„Opouštíme věk informací a vstupujeme do věku doporučení.“
Podobně jako mnoho jiných technik strojového učení vytváří doporučovací systém předpovědi na základě historického chování uživatelů. Konkrétně jde o předpovídání preferencí uživatele pro sadu položek na základě minulých zkušeností. K vytvoření doporučovacího systému jsou nejoblíbenější dva přístupy: přístup založený na obsahu a přístup založený na kolaborativním filtrování.
Přístup založený na obsahu vyžaduje dobré množství informací o vlastních vlastnostech položek, spíše než využití interakcí a zpětných vazeb uživatelů. Mohou to být například atributy filmů, jako je žánr, rok, režisér, herec atd. nebo textový obsah článků, který lze extrahovat použitím zpracování přirozeného jazyka. Kolaborativní filtrování naproti tomu nepotřebuje nic jiného než historické preference uživatelů na sadu položek. Protože je založeno na historických datech, základním předpokladem zde je, že uživatelé, kteří souhlasili v minulosti, mají tendenci souhlasit i v budoucnosti. Pokud jde o preference uživatelů, obvykle se vyjadřují dvěma kategoriemi. Explicitní hodnocení, je hodnocení, které uživatel uděluje položce na klouzavé stupnici, například 5 hvězdiček pro Titanic. Jedná se o nejpřímější zpětnou vazbu od uživatelů, která ukazuje, jak moc se jim položka líbí. Implicitní hodnocení, naznačuje preference uživatelů nepřímo, například zobrazení stránky, kliknutí, záznamy o nákupu, zda poslouchat či neposlouchat hudební skladbu atd. V tomto článku se blíže podívám na kolaborativní filtrování, které je tradičním a výkonným nástrojem doporučovacích systémů.
Standardní metoda kolaborativního filtrování je známá jako algoritmus nejbližšího okolí. Existuje CF založený na uživateli a CF založený na položkách. Podívejme se nejprve na CF založený na uživateli. Máme matici n × m hodnocení s uživatelem uᵢ, i = 1, …n a položkou pⱼ, j=1, …m. Nyní chceme předpovědět hodnocení rᵢⱼ, pokud cílový uživatel i nesledoval/nehodnotil položku j. Postup je takový, že vypočítáme podobnosti mezi cílovým uživatelem i a všemi ostatními uživateli, vybereme X nejpodobnějších uživatelů a jako váhy vezmeme vážený průměr hodnocení těchto X uživatelů s podobnostmi.


Různí lidé mohou mít při hodnocení různá východiska, někteří mají tendenci dávat obecně vysoké známky, někteří jsou dost přísní, i když jsou s položkami spokojeni. Abychom se vyhnuli tomuto zkreslení, můžeme při výpočtu váženého průměru odečíst průměrné hodnocení všech položek každého uživatele a pro cílového uživatele ho zpětně přičíst, jak je uvedeno níže.

Dva způsoby výpočtu podobnosti jsou Pearsonova korelace a kosinová podobnost.
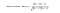

Zásadně, myšlenka spočívá v nalezení nejpodobnějších uživatelů cílovému uživateli (nejbližších sousedů) a stanovení váhy jejich hodnocení položky jako predikce hodnocení této položky pro cílového uživatele.
Aniž bychom věděli cokoli o položkách a samotných uživatelích, myslíme si, že dva uživatelé jsou si podobní, když dávají stejné položce podobná hodnocení . Analogicky u CF založeného na položkách říkáme, že dvě položky jsou podobné, když dostaly podobná hodnocení od stejného uživatele. Pak provedeme předpověď pro cílového uživatele u položky výpočtem váženého průměru hodnocení většiny X podobných položek od tohoto uživatele. Jednou z klíčových výhod CF založeného na položkách je stabilita, která spočívá v tom, že hodnocení dané položky se v průběhu času výrazně nemění, na rozdíl od vkusu lidí.

Tato metoda má poměrně dost omezení. Nevypořádává se dobře s řídkostí, když nikdo v okolí nehodnotil položku, kterou se snažíte předpovědět pro cílového uživatele. Také není výpočetně efektivní s růstem počtu uživatelů a produktů.
Matrix Factorization
Protože řídkost a škálovatelnost jsou dva největší problémy standardní metody CF, přichází pokročilejší metoda, která rozkládá původní řídkou matici na nízkorozměrné matice s latentními faktory/znaky a menší řídkostí. To je maticová faktorizace.
Kromě řešení problémů řídkosti a škálovatelnosti existuje intuitivní vysvětlení, proč potřebujeme nízkorozměrné matice, abychom reprezentovali preference uživatelů. Uživatel dal dobré hodnocení filmům Avatar, Gravitace a Počátek. Nemusí se nutně jednat o 3 samostatné názory, ale ukazují, že tento uživatel může být nakloněn sci-fi filmům a může existovat mnoho dalších sci-fi filmů, které by se tomuto uživateli líbily. Na rozdíl od konkrétních filmů jsou latentní rysy vyjádřeny atributy vyšší úrovně a kategorie Sci-Fi je v tomto případě jedním z latentních rysů. Maticová faktorizace nám nakonec poskytne informaci o tom, nakolik se uživatel shoduje s množinou latentních rysů a nakolik film zapadá do této množiny latentních rysů. Výhodou oproti standardnímu nejbližšímu sousedství je, že i když dva uživatelé nehodnotili žádný stejný film, stále je možné najít podobnost mezi nimi, pokud sdílejí podobný základní vkus, opět latentní rysy.
Chceme-li zjistit, jak se matice faktorizuje, je třeba nejprve porozumět rozkladu singulární hodnoty (SVD). Na základě lineární algebry lze libovolnou reálnou matici R rozložit na 3 matice U, Σ a V. Pokračujeme-li na příkladu filmu, U je matice n × r uživatelských latentních rysů, V je matice m × r filmových latentních rysů. Σ je r × r diagonální matice obsahující singulární hodnoty původní matice, která jednoduše vyjadřuje, jak důležitá je konkrétní vlastnost pro předpověď preferencí uživatele.

Pro seřazení hodnot Σ podle klesající absolutní hodnoty a zkrácení matice Σ na prvních k dimenzí( k singulárních hodnot) můžeme matici rekonstruovat jako matici A. Volba k by měla zajistit, aby A byla schopna zachytit většinu rozptylu v rámci původní matice R, takže A je aproximací R, A ≈ R. Rozdíl mezi A a R je chyba, která má být minimalizována. To je přesně myšlenka analýzy hlavních komponent.

Když je matice R hustá, lze U a V snadno faktorizovat analyticky. Matice hodnocení filmů je však super řídká. Přestože existují některé metody imputace pro doplnění chybějících hodnot , obrátíme se k programátorskému přístupu, abychom se s těmito chybějícími hodnotami prostě sžili a našli faktorové matice U a V. Místo faktorizace R pomocí SVD se snažíme najít U a V přímo s cílem, aby po zpětném vynásobení U a V byla výstupní matice R‘ nejbližší aproximací R a nebyla již řídkou maticí. Této numerické aproximace se u doporučovacích systémů obvykle dosahuje pomocí faktorizace nezáporných matic, protože v hodnoceních nejsou žádné záporné hodnoty.
Podívejte se na následující vzorec. Při pohledu na předpovídané hodnocení pro konkrétního uživatele a položku je položka i zaznamenána jako vektor qᵢ a uživatel u je zaznamenán jako vektor pᵤ tak, že bodový součin těchto dvou vektorů je předpovídané hodnocení pro uživatele u na položce i. Tato hodnota je uvedena v matici R‘ v řádku u a sloupci i.


Jak najdeme optimální qᵢ a pᵤ? Stejně jako u většiny úloh strojového učení je definována ztrátová funkce, která minimalizuje náklady na chyby.

rᵤᵢ je skutečné hodnocení z původní matice uživatelských položek. Optimalizační proces spočívá v nalezení optimální matice P tvořené vektorem pᵤ a matice Q tvořené vektorem qᵢ s cílem minimalizovat součtovou kvadratickou chybu mezi předpovídanými hodnoceními rᵤᵢ‘ a skutečnými hodnoceními rᵤᵢ. Byla také přidána regularizace L2, aby se zabránilo nadměrnému přizpůsobení vektorů uživatelů a položek. Zcela běžně se také přidává výraz zkreslení, který má obvykle 3 hlavní složky: průměrné hodnocení všech položek μ, průměrné hodnocení položky i minus μ(označené jako bᵤ), průměrné hodnocení dané uživatelem u minus u(označené jako bᵢ).

Optimalizace
Pro řešení nezáporné faktorizace je populárních několik optimalizačních algoritmů. Jedním z nich je alternativní nejmenší čtverec. Protože ztrátová funkce je v tomto případě nekonvexní, není možné dosáhnout globálního minima, zatímco nalezením lokálních minim lze stále dosáhnout velké aproximace. Alternativní metoda nejmenšího čtverce spočívá v tom, že matice uživatelských faktorů zůstane konstantní, matice faktorů položek se upraví derivací ztrátové funkce a nastaví se na hodnotu 0 a poté se při úpravě matice uživatelských faktorů nastaví konstantní matice faktorů položek. Proces opakujte přepínáním a nastavováním matic tam a zpět, dokud nedojde ke konvergenci. Pokud použijete model Scikit-learn NMF, uvidíte, že jako výchozí řešitel se používá ALS, který se také nazývá Coordinate Descent. Pyspark také nabízí docela elegantní rozkladové balíčky, které poskytují větší flexibilitu ladění samotného ALS.
Několik myšlenek
Kolektivní filtrování poskytuje silnou prediktivní sílu pro doporučovací systémy a zároveň vyžaduje nejméně informací. V některých konkrétních situacích má však několik omezení.
Za prvé, základní vkus vyjádřený latentními rysy vlastně nelze interpretovat, protože neexistují žádné obsahové vlastnosti metadat. Například u filmů to nemusí být nutně žánr jako sci-fi v mém příkladu. Může to být to, jak motivující je soundtrack, jak dobrý je děj a tak dále. Při kolaborativním filtrování chybí přehlednost a vysvětlitelnost této úrovně informací.
Na druhé straně se kolaborativní filtrování potýká se studeným startem. Když přijde nová položka, dokud ji nemá ohodnotit značný počet uživatelů, model není schopen provést žádné personalizované doporučení . Podobně u položek z chvostu, které nezískaly příliš mnoho dat, má model tendenci přikládat jim menší váhu a má zkreslení popularity tím, že doporučuje populárnější položky.
Obvykle je dobré mít ansámblové algoritmy pro vytvoření komplexnějšího modelu strojového učení, například kombinovat filtrování založené na obsahu přidáním některých dimenzí klíčových slov, které jsou vysvětlitelné, ale vždy bychom měli zvážit kompromis mezi složitostí modelu/výpočtu a účinností zlepšení výkonu.
.