„Opuszczamy wiek informacji i wkraczamy w wiek rekomendacji.”
Jak wiele technik uczenia maszynowego, system rekomendacji dokonuje predykcji na podstawie historycznych zachowań użytkowników. Konkretnie, jest to przewidywanie preferencji użytkownika dla zestawu przedmiotów w oparciu o przeszłe doświadczenia. Aby zbudować system rekomendujący, dwa najpopularniejsze podejścia to Content-based i Collaborative Filtering.
Podejście oparte na treści wymaga dużej ilości informacji o cechach własnych elementów, a nie używania interakcji i informacji zwrotnych od użytkowników. Na przykład, mogą to być atrybuty filmu, takie jak gatunek, rok, reżyser, aktor itp. lub tekstowa treść artykułów, którą można wydobyć poprzez zastosowanie Natural Language Processing. Collaborative Filtering, z drugiej strony, nie potrzebuje niczego innego poza historycznymi preferencjami użytkowników na temat zestawu elementów. Ponieważ opiera się na danych historycznych, podstawowym założeniem jest to, że użytkownicy, którzy zgadzali się w przeszłości, mają tendencję do zgadzania się również w przyszłości. Jeśli chodzi o preferencje użytkowników, są one zazwyczaj wyrażane przez dwie kategorie. Wyraźna ocena, to ocena przyznana przez użytkownika danej pozycji w skali ruchomej, np. 5 gwiazdek dla Titanica. Jest to najbardziej bezpośrednia informacja zwrotna od użytkowników, pokazująca jak bardzo podoba im się dany element. Implicit Rating, sugeruje preferencje użytkowników pośrednio, takie jak odsłony strony, kliknięcia, rekordy zakupu, czy słuchać lub nie słuchać utworu muzycznego, i tak dalej. W tym artykule przyjrzę się bliżej filtracji kolaboracyjnej, która jest tradycyjnym i potężnym narzędziem dla systemów rekomendacji.
Standardowa metoda Collaborative Filtering jest znana jako algorytm Nearest Neighborhood. Istnieją CF oparte na użytkownikach i CF oparte na elementach. Przyjrzyjmy się najpierw CF opartemu na użytkowniku. Mamy macierz n × m ocen, z użytkownikiem uᵢ, i = 1, …n i elementem pⱼ, j=1, …m. Teraz chcemy przewidzieć ocenę rᵢⱼ, jeśli użytkownik docelowy i nie oglądał/oceniał elementu j. Proces polega na obliczeniu podobieństw między użytkownikiem docelowym i a wszystkimi innymi użytkownikami, wybraniu X najbardziej podobnych użytkowników i wyciągnięciu średniej ważonej ocen od tych X użytkowników z podobieństwami jako wagami.


Różni ludzie mogą mieć różne punkty odniesienia przy wystawianiu ocen, niektórzy ludzie mają tendencję do wystawiania wysokich ocen ogólnie, niektórzy są dość surowi, nawet jeśli są zadowoleni z przedmiotów. Aby uniknąć tej stronniczości, możemy odjąć średnią ocenę każdego użytkownika dla wszystkich elementów podczas obliczania średniej ważonej i dodać ją z powrotem dla użytkownika docelowego, jak pokazano poniżej.

Dwa sposoby obliczania podobieństwa to korelacja Pearsona i podobieństwo cosinusoidalne.
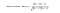

Podstawowo, ideą jest znalezienie najbardziej podobnych użytkowników do użytkownika docelowego (najbliższych sąsiadów) i ważenie ich ocen elementu jako predykcji oceny tego elementu dla użytkownika docelowego.
Nie wiedząc nic o samych przedmiotach i użytkownikach, uważamy, że dwóch użytkowników jest podobnych, gdy wystawiają podobne oceny temu samemu przedmiotowi. Analogicznie, dla CF opartego na pozycjach, mówimy, że dwie pozycje są podobne, gdy otrzymały podobne oceny od tego samego użytkownika. Następnie, dokonujemy predykcji dla użytkownika docelowego dla danego elementu poprzez obliczenie średniej ważonej ocen dla większości X podobnych elementów od tego użytkownika. Jedną z kluczowych zalet Item-based CF jest stabilność, która polega na tym, że oceny danego elementu nie zmieniają się znacząco w czasie, w przeciwieństwie do gustów ludzkich.

Istnieje sporo ograniczeń tej metody. Nie radzi sobie dobrze z rozproszeniem, gdy nikt w sąsiedztwie nie ocenił elementu, który jest tym, co próbujesz przewidzieć dla docelowego użytkownika. Ponadto, nie jest wydajna obliczeniowo wraz ze wzrostem liczby użytkowników i produktów.
Matrix Factorization
Ponieważ rozproszenie i skalowalność są dwoma największymi wyzwaniami dla standardowej metody CF, przychodzi bardziej zaawansowana metoda, która dekomponuje oryginalną nieliczbową matrycę do niskowymiarowych matryc z ukrytymi czynnikami/cechami i mniejszym rozproszeniem. To jest Matrix Factorization.
Poza rozwiązaniem kwestii rzadkości i skalowalności, istnieje intuicyjne wyjaśnienie, dlaczego potrzebujemy niskowymiarowych macierzy do reprezentowania preferencji użytkowników. Użytkownik wystawił dobre oceny filmom Avatar, Grawitacja i Incepcja. Niekoniecznie są to 3 odrębne opinie, ale pokazują, że ten użytkownik może być zwolennikiem filmów Sci-Fi i może być wiele innych filmów Sci-Fi, które ten użytkownik by polubił. W przeciwieństwie do konkretnych filmów, cechy ukryte są wyrażone przez atrybuty wyższego poziomu, a kategoria Sci-Fi jest jedną z cech ukrytych w tym przypadku. To co ostatecznie daje nam faktoryzacja macierzowa, to jak bardzo użytkownik jest dopasowany do zestawu cech ukrytych i jak bardzo film pasuje do tego zestawu cech ukrytych. Zaletą tej metody w porównaniu do standardowego najbliższego sąsiedztwa jest to, że nawet jeśli dwóch użytkowników nie oceniło tych samych filmów, nadal można znaleźć podobieństwo między nimi, jeśli mają podobne upodobania, ponownie cechy ukryte.
Aby zobaczyć, w jaki sposób faktoryzowana jest macierz, pierwszą rzeczą do zrozumienia jest Dekompozycja Wartości Pojedynczej(SVD). W oparciu o algebrę liniową, każda rzeczywista macierz R może być zdekomponowana na 3 macierze U, Σ i V. Kontynuując przykład filmu, U jest n × r macierzą cech latentnych użytkownika, V jest m × r macierzą cech latentnych filmu. Σ jest r × r diagonalną macierzą zawierającą wartości osobliwe oryginalnej macierzy, po prostu reprezentującą jak ważna jest konkretna cecha do przewidywania preferencji użytkownika.

Aby posortować wartości Σ według malejącej wartości bezwzględnej i przyciąć macierz Σ do pierwszych k wymiarów (k wartości pojedynczych), możemy zrekonstruować macierz jako macierz A. Wybór k powinien zapewnić, że A jest w stanie uchwycić większość wariancji w oryginalnej macierzy R, tak że A jest aproksymacją R, A ≈ R. Różnica pomiędzy A i R jest błędem, który ma być zminimalizowany. To jest dokładnie myśl analizy składowych głównych.

Gdy macierz R jest gęsta, U i V mogą być łatwo faktoryzowane analitycznie. Jednakże, macierz ocen filmów jest super rzadka. Chociaż istnieją pewne metody imputacji, aby wypełnić brakujące wartości, zwrócimy się do podejścia programistycznego, aby po prostu żyć z tymi brakującymi wartościami i znaleźć macierze czynnikowe U i V. Zamiast faktoryzować R przez SVD, próbujemy znaleźć U i V bezpośrednio z celem, że gdy U i V pomnożone z powrotem razem macierz wyjściowa R’ jest najbliższym przybliżeniem R i nie jest już macierzą nieliczbową. To numeryczne przybliżenie jest zwykle osiągane za pomocą faktoryzacji macierzy nieujemnej dla systemów rekomendujących, ponieważ nie ma wartości ujemnych w ocenach.
Zobacz poniższy wzór. Patrząc na przewidywaną ocenę dla konkretnego użytkownika i elementu, element i jest zapisany jako wektor qᵢ, a użytkownik u jest zapisany jako wektor pᵤ, tak że iloczyn kropkowy tych dwóch wektorów jest przewidywaną oceną dla użytkownika u na elemencie i. Wartość ta jest przedstawiona w macierzy R’ w wierszu u i kolumnie i.


Jak znaleźć optymalne qᵢ i pᵤ? Podobnie jak w przypadku większości zadań uczenia maszynowego, definiuje się funkcję straty, aby zminimalizować koszt błędów.

rᵤᵢ jest prawdziwą oceną z oryginalnej macierzy użytkownik-item. Proces optymalizacji polega na znalezieniu optymalnej macierzy P złożonej z wektora pᵤ i macierzy Q złożonej z wektora qᵢ w celu zminimalizowania błędu sumy kwadratów pomiędzy przewidywanymi ocenami rᵤᵢ a prawdziwymi ocenami rᵤᵢ. Dodano również regularyzację L2, aby zapobiec nadmiernemu dopasowaniu wektorów użytkowników i elementów. Dość powszechne jest również dodawanie terminu bias, który zazwyczaj składa się z 3 głównych składowych: średnia ocena wszystkich elementów μ, średnia ocena elementu i minus μ (oznaczona jako bᵤ), średnia ocena wystawiona przez użytkownika u minus u (oznaczona jako bᵢ).

Optymalizacja
Do rozwiązywania Nie-Negatywnej Faktoryzacji popularnych jest kilka algorytmów optymalizacyjnych. Jednym z nich jest Alternative Least Square. Ponieważ funkcja straty jest niewypukła w tym przypadku, nie ma sposobu na osiągnięcie globalnego minimum, ale nadal można osiągnąć duże przybliżenie poprzez znalezienie lokalnych minimów. Alternatywna metoda najmniejszych kwadratów polega na utrzymaniu stałej macierzy współczynnika użytkownika, dostosowaniu macierzy współczynnika elementu poprzez wzięcie pochodnych funkcji straty i ustawienie jej równej 0, a następnie ustawieniu stałej macierzy współczynnika elementu podczas dostosowywania macierzy współczynnika użytkownika. Powtarzaj proces, przełączając i dostosowując macierze tam i z powrotem, aż do osiągnięcia zbieżności. Jeśli zastosujesz model Scikit-learn NMF, zobaczysz, że ALS jest domyślnym solverem do użycia, który jest również nazywany Coordinate Descent. Pyspark oferuje również całkiem zgrabne pakiety dekompozycji, które zapewniają większą elastyczność strojenia samego ALS.
Kilka przemyśleń
Filtrowanie kolaboratywne zapewnia silną moc predykcyjną dla systemów rekomendacji, a jednocześnie wymaga najmniejszej ilości informacji. Jednakże, ma kilka ograniczeń w pewnych szczególnych sytuacjach.
Po pierwsze, podstawowe gusta wyrażone przez cechy ukryte są właściwie nie do zinterpretowania, ponieważ nie ma właściwości związanych z treścią metadanych. Dla przykładu filmu, nie musi to być gatunek, jak Sci-Fi w moim przykładzie. Może to być jak motywująca jest ścieżka dźwiękowa, jak dobra jest fabuła, i tak dalej. Collaborative Filtering jest brak przejrzystości i wyjaśnienie tego poziomu informacji.
Z drugiej strony, Collaborative Filtering jest w obliczu zimnego startu. Kiedy pojawia się nowy element, dopóki nie zostanie oceniony przez znaczną liczbę użytkowników, model nie jest w stanie stworzyć żadnych spersonalizowanych rekomendacji. Podobnie, dla elementów z ogona, które nie otrzymały zbyt wielu danych, model ma tendencję do nadawania im mniejszej wagi i ma tendencję do popularności poprzez polecanie bardziej popularnych elementów.
Zazwyczaj dobrym pomysłem jest posiadanie algorytmów grupowych w celu zbudowania bardziej kompleksowego modelu uczenia maszynowego, takiego jak łączenie filtrowania opartego na treści poprzez dodanie niektórych wymiarów słów kluczowych, które są wytłumaczalne, ale zawsze powinniśmy rozważyć kompromis pomiędzy złożonością modelu/komputerową a skutecznością poprawy wydajności.
.