Introduzione
Con un aumento della domanda di infrastrutture affidabili e performanti progettate per servire sistemi critici, i termini scalabilità e alta disponibilità non potrebbero essere più popolari. Mentre la gestione dell’aumento del carico di sistema è una preoccupazione comune, la diminuzione dei tempi di inattività e l’eliminazione dei singoli punti di guasto sono altrettanto importanti. L’alta disponibilità è una qualità della progettazione dell’infrastruttura su scala che affronta queste ultime considerazioni.
In questa guida, discuteremo cosa significa esattamente alta disponibilità e come può migliorare l’affidabilità della vostra infrastruttura.
Cos’è l’alta disponibilità?
In informatica, il termine disponibilità è usato per descrivere il periodo di tempo in cui un servizio è disponibile, così come il tempo richiesto da un sistema per rispondere a una richiesta fatta da un utente. L’alta disponibilità è una qualità di un sistema o di un componente che assicura un alto livello di prestazioni operative per un dato periodo di tempo.
Misurare la disponibilità
La disponibilità è spesso espressa come una percentuale che indica quanto tempo di attività ci si aspetta da un particolare sistema o componente in un dato periodo di tempo, dove un valore del 100% indicherebbe che il sistema non fallisce mai. Per esempio, un sistema che garantisce il 99% di disponibilità in un periodo di un anno può avere fino a 3,65 giorni di inattività (1%).
Questi valori sono calcolati in base a diversi fattori, compresi i periodi di manutenzione programmata e non programmata, così come il tempo di recupero da un possibile guasto del sistema.
Come funziona l’alta disponibilità ?
L’alta disponibilità funziona come un meccanismo di risposta ai guasti per le infrastrutture. Il modo in cui funziona è abbastanza semplice concettualmente, ma tipicamente richiede alcuni software e configurazioni specializzati.
Quando è importante l’alta disponibilità?
Quando si impostano sistemi di produzione robusti, minimizzare i tempi di inattività e le interruzioni del servizio è spesso una priorità assoluta. Indipendentemente da quanto siano affidabili i vostri sistemi e software, possono verificarsi dei problemi che possono far cadere le vostre applicazioni o i vostri server.
Implementare l’alta disponibilità per la vostra infrastruttura è una strategia utile per ridurre l’impatto di questo tipo di eventi. I sistemi ad alta disponibilità possono riprendersi automaticamente dai guasti dei server o dei componenti.
Cosa rende un sistema altamente disponibile?
Uno degli obiettivi dell’alta disponibilità è quello di eliminare i singoli punti di guasto nella vostra infrastruttura. Un singolo punto di guasto è un componente del vostro stack tecnologico che causerebbe un’interruzione del servizio se non fosse disponibile. Come tale, qualsiasi componente che è un requisito per la corretta funzionalità della vostra applicazione e che non ha ridondanza è considerato un singolo punto di fallimento.
Per eliminare i singoli punti di fallimento, ogni livello del vostro stack deve essere preparato per la ridondanza. Per esempio, immaginate di avere un’infrastruttura composta da due server web identici e ridondanti dietro un bilanciatore di carico. Il traffico proveniente dai clienti sarà equamente distribuito tra i server web, ma se uno dei server va giù, il bilanciatore di carico reindirizzerà tutto il traffico al server online rimanente.
Il livello del server web in questo scenario non è un singolo punto di fallimento perché:
- sono presenti componenti ridondanti per lo stesso compito
- il meccanismo in cima a questo livello (il bilanciatore di carico) è in grado di rilevare guasti nei componenti e adattare il suo comportamento per un recupero tempestivo
Ma cosa succede se il bilanciatore di carico va offline?
Con lo scenario descritto, che non è raro nella vita reale, il livello di bilanciamento del carico stesso rimane un singolo punto di fallimento. Eliminare questo singolo punto di fallimento rimanente, tuttavia, può essere impegnativo; anche se si può facilmente configurare un ulteriore bilanciatore di carico per ottenere la ridondanza, non c’è un punto ovvio sopra i bilanciatori di carico per implementare il rilevamento e il recupero dei guasti.
La sola ridondanza non può garantire l’alta disponibilità. Deve esistere un meccanismo per rilevare i guasti e intervenire quando uno dei componenti del tuo stack diventa indisponibile.
Il rilevamento dei guasti e il recupero per i sistemi ridondanti possono essere implementati utilizzando un approccio top-to-bottom: il livello superiore diventa responsabile del monitoraggio dei guasti del livello immediatamente sottostante. Nel nostro precedente scenario di esempio, il bilanciatore di carico è il livello superiore. Se uno dei server web (livello inferiore) diventa non disponibile, il bilanciatore di carico smetterà di reindirizzare le richieste per quello specifico server.
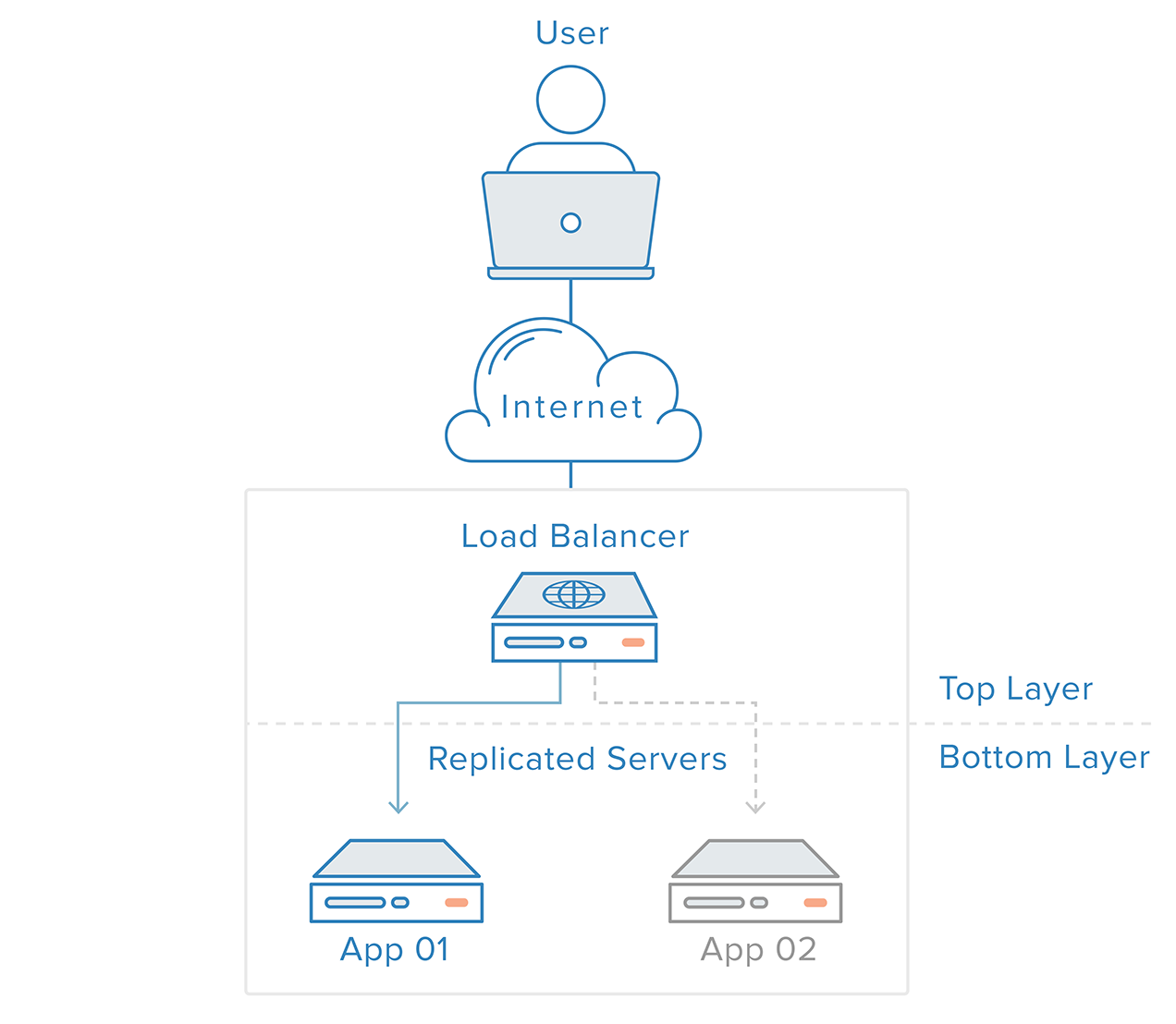
Questo approccio tende ad essere più semplice, ma ha dei limiti: ci sarà un punto nella vostra infrastruttura in cui uno strato superiore è inesistente o fuori portata, che è il caso dello strato del bilanciatore di carico. Creare un servizio di rilevamento dei guasti per il bilanciatore di carico in un server esterno creerebbe semplicemente un nuovo singolo punto di fallimento.
Con un tale scenario, è necessario un approccio distribuito. Più nodi ridondanti devono essere collegati insieme come un cluster in cui ogni nodo dovