“We verlaten het tijdperk van informatie en betreden het tijdperk van aanbeveling.”
Zoals veel technieken voor machinaal leren, doet een aanbevelingssysteem voorspellingen op basis van het historische gedrag van gebruikers. Het gaat om het voorspellen van de voorkeur van de gebruiker voor een reeks artikelen op basis van ervaringen uit het verleden. Om een aanbevelingssysteem te bouwen, zijn de twee populairste benaderingen Content-based en Collaborative Filtering.
Content-based benadering vereist een goede hoeveelheid informatie over de eigen kenmerken van items, in plaats van gebruik te maken van interacties en feedback van gebruikers. Dit kunnen bijvoorbeeld filmkenmerken zijn zoals genre, jaar, regisseur, acteur enz., of tekstuele inhoud van artikelen die kan worden geëxtraheerd door toepassing van Natural Language Processing. Collaborative Filtering, daarentegen, heeft niets anders nodig dan de historische voorkeur van gebruikers voor een reeks items. Omdat het gebaseerd is op historische gegevens, is de kernveronderstelling hier dat de gebruikers die in het verleden hebben ingestemd, ook in de toekomst zullen instemmen. De gebruikersvoorkeur wordt meestal uitgedrukt in twee categorieën. Expliciete waardering, is een cijfer dat een gebruiker aan een item geeft op een glijdende schaal, zoals 5 sterren voor Titanic. Dit is de meest directe feedback van gebruikers om te laten zien hoeveel ze van een item houden. Impliciete Rating, suggereert de voorkeur van gebruikers indirect, zoals paginaweergaves, clicks, aankoop records, wel of niet luisteren naar een muzieknummer, enzovoort. In dit artikel zal ik collaborative filtering onder de loep nemen, dat een traditioneel en krachtig hulpmiddel is voor recommender systemen.
De standaard methode van Collaborative Filtering staat bekend als Nearest Neighborhood algoritme. Er zijn gebruiker-gebaseerde CF en item-gebaseerde CF. Laten we eerst eens kijken naar gebruikersgebaseerde CF. We hebben een n × m matrix van ratings, met gebruiker uᵢ, i = 1, …n en item pⱼ, j=1, …m. Nu willen we de rating rᵢⱼ voorspellen als doelgebruiker i een item j niet heeft bekeken/beoordeeld. Het proces is om de overeenkomsten te berekenen tussen doelgebruiker i en alle andere gebruikers, de top X gelijkende gebruikers te selecteren, en het gewogen gemiddelde te nemen van de ratings van deze X gebruikers met overeenkomsten als gewichten.


Hoewel verschillende mensen verschillende uitgangspunten kunnen hebben bij het geven van beoordelingen, hebben sommige mensen de neiging om in het algemeen hoge scores te geven, terwijl anderen vrij streng zijn, ook al zijn ze tevreden over items. Om deze vooringenomenheid te vermijden, kunnen we bij het berekenen van het gewogen gemiddelde de gemiddelde waardering van alle items van elke gebruiker aftrekken en die voor de doelgebruiker weer optellen, zoals hieronder wordt getoond.

Twee manieren om de gelijkenis te berekenen zijn Pearson Correlatie en Cosinus Gelijkenis.
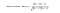

Basically, is het de bedoeling om de gebruikers te vinden die het meest op de doelgebruiker lijken (dichtstbijzijnde buren) en hun beoordelingen van een item te wegen als de voorspelling van de beoordeling van dit item voor de doelgebruiker.
Zonder dat we iets weten over items en gebruikers zelf, denken we dat twee gebruikers op elkaar lijken als ze hetzelfde item vergelijkbare beoordelingen geven. Analoog voor item-gebaseerde CF zeggen we dat twee items vergelijkbaar zijn als ze van dezelfde gebruiker vergelijkbare waarderingen hebben gekregen. Vervolgens doen we een voorspelling voor een doelgebruiker over een item door het gewogen gemiddelde te berekenen van de beoordelingen van de meeste X vergelijkbare items van deze gebruiker. Een belangrijk voordeel van itemgebaseerde CF is de stabiliteit, dat wil zeggen dat de beoordelingen van een bepaald item na verloop van tijd niet significant zullen veranderen, in tegenstelling tot de smaak van mensen.

