„Părăsim era informației și intrăm în era recomandării.”
Ca multe tehnici de învățare automată, un sistem de recomandare face predicții pe baza comportamentelor istorice ale utilizatorilor. Mai exact, este de a prezice preferințele utilizatorilor pentru un set de articole pe baza experienței anterioare. Pentru a construi un sistem de recomandare, cele mai populare două abordări sunt cea bazată pe conținut și cea bazată pe filtrare colaborativă.
Abordarea bazată pe conținut necesită o cantitate bună de informații despre caracteristicile proprii ale elementelor, mai degrabă decât utilizarea interacțiunilor și feedback-urilor utilizatorilor. De exemplu, pot fi atributele filmelor, cum ar fi genul, anul, regizorul, actorul etc., sau conținutul textual al articolelor care poate fi extras prin aplicarea Procesării limbajului natural. Pe de altă parte, filtrarea colaborativă nu are nevoie de nimic altceva în afară de preferințele istorice ale utilizatorilor pentru un set de articole. Deoarece se bazează pe date istorice, ipoteza de bază în acest caz este că utilizatorii care au fost de acord în trecut tind să fie de acord și în viitor. În ceea ce privește preferințele utilizatorilor, acestea se exprimă de obicei prin două categorii. Evaluarea explicită, este o notă acordată de un utilizator unui element pe o scară variabilă, cum ar fi 5 stele pentru Titanic. Acesta este cel mai direct feedback din partea utilizatorilor pentru a arăta cât de mult le place un element. Evaluarea implicită sugerează preferințele utilizatorilor în mod indirect, cum ar fi vizualizările de pagini, clicurile, înregistrările de achiziții, dacă ascultă sau nu o piesă muzicală și așa mai departe. În acest articol, voi examina îndeaproape filtrarea colaborativă care este un instrument tradițional și puternic pentru sistemele de recomandare.
Metoda standard de filtrare colaborativă este cunoscută sub numele de algoritmul Nearest Neighborhood. Există CF bazat pe utilizator și CF bazat pe element. Să ne uităm mai întâi la CF bazat pe utilizator. Avem o matrice n × m de evaluări, cu utilizatorul uᵢ, i = 1, …n și elementul pⱼ, j=1, …m. Acum dorim să prezicem ratingul rᵢⱼ în cazul în care utilizatorul țintă i nu a urmărit/notat un element j. Procesul constă în calcularea similitudinilor dintre utilizatorul țintă i și toți ceilalți utilizatori, selectarea primilor X utilizatori similari și calcularea mediei ponderate a ratingurilor de la acești X utilizatori cu similitudini ca ponderi.


În timp ce diferite persoane pot avea puncte de referință diferite atunci când acordă evaluări, unele persoane au tendința de a acorda note mari în general, altele sunt destul de stricte, chiar dacă sunt mulțumite de articole. Pentru a evita această prejudecată, putem scădea ratingul mediu al fiecărui utilizator pentru toate elementele atunci când calculăm media ponderată și îl putem adăuga înapoi pentru utilizatorul țintă, așa cum se arată mai jos.

Două modalități de a calcula similaritatea sunt corelația Pearson și similaritatea cosinus.
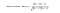

În principiu, ideea este de a găsi utilizatorii cei mai asemănători cu utilizatorul-țintă (cei mai apropiați vecini) și de a pondera evaluările acestora pentru un element ca predicție a evaluării acestui element pentru utilizatorul-țintă.
Fără să știm nimic despre articole și utilizatori în sine, credem că doi utilizatori sunt similari atunci când acordă aceluiași articol evaluări similare . În mod analog, pentru CF bazată pe elemente, spunem că două elemente sunt similare atunci când au primit evaluări similare de la același utilizator. Apoi, vom face o predicție pentru un utilizator-țintă cu privire la un articol prin calcularea mediei ponderate a ratingurilor acordate de acest utilizator pentru cele mai multe X articole similare. Un avantaj cheie al CF bazată pe elemente este stabilitatea, care constă în faptul că evaluările unui anumit element nu se vor schimba semnificativ de-a lungul timpului, spre deosebire de gusturile ființelor umane.

Există destul de multe limitări ale acestei metode. Nu se descurcă bine cu raritatea atunci când nimeni din vecinătate nu a evaluat un element care este ceea ce încercați să preziceți pentru utilizatorul țintă. De asemenea, nu este eficientă din punct de vedere computațional odată cu creșterea numărului de utilizatori și de produse.
Factorizarea matricelor
Din moment ce dispersia și scalabilitatea sunt cele mai mari două provocări pentru metoda CF standard, vine o metodă mai avansată care descompune matricea spartă originală în matrici cu dimensiuni reduse cu factori/caracteristici latente și mai puțină dispersie. Aceasta este factorizarea matricei.
În afară de rezolvarea problemelor de dispersie și scalabilitate, există o explicație intuitivă a motivului pentru care avem nevoie de matrici cu dimensiuni reduse pentru a reprezenta preferințele utilizatorilor. Un utilizator a dat note bune filmelor Avatar, Gravity și Inception. Acestea nu sunt neapărat 3 opinii separate, ci arată că acest utilizator ar putea fi în favoarea filmelor SF și că ar putea exista mai multe filme SF care i-ar plăcea acestui utilizator. Spre deosebire de filmele specifice, caracteristicile latente sunt exprimate prin atribute de nivel superior, iar categoria Sci-Fi este una dintre caracteristicile latente în acest caz. Ceea ce ne oferă în cele din urmă factorizarea matricei este cât de mult se aliniază un utilizator cu un set de caracteristici latente și cât de mult se încadrează un film în acest set de caracteristici latente. Avantajul față de vecinatatea cea mai apropiată standard este că, chiar dacă doi utilizatori nu au evaluat aceleași filme, este totuși posibil să se găsească similitudinea dintre ei dacă au gusturi de bază similare, din nou caracteristici latente.
Pentru a vedea cum este factorizată o matrice, primul lucru pe care trebuie să-l înțelegem este Descompunerea valorii singulare (SVD). Pe baza algebrei liniare, orice matrice reală R poate fi descompusă în 3 matrici U, Σ și V. Continuând să folosim exemplul filmului, U este o matrice de n × r caracteristici latente ale utilizatorului, iar V este o matrice de m × r caracteristici latente ale filmului. Σ este o matrice diagonală r × r care conține valorile singulare ale matricei originale, reprezentând pur și simplu cât de importantă este o anumită caracteristică pentru a prezice preferințele utilizatorului.

Pentru a ordona valorile lui Σ prin valoarea absolută descrescătoare și pentru a trunchia matricea Σ la primele k dimensiuni ( k valori singulare), putem reconstrui matricea ca matrice A. Selectarea lui k trebuie să se asigure că A este capabilă să capteze cea mai mare parte a varianței din matricea originală R, astfel încât A să fie o aproximare a lui R, A ≈ R. Diferența dintre A și R este eroarea care se așteaptă să fie minimizată. Acesta este exact gândul analizei componentelor principale.

Când matricea R este densă, U și V ar putea fi ușor factorizate analitic. Cu toate acestea, o matrice de ratinguri de filme este foarte densă. Deși există unele metode de imputare pentru a completa valorile lipsă, vom recurge la o abordare de programare pentru a trăi cu aceste valori lipsă și pentru a găsi matricele factoriale U și V. În loc să factorizăm R prin SVD, încercăm să găsim direct U și V cu scopul ca, atunci când U și V sunt înmulțite din nou, matricea de ieșire R’ să fie cea mai apropiată de R și să nu mai fie o matrice rarefiată. Această aproximare numerică se realizează, de obicei, prin factorizarea matricei non-negative pentru sistemele de recomandare, deoarece nu există valori negative în evaluări.
A se vedea formula de mai jos. Privind ratingul prezis pentru un anumit utilizator și articol, articolul i este notat ca un vector qᵢ, iar utilizatorul u este notat ca un vector pᵤ astfel încât produsul punctat al acestor doi vectori este ratingul prezis pentru utilizatorul u pe articolul i. Această valoare este prezentată în matricea R’ la rândul u și coloana i.


Cum găsim qᵢ și pᵤ optimi? La fel ca majoritatea sarcinilor de învățare automată, se definește o funcție de pierdere pentru a minimiza costul erorilor.

rᵤᵢᵢ este ratingul real din matricea originală utilizator-element. Procesul de optimizare constă în găsirea matricei optime P, compusă din vectorul pᵤ, și a matricei Q, compusă din vectorul qᵢ, pentru a minimiza eroarea pătratică a sumei între ratingurile prezise rᵤᵢᵢ și ratingurile reale rᵤᵢᵢ. De asemenea, a fost adăugată regularizarea L2 pentru a preveni supraadaptarea vectorilor utilizator și element. De asemenea, este destul de frecventă adăugarea termenului de părtinire care are, de obicei, 3 componente majore: ratingul mediu al tuturor elementelor μ, ratingul mediu al elementului i minus μ (notat ca bᵤ), ratingul mediu acordat de utilizatorul u minus u (notat ca bᵢ).

Optimizare
Câțiva algoritmi de optimizare au fost populari pentru a rezolva Factorizarea Non-Negativă. Alternative Least Square este unul dintre ei. Deoarece funcția de pierdere este neconvexă în acest caz, nu există nicio modalitate de a ajunge la un minim global, în timp ce se poate totuși ajunge la o mare aproximație prin găsirea minimelor locale. Alternativa Least Square constă în menținerea constantă a matricei factorului utilizator, ajustarea matricei factorului elementului prin luarea derivatei funcției de pierdere și stabilirea ei la 0, apoi stabilirea constantă a matricei factorului elementului în timp ce se ajustează matricea factorului utilizator. Se repetă procesul prin schimbarea și ajustarea matricelor înainte și înapoi până la convergență. Dacă aplicați modelul NMF Scikit-learn, veți vedea că ALS este soluția implicită de utilizat, care se mai numește și Coordinate Descent. Pyspark oferă, de asemenea, pachete de descompunere destul de îngrijite care oferă mai multă flexibilitate de reglare a ALS în sine.
Câteva gânduri
Filtrarea colaborativă oferă o putere predictivă puternică pentru sistemele de recomandare și necesită în același timp cele mai puține informații. Cu toate acestea, are câteva limitări în anumite situații particulare.
În primul rând, gusturile subiacente exprimate de caracteristicile latente nu sunt de fapt interpretabile, deoarece nu există proprietăți legate de conținut ale metadatelor. Pentru un exemplu de film, nu trebuie neapărat să fie genul, cum ar fi SF în exemplul meu. Poate fi vorba despre cât de motivațională este coloana sonoră, cât de bun este complotul și așa mai departe. Filtrarea colaborativă este lipsită de transparență și explicabilitate a acestui nivel de informații.
Pe de altă parte, filtrarea colaborativă se confruntă cu un start la rece. Atunci când vine un element nou, până când acesta nu trebuie să fie evaluat de un număr substanțial de utilizatori, modelul nu este capabil să facă recomandări personalizate . În mod similar, pentru elementele din coada care nu au primit prea multe date, modelul tinde să le acorde o pondere mai mică și să aibă o prejudecată de popularitate, recomandând elemente mai populare.
De obicei, este o idee bună să avem algoritmi de ansamblu pentru a construi un model de învățare automată mai cuprinzător, cum ar fi combinarea filtrării bazate pe conținut prin adăugarea unor dimensiuni de cuvinte cheie care sunt explicabile, dar ar trebui să luăm întotdeauna în considerare compromisul dintre complexitatea modelului/computațională și eficacitatea îmbunătățirii performanței.
.