características latentes, y en qué medida una película encaja en este conjunto de características latentes. La ventaja de la factorización matricial sobre el vecindario más cercano es que, aunque dos usuarios no hayan valorado las mismas películas, es posible encontrar la similitud entre ellos si comparten los mismos gustos subyacentes, de nuevo características latentes.
Para ver cómo se factoriza una matriz, lo primero que hay que entender es la descomposición del valor singular (SVD). Basándose en el álgebra lineal, cualquier matriz real R puede descomponerse en 3 matrices U, Σ y V. Siguiendo con el ejemplo de la película, U es una matriz de características latentes de usuario n × r, V es una matriz de características latentes de película m × r. Σ es una matriz diagonal r × r que contiene los valores singulares de la matriz original, y que representa simplemente la importancia de una característica específica para predecir la preferencia del usuario.

Para ordenar los valores de Σ por valor absoluto decreciente y truncar la matriz Σ a las primeras k dimensiones( k valores singulares), podemos reconstruir la matriz como matriz A. La selección de k debe asegurar que A es capaz de capturar la mayor parte de la varianza dentro de la matriz original R, de modo que A es la aproximación de R, A ≈ R. La diferencia entre A y R es el error que se espera minimizar. Este es exactamente el pensamiento del Análisis de Componentes Principales.

Cuando la matriz R es densa, U y V podrían ser fácilmente factorizados analíticamente. Sin embargo, una matriz de valoraciones de películas es superdensa. Aunque hay algunos métodos de imputación para rellenar los valores que faltan, vamos a recurrir a un enfoque de programación para vivir con esos valores que faltan y encontrar las matrices factoriales U y V. En lugar de factorizar R a través de la SVD, estamos tratando de encontrar U y V directamente con el objetivo de que cuando U y V se multipliquen de nuevo juntos la matriz de salida R’ sea la aproximación más cercana a R y deje de ser una matriz dispersa. Esta aproximación numérica se consigue normalmente con la Factorización Matricial No Negativa para los sistemas de recomendación, ya que no hay valores negativos en las valoraciones.
Véase la fórmula siguiente. Observando la calificación predicha para un usuario y un artículo específicos, el artículo i se anota como un vector qᵢ, y el usuario u se anota como un vector pᵤ tal que el producto punto de estos dos vectores es la calificación predicha para el usuario u en el artículo i. Este valor se presenta en la matriz R’ en la fila u y la columna i.


¿Cómo encontramos los valores óptimos qᵢ y pᵤ? Como en la mayoría de las tareas de aprendizaje automático, se define una función de pérdida para minimizar el coste de los errores.

rᵤᵢ es la calificación real de la matriz original de elementos de usuario. El proceso de optimización consiste en encontrar la matriz óptima P, compuesta por el vector pᵤ, y la matriz Q, compuesta por el vector qᵢ, para minimizar el error cuadrático de la suma entre las valoraciones predichas rᵤᵢ’ y las valoraciones reales rᵤᵢ. Además, se ha añadido una regularización L2 para evitar el sobreajuste de los vectores de usuarios e ítems. También es bastante común añadir el término de sesgo que suele tener 3 componentes principales: la calificación media de todos los artículos μ, la calificación media del artículo i menos μ(anotada como bᵤ), la calificación media dada por el usuario u menos u(anotada como bᵢ).

Optimización
Unos pocos algoritmos de optimización han sido populares para resolver la Factorización No Negativa. El Mínimo Cuadrado Alternativo es uno de ellos. Dado que la función de pérdida no es convexa en este caso, no hay manera de alcanzar un mínimo global, mientras que todavía puede alcanzar una gran aproximación mediante la búsqueda de mínimos locales. La alternativa de mínimos cuadrados consiste en mantener constante la matriz del factor de usuario, ajustar la matriz del factor de posición tomando las derivadas de la función de pérdida y estableciéndola igual a 0, y luego establecer la matriz del factor de posición constante mientras se ajusta la matriz del factor de usuario. Repita el proceso cambiando y ajustando las matrices una y otra vez hasta la convergencia. Si aplicas el modelo NMF de Scikit-learn, verás que ALS es el solucionador por defecto a utilizar, que también se llama Descenso por Coordenadas. Pyspark también ofrece paquetes de descomposición bastante limpios que proporcionan más flexibilidad de ajuste del propio ALS.
Algunas reflexiones
El filtrado colaborativo proporciona un fuerte poder predictivo para los sistemas de recomendación, y requiere la menor información al mismo tiempo. Sin embargo, tiene algunas limitaciones en algunas situaciones particulares.
En primer lugar, los gustos subyacentes expresados por las características latentes no son realmente interpretables porque no hay propiedades relacionadas con el contenido de los metadatos. Para el ejemplo de la película, no tiene que ser necesariamente el género como la ciencia ficción en mi ejemplo. Puede ser lo motivadora que es la banda sonora, lo buena que es la trama, etc. Filtrado de colaboración es la falta de transparencia y explicabilidad de este nivel de información.
Por otra parte, el filtrado de colaboración se enfrenta con el arranque en frío. Cuando llega un nuevo artículo, hasta que no tiene que ser valorado por un número considerable de usuarios, el modelo no es capaz de hacer ninguna recomendación personalizada . Del mismo modo, para los artículos de la cola que no obtuvieron demasiados datos, el modelo tiende a dar menos peso sobre ellos y a tener un sesgo de popularidad recomendando artículos más populares.
Por lo general, es una buena idea tener algoritmos de conjunto para construir un modelo de aprendizaje automático más completo, como la combinación de filtrado basado en el contenido mediante la adición de algunas dimensiones de palabras clave que son explicables, pero siempre debemos considerar el compromiso entre la complejidad del modelo/computacional y la eficacia de la mejora del rendimiento.