「情報の時代から推薦の時代へ」
多くの機械学習技術と同様に、推薦システムもユーザーの過去の行動に基づいて予測を行うものである。 具体的には、過去の経験に基づいて、一連のアイテムに対するユーザーの嗜好を予測することです。
コンテンツベースのアプローチでは、ユーザーのインタラクションやフィードバックを使用するのではなく、アイテム自身の特徴に関する十分な情報が必要である。 例えば、ジャンル、年、監督、俳優などの映画の属性や、自然言語処理を適用して抽出した記事のテキスト内容などである。 一方、コラボレイティブ・フィルタリングは、あるアイテムに対するユーザーの過去の嗜好以外には何も必要としない。 過去のデータに基づいているため、過去に同意したユーザーは将来も同意する傾向があるというのが、ここでの中核的な仮定である。 ユーザーの嗜好は、通常2つのカテゴリーで表現されます。 明示的な評価は、タイタニックの5つ星のように、ユーザーがアイテムに対してスライド式に与えた評価です。 これは、ユーザーがその商品をどれだけ好きかを示す、最も直接的なフィードバックです。 暗黙的評価は、ページビューやクリック数、購入履歴、音楽を聴くかどうかなど、間接的にユーザーの嗜好を示唆するものである。 今回は、レコメンダーシステムの伝統的かつ強力なツールである協調フィルタリングについて詳しく見ていきます。
協調フィルタリングの標準的な方法は、Nearest Neighborhoodアルゴリズムとして知られています。 協調フィルタリングには、ユーザーベースCFとアイテムベースCFがある。 まず、ユーザーベースCFについて見てみよう。 n×mの評価行列があり、ユーザuᵢ, i = 1, …n, アイテムpⱼ, j=1, …mとします。 ここで、ターゲットユーザiがアイテムjを見なかった/評価しなかった場合の評価rᵢⱼを予測したい。このプロセスは、ターゲットユーザiと他の全てのユーザの間の類似度を計算し、上位X人の類似ユーザを選択し、類似度を重みとしたこれらX人のユーザからの評価の加重平均を取る。


人によって評価をつけるときのベースラインが違うかもしれませんが、ある人は総じて高い点をつける傾向があり、ある人は項目に満足していてもかなり厳しいということもあるようです。 このような偏りを避けるために、加重平均を計算するときに各ユーザーの全項目の平均評価を引き、対象ユーザーで足し合わせるという方法があります。

類似度の計算方法としてピアソン相関とコサイン類似度という2つの方法があります。
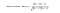

基本的には、以下の通りです。 このアイデアは、ターゲットユーザーに最も近いユーザー(最近傍)を見つけ、あるアイテムに対する彼らの評価を、ターゲットユーザーのこのアイテムの評価の予測として重み付けすることです。
アイテムやユーザー自身について何も知らなくても、2人のユーザーが同じアイテムに同じような評価を与えたとき、我々は類似していると考える。 同様に、Item-based CFでは、2つのアイテムが同じユーザーから同じような評価を受けたとき、我々は2つのアイテムが類似していると言う。 そして、あるアイテムに対するターゲットユーザの予測は、そのユーザが持つ最もX個の類似したアイテムに対する評価の加重平均を計算することによって行う。 Item-based CFの大きな利点は、人間の嗜好とは異なり、あるアイテムに対する評価が時間と共に大きく変化することがないという安定性にある。 https://medium.com/tiket-com-dev-team/build-recommendation-engine-using-graph-cbd6d8732e46
この方法にはかなり多くの制限があります。 ターゲットユーザーに対して予測しようとしているアイテムを評価した人が近所にいない場合、スパース性をうまく処理できません。 3589>
Matrix Factorization
スパース性とスケーラビリティが標準的な CF 法の 2 大課題であるため、元のスパース行列を、潜在的要因/特徴を持つ低次元行列に分解し、スパース性を低くする高度な方法が登場します。 3589>
スパース性とスケーラビリティの問題を解決するだけでなく、ユーザーの嗜好を表すためになぜ低次元の行列が必要なのか、直観的に説明することができます。 あるユーザーが、映画「アバター」、「グラビティ」、「インセプション」に良い評価を与えたとします。 これは必ずしも3つの異なる意見ではなく、このユーザがSF映画を好んでいる可能性を示しており、このユーザが好むSF映画はもっとたくさんある可能性があります。 潜在的特徴は、特定の映画と異なり、上位の属性で表現され、Sci-Fiカテゴリはこの場合の潜在的特徴の1つである。 行列分解によって得られるのは、ユーザーが潜在特徴の集合にどれだけ合致しているか、そして映画が潜在特徴の集合にどれだけ合致しているかということである。 3589>
行列がどのように因数分解されるかを見るために、最初に理解すべきは特異値分解(SVD)です。 線形代数に基づき、任意の実数行列Rは3つの行列U、Σ、Vに分解できます。映画の例で続けると、Uはn×rのユーザー潜在的特徴行列、Vはm×rの映画潜在的特徴行列となります。 Σは元の行列の特異値を含むr×rの対角行列で、特定の特徴がユーザーの嗜好を予測するためにどれだけ重要であるかを端的に表している。

Σの値を絶対値の減少でソートして、行列Σを最初のk次元(k個の特異値)まで切り詰め、行列Aとして再構築することが可能である。 kの選択は、Aが元の行列Rの分散の大部分を捕らえることができるようにする必要があり、AはRの近似であるA ≈ Rとなります。 これはまさに主成分分析の考え方です。

行列Rが密であればUとVは解析的に簡単に因数分解できましたが、密でない場合は、UとVは解析的な因数分解ができませんでした。 しかし、映画の評価の行列は、超疎である。 SVDによりRを因数分解する代わりに、UとVを直接求め、UとVを掛け合わせた出力行列R’がRの最も近い近似となり、疎行列でなくなることを目標にします。 この数値的な近似は通常、推薦システムのための非負行列因子分解で達成されます(評価に負の値は存在しないため)。 特定のユーザーとアイテムに対する予測評価を見ると、アイテムiはベクトルqᵢと記され、ユーザーuはベクトルpᵤと記され、これら二つのベクトルの内積がアイテムiにおけるユーザーuの予測評価となる。 この値は行列R’の行u、列iで示される。

どのようにして最適なqᵢとpᵤを見つけているか。

rᵤᵢは元のユーザーアイテム行列からの真の評価値である。 最適化処理は、予測された評価rᵤᵢ’と真の評価rᵤᵢの間の二乗和誤差を最小にするために、ベクトルpᵤで構成される行列Pとベクトルqᵢで構成される行列Qを見つけることである。 また、ユーザーとアイテムのベクトルのオーバーフィッティングを防ぐために、L2正則化が追加されている。 また、バイアス項を追加することはよくあることで、通常3つの主要な要素からなる:全項目の平均評価μ、項目iの平均評価マイナスμ(bᵤと表記)、ユーザuの与えた平均評価マイナスu(bᵢと表記)である。

Optimization
Non-Negative Factorizationを解くために、いくつかの最適化アルゴリズムが普及してきた。 代替最小二乗法はその一つである。 この場合、損失関数が非凸であるため、グローバルミニマムに到達する方法はありませんが、ローカルミニマムを見つけることによって、大きな近似値に到達することができます。 代替最小二乗法は、ユーザー因子行列を一定にし、損失関数を微分して0とすることで項目因子行列を調整し、ユーザー因子行列を調整しながら項目因子行列を一定にするものである。 収束するまで、行列を前後に切り替えて調整することを繰り返します。 Scikit-learn の NMF モデルを適用すると、ALS がデフォルトで使用されるソルバーであることがわかりますが、これは Coordinate Descent とも呼ばれています。 Pyspark はまた、ALS 自体をより柔軟に調整する、非常に巧妙な分解パッケージを提供しています。
いくつかの考察
協調フィルタリングは推薦システムに強い予測力を提供し、同時に最小限の情報しか必要としません。 3589>
第一に、メタデータのコンテンツに関連する特性がないため、潜在的な特徴によって表される基本的な嗜好は、実際には解釈不可能である。 例えば、映画の場合、私の例ではSci-Fiのようなジャンルである必要はないのです。 例えば映画なら、SFのようなジャンルでなくても、サウンドトラックがどれだけやる気を起こさせるか、プロットがどれだけ優れているか、などなど。 3589>
一方、Collaborative Filteringは、コールドスタートに直面しています。 新しいアイテムが入ってきても、それが相当数のユーザーによって評価されるまでは、モデルはどんなパーソナライズされた推奨もすることができないのです。 同様に、あまり多くのデータを取得していない末尾のアイテムについては、モデルはそれらにあまり重きを置かず、より人気のあるアイテムを推奨することで人気バイアスを持つ傾向があります。
通常、説明可能なキーワードのいくつかの次元を追加してコンテンツベースのフィルタリングを組み合わせるなど、より包括的な機械学習モデルを構築するアンサンブルアルゴリズムを用いることは良いアイデアですが、モデル/計算複雑度とパフォーマンス向上の有効性のトレードオフを常に検討する必要があります。