„Wir verlassen das Zeitalter der Information und treten in das Zeitalter der Empfehlung ein“
Wie viele Techniken des maschinellen Lernens macht ein Empfehlungssystem Vorhersagen auf der Grundlage des historischen Verhaltens der Benutzer. Konkret geht es darum, die Präferenzen der Benutzer für eine Reihe von Produkten auf der Grundlage früherer Erfahrungen vorherzusagen. Die beiden populärsten Ansätze zur Erstellung eines Empfehlungssystems sind die inhaltsbasierte und die kollaborative Filterung.
Der inhaltsbasierte Ansatz erfordert eine große Menge an Informationen über die eigenen Merkmale der Artikel, anstatt die Interaktionen und Rückmeldungen der Benutzer zu verwenden. Dies können zum Beispiel Filmattribute wie Genre, Jahr, Regisseur, Schauspieler usw. oder Textinhalte von Artikeln sein, die durch Anwendung von Natural Language Processing extrahiert werden können. Die kollaborative Filterung hingegen benötigt nichts weiter als die historischen Präferenzen der Benutzer für eine Reihe von Elementen. Da es auf historischen Daten basiert, ist die Grundannahme, dass die Benutzer, die in der Vergangenheit zugestimmt haben, auch in der Zukunft zustimmen werden. Die Benutzerpräferenz wird in der Regel durch zwei Kategorien ausgedrückt. Das explizite Rating ist eine Bewertung, die ein Nutzer einem Artikel auf einer gleitenden Skala gibt, z. B. 5 Sterne für Titanic. Dies ist das direkteste Feedback von Nutzern, um zu zeigen, wie sehr sie einen Artikel mögen. Implizite Bewertungen geben indirekte Hinweise auf die Präferenzen der Nutzer, wie z. B. Seitenaufrufe, Klicks, Kaufdatensätze, ob sie einen Musiktitel anhören oder nicht, usw. In diesem Artikel werde ich einen genauen Blick auf die kollaborative Filterung werfen, die ein traditionelles und leistungsstarkes Werkzeug für Empfehlungssysteme ist.
Die Standardmethode der kollaborativen Filterung ist als Nearest Neighborhood-Algorithmus bekannt. Es gibt benutzerbasiertes CF und objektbasiertes CF. Schauen wir uns zunächst die benutzerbasierte CF an. Wir haben eine n × m-Matrix von Bewertungen, mit Benutzer uᵢ, i = 1, …n und Artikel pⱼ, j=1, …m. Nun wollen wir die Bewertung rᵢⱼ vorhersagen, wenn der Zielnutzer i einen Artikel j nicht angesehen/bewertet hat. Das Verfahren besteht darin, die Ähnlichkeiten zwischen dem Zielnutzer i und allen anderen Nutzern zu berechnen, die X ähnlichsten Nutzer auszuwählen und den gewichteten Durchschnitt der Bewertungen dieser X Nutzer mit Ähnlichkeiten als Gewichte zu nehmen.


Während verschiedene Personen bei der Vergabe von Bewertungen unterschiedliche Ausgangspunkte haben, neigen einige Personen dazu, generell hohe Punktzahlen zu vergeben, andere sind ziemlich streng, obwohl sie mit den Gegenständen zufrieden sind. Um diese Verzerrung zu vermeiden, können wir bei der Berechnung des gewichteten Durchschnitts die durchschnittliche Bewertung jedes Nutzers für alle Artikel abziehen und für den Zielnutzer wieder addieren (siehe unten).

Zwei Methoden zur Berechnung der Ähnlichkeit sind die Pearson-Korrelation und die Cosinusähnlichkeit.
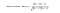

Grundsätzlich, besteht die Idee darin, die Nutzer zu finden, die dem Zielnutzer am ähnlichsten sind (nächste Nachbarn), und deren Bewertungen eines Artikels als Vorhersage der Bewertung dieses Artikels für den Zielnutzer zu gewichten.
Ohne etwas über die Gegenstände und die Benutzer selbst zu wissen, denken wir, dass zwei Benutzer ähnlich sind, wenn sie denselben Gegenstand ähnlich bewerten. Analog dazu sagen wir bei Item-basiertem CF, dass zwei Items ähnlich sind, wenn sie ähnliche Bewertungen von demselben Nutzer erhalten haben. Dann machen wir eine Vorhersage für einen Zielnutzer für einen Artikel, indem wir den gewichteten Durchschnitt der Bewertungen für die meisten X ähnlichen Artikel dieses Nutzers berechnen. Ein wesentlicher Vorteil des Item-basierten CF ist die Stabilität, die darin besteht, dass sich die Bewertungen für ein bestimmtes Item im Laufe der Zeit nicht wesentlich ändern, anders als der Geschmack von Menschen.

Es gibt eine Reihe von Einschränkungen dieser Methode. Sie kommt mit der geringen Anzahl von Bewertungen nicht gut zurecht, wenn niemand in der Nachbarschaft einen Artikel bewertet hat, den man für den Zielnutzer vorhersagen möchte. Außerdem ist sie nicht recheneffizient, wenn die Anzahl der Nutzer und Produkte wächst.
Matrixfaktorisierung
Da Sparsamkeit und Skalierbarkeit die beiden größten Herausforderungen für die Standard-CF-Methode sind, gibt es eine fortschrittlichere Methode, die die ursprüngliche spärliche Matrix in niedrigdimensionale Matrizen mit latenten Faktoren/Merkmalen und weniger Sparsamkeit zerlegt. Das ist die Matrixfaktorisierung.
Neben der Lösung der Probleme der Sparsamkeit und der Skalierbarkeit gibt es eine intuitive Erklärung dafür, warum wir niedrigdimensionale Matrizen benötigen, um die Präferenzen der Benutzer darzustellen. Ein Benutzer hat die Filme Avatar, Gravity und Inception gut bewertet. Dies sind nicht unbedingt drei verschiedene Meinungen, sondern zeigen, dass dieser Nutzer Sci-Fi-Filme bevorzugt und dass es viele weitere Sci-Fi-Filme gibt, die ihm gefallen würden. Im Gegensatz zu spezifischen Filmen werden latente Merkmale durch Attribute auf höherer Ebene ausgedrückt, und die Sci-Fi-Kategorie ist in diesem Fall eines der latenten Merkmale. Die Matrixfaktorisierung gibt uns schließlich Aufschluss darüber, wie sehr ein Benutzer mit einer Gruppe latenter Merkmale übereinstimmt und wie sehr ein Film in diese Gruppe latenter Merkmale passt. Der Vorteil gegenüber der standardmäßigen nächsten Nachbarschaft besteht darin, dass auch wenn zwei Benutzer nicht die gleichen Filme bewertet haben, es dennoch möglich ist, die Ähnlichkeit zwischen ihnen festzustellen, wenn sie den gleichen zugrunde liegenden Geschmack haben, wiederum latente Merkmale.
Um zu sehen, wie eine Matrix faktorisiert wird, muss man zunächst die Singulärwertzerlegung (SVD) verstehen. Basierend auf der linearen Algebra kann jede reelle Matrix R in drei Matrizen U, Σ und V zerlegt werden. Um beim Beispiel des Films zu bleiben: U ist eine n × r-Matrix mit latenten Merkmalen des Nutzers, V ist eine m × r-Matrix mit latenten Merkmalen des Films. Σ ist eine r × r Diagonalmatrix, die die singulären Werte der Originalmatrix enthält und einfach darstellt, wie wichtig ein bestimmtes Merkmal für die Vorhersage der Nutzerpräferenz ist.

Um die Werte von Σ nach abnehmendem Absolutwert zu sortieren und die Matrix Σ auf die ersten k Dimensionen (k singuläre Werte) abzuschneiden, können wir die Matrix als Matrix A rekonstruieren. Die Wahl von k sollte sicherstellen, dass A in der Lage ist, den größten Teil der Varianz innerhalb der ursprünglichen Matrix R zu erfassen, so dass A die Annäherung an R ist, A ≈ R. Die Differenz zwischen A und R ist der Fehler, der minimiert werden soll. Dies ist genau der Gedanke der Hauptkomponentenanalyse.

Wenn die Matrix R dicht ist, können U und V leicht analytisch faktorisiert werden. Eine Matrix von Filmbewertungen ist jedoch äußerst spärlich. Obwohl es einige Imputationsmethoden gibt, um fehlende Werte aufzufüllen, werden wir uns einem Programmieransatz zuwenden, um mit diesen fehlenden Werten zu leben und die Faktormatrizen U und V zu finden. Anstatt R über SVD zu faktorisieren, versuchen wir, U und V direkt zu finden, mit dem Ziel, dass, wenn U und V wieder zusammen multipliziert werden, die Ausgabematrix R‘ die engste Annäherung an R ist und keine dünne Matrix mehr darstellt. Diese numerische Annäherung wird bei Empfehlungssystemen in der Regel mit der nicht-negativen Matrixfaktorisierung erreicht, da es keine negativen Werte in den Bewertungen gibt.
Siehe die Formel unten. Betrachtet man die vorhergesagte Bewertung für einen bestimmten Benutzer und ein bestimmtes Element, so wird Element i als Vektor qᵢ und Benutzer u als Vektor pᵤ notiert, so dass das Punktprodukt dieser beiden Vektoren die vorhergesagte Bewertung für Benutzer u für Element i ist. Dieser Wert wird in der Matrix R‘ in Zeile u und Spalte i dargestellt.


Wie findet man optimale qᵢ und pᵤ? Wie bei den meisten Aufgaben des maschinellen Lernens wird eine Verlustfunktion definiert, um die Kosten von Fehlern zu minimieren.

rᵤᵢ ist die wahre Bewertung aus der ursprünglichen Benutzer-Element-Matrix. Der Optimierungsprozess besteht darin, die optimale Matrix P, bestehend aus dem Vektor pᵤ, und die optimale Matrix Q, bestehend aus dem Vektor qᵢ, zu finden, um den Summenquadratfehler zwischen den vorhergesagten Bewertungen rᵤᵢ‘ und den wahren Bewertungen rᵤᵢ zu minimieren. Außerdem wurde eine L2-Regularisierung hinzugefügt, um eine Überanpassung der Nutzer- und Objektvektoren zu verhindern. Es ist auch üblich, einen Verzerrungsterm hinzuzufügen, der in der Regel drei Hauptkomponenten hat: durchschnittliche Bewertung aller Elemente μ, durchschnittliche Bewertung des Elements i minus μ (bekannt als bᵤ), durchschnittliche Bewertung des Benutzers u minus u (bekannt als bᵢ).

Optimierung
Ein paar Optimierungsalgorithmen haben sich zur Lösung der nichtnegativen Faktorisierung durchgesetzt. Alternative Least Square ist einer von ihnen. Da die Verlustfunktion in diesem Fall nicht konvex ist, gibt es keine Möglichkeit, ein globales Minimum zu erreichen, aber es kann immer noch eine große Annäherung erreicht werden, indem lokale Minima gefunden werden. Die Alternative Least Square besteht darin, die Benutzer-Faktor-Matrix konstant zu halten, die Element-Faktor-Matrix anzupassen, indem man die Ableitungen der Verlustfunktion nimmt und sie gleich 0 setzt, und dann die Element-Faktor-Matrix konstant zu setzen, während man die Benutzer-Faktor-Matrix anpasst. Wiederholen Sie den Vorgang, indem Sie die Matrizen hin- und herschalten und anpassen, bis Konvergenz erreicht ist. Wenn Sie das NMF-Modell von Scikit-learn anwenden, werden Sie sehen, dass ALS der Standard-Löser ist, der auch Coordinate Descent genannt wird. Pyspark bietet auch ziemlich ordentliche Dekompositionspakete, die mehr Flexibilität bei der Einstellung von ALS selbst bieten.
Einige Gedanken
Collaborative Filtering bietet eine starke Vorhersagekraft für Empfehlungssysteme und benötigt gleichzeitig die wenigsten Informationen. Allerdings hat es in bestimmten Situationen einige Einschränkungen.
Erstens sind die zugrundeliegenden Geschmäcker, die durch latente Merkmale ausgedrückt werden, eigentlich nicht interpretierbar, da es keine inhaltsbezogenen Eigenschaften von Metadaten gibt. Bei Filmen zum Beispiel muss es nicht unbedingt das Genre sein, wie in meinem Beispiel Sci-Fi. Es kann auch darum gehen, wie motivierend der Soundtrack ist, wie gut die Handlung ist und so weiter. Dem Collaborative Filtering fehlt es an Transparenz und Erklärbarkeit dieser Informationsebene.
Andererseits ist das Collaborative Filtering mit einem Kaltstart konfrontiert. Wenn ein neuer Artikel eintrifft, ist das Modell nicht in der Lage, personalisierte Empfehlungen zu geben, bevor er nicht von einer großen Anzahl von Nutzern bewertet wurde. Ähnlich verhält es sich bei Artikeln aus dem hinteren Teil, die nicht allzu viele Daten erhalten haben: Das Modell neigt dazu, ihnen weniger Gewicht beizumessen und hat einen Popularitäts-Bias, indem es populärere Artikel empfiehlt.
Es ist in der Regel eine gute Idee, Ensemble-Algorithmen zu verwenden, um ein umfassenderes maschinelles Lernmodell zu erstellen, wie z. B. die Kombination von inhaltsbasierter Filterung durch Hinzufügen einiger Dimensionen von Schlüsselwörtern, die erklärbar sind, aber wir sollten immer den Kompromiss zwischen Modell-/Rechenkomplexität und der Effektivität der Leistungsverbesserung berücksichtigen.