Er zijn nogal wat beperkingen aan deze methode. De methode gaat niet goed om met schaarste wanneer niemand in de buurt een item beoordeelt dat is wat je probeert te voorspellen voor de beoogde gebruiker. Ook is het niet rekenkundig efficiënt als de groei van het aantal gebruikers en producten.
Matrix Factorization
Since sparsity en schaalbaarheid zijn de twee grootste uitdagingen voor standaard CF methode, het komt een meer geavanceerde methode die de oorspronkelijke sparse matrix decomposeert tot laag-dimensionale matrices met latente factoren / kenmerken en minder sparsity. Dat is Matrix Factorization.
Naast het oplossen van de problemen van sparsity en schaalbaarheid, is er een intuïtieve verklaring voor waarom we laag-dimensionale matrices nodig hebben om de voorkeur van gebruikers weer te geven. Een gebruiker gaf goede beoordelingen aan de films Avatar, Gravity, en Inception. Dit zijn niet noodzakelijkerwijs 3 afzonderlijke meningen, maar ze tonen aan dat deze gebruiker wellicht een voorstander is van Sci-Fi films en dat er wellicht nog veel meer Sci-Fi films zijn die deze gebruiker leuk zou vinden. In tegenstelling tot specifieke films, worden latente kenmerken uitgedrukt door attributen van een hoger niveau, en Sci-Fi categorie is een van de latente kenmerken in dit geval. Wat matrix factorisatie ons uiteindelijk geeft is hoeveel een gebruiker is afgestemd op een set van latente kenmerken, en hoeveel een film past in deze set van latente kenmerken. Het voordeel van deze methode ten opzichte van de standaard nearest neighborhood is dat ook al hebben twee gebruikers niet dezelfde films beoordeeld, het toch mogelijk is om de overeenkomst tussen hen te vinden als ze dezelfde onderliggende smaak hebben, wederom latente kenmerken.
Om te zien hoe een matrix in factoren wordt omgezet, moeten we eerst Singular Value Decomposition (SVD) begrijpen. Gebaseerd op Lineaire Algebra, kan elke reële matrix R worden ontleed in 3 matrices U, Σ, en V. Blijven met film voorbeeld, U is een n × r gebruiker-latente kenmerk matrix, V is een m × r film-latente kenmerk matrix. Σ is een r × r diagonaalmatrix die de singuliere waarden van de oorspronkelijke matrix bevat en eenvoudig weergeeft hoe belangrijk een specifiek kenmerk is om de voorkeur van de gebruiker te voorspellen.

Om de waarden van Σ te sorteren op afnemende absolute waarde en matrix Σ af te kappen tot de eerste k dimensies (k singuliere waarden), kunnen we de matrix reconstrueren als matrix A. De keuze van k moet ervoor zorgen dat A de meeste variantie in de oorspronkelijke matrix R kan vatten, zodat A de benadering van R is, A ≈ R. Het verschil tussen A en R is de fout die naar verwachting tot een minimum beperkt wordt. Dit is precies de gedachte van de Principle Component Analysis.

Wanneer matrix R dicht is, kunnen U en V gemakkelijk analytisch in factoren worden uitgedrukt. Een matrix van filmwaarderingen is echter zeer schaars. Hoewel er imputatiemethoden bestaan om ontbrekende waarden aan te vullen, zullen we ons wenden tot een programmeeraanpak om gewoon te leven met die ontbrekende waarden en factormatrices U en V te vinden. In plaats van R te factoriseren via SVD, proberen we U en V rechtstreeks te vinden met als doel dat wanneer U en V opnieuw met elkaar vermenigvuldigd worden, de outputmatrix R’ de dichtstbijzijnde benadering is van R en niet langer een sparse matrix is. Deze numerieke benadering wordt gewoonlijk bereikt met Niet-Negatieve Matrix Factorisatie voor aanbevelingssystemen, omdat er geen negatieve waarden in ratings zijn.
Zie de formule hieronder. Kijkend naar de voorspelde rating voor specifieke gebruiker en item, item i is genoteerd als een vector qᵢ, en gebruiker u is genoteerd als een vector pᵤ zodanig dat het dot-product van deze twee vectoren is de voorspelde rating voor gebruiker u op item i. Deze waarde wordt weergegeven in de matrix R’ op rij u en kolom i.


Hoe vinden we optimale qᵢ en pᵤ? Zoals de meeste machine learning-opdrachten, wordt een verliesfunctie gedefinieerd om de kosten van fouten te minimaliseren.

rᵤᵢ is de werkelijke beoordeling van de oorspronkelijke gebruiker-item matrix. Optimalisatie proces is het vinden van de optimale matrix P samengesteld door vector pᵤ en matrix Q samengesteld door vector qᵢ om de som kwadraat fout tussen voorspelde ratings rᵤᵢ ‘ en de ware ratings rᵤᵢ minimaliseren. Ook is er L2-regularisatie toegevoegd om overfitting van gebruiker- en itemvectoren te voorkomen. Het is ook heel gebruikelijk om bias term toe te voegen die meestal 3 belangrijke componenten heeft: gemiddelde rating van alle items μ, gemiddelde rating van item i min μ(genoteerd als bᵤ), gemiddelde rating gegeven door gebruiker u min u(genoteerd als bᵢ).

Optimalisatie
Een paar optimalisatiealgoritmen zijn populair om Niet-Negatieve Factorisatie op te lossen. Alternative Least Square is er daar een van. Aangezien de verliesfunctie in dit geval niet-convex is, is er geen manier om een globaal minimum te bereiken, terwijl het nog steeds een grote benadering kan bereiken door lokale minima te vinden. Alternatief Least Square is om de matrix van de gebruikersfactor constant te houden, de matrix van de itemfactor aan te passen door de afgeleide van de verliesfunctie te nemen en deze gelijk te stellen aan 0, en vervolgens de matrix van de itemfactor constant te houden terwijl de matrix van de gebruikersfactor wordt aangepast. Herhaal het proces door de matrices heen en weer te wisselen en aan te passen totdat convergentie optreedt. Als u Scikit-learn NMF model toepast, zult u zien dat ALS de standaard oplosser is om te gebruiken, die ook wel Coordinate Descent wordt genoemd. Pyspark biedt ook mooie decompositie pakketten die meer tuning flexibiliteit bieden van ALS zelf.
Enkele gedachten
Collaborative Filtering biedt sterke voorspellende kracht voor recommender systemen, en vereist tegelijkertijd de minste informatie. Het heeft echter een paar beperkingen in een aantal specifieke situaties.
Ten eerste, de onderliggende smaken uitgedrukt door latente kenmerken zijn eigenlijk niet te interpreteren omdat er geen inhoudelijke eigenschappen van metadata zijn. Bij films hoeft het bijvoorbeeld niet per se om het genre te gaan, zoals Sci-Fi in mijn voorbeeld. Het kan zijn hoe motiverend de soundtrack is, hoe goed de plot is, enzovoort. Collaborative Filtering heeft een gebrek aan transparantie en verklaarbaarheid van dit niveau van informatie.
Aan de andere kant heeft Collaborative Filtering te maken met een koude start. Wanneer een nieuw item binnenkomt, totdat het moet worden beoordeeld door een aanzienlijk aantal gebruikers, het model is niet in staat om een gepersonaliseerde aanbevelingen te doen . Ook voor items uit de staart die niet te veel data hebben gekregen, heeft het model de neiging om er minder gewicht aan toe te kennen en een populariteitsbias te vertonen door populairdere items aan te bevelen.
Het is meestal een goed idee om ensemble-algoritmes te gebruiken om een uitgebreider machine learning model te bouwen, zoals het combineren van inhoudsgebaseerde filtering door enkele dimensies van trefwoorden toe te voegen die verklaarbaar zijn, maar we moeten altijd de afweging maken tussen de complexiteit van het model/computergebruik en de effectiviteit van prestatieverbetering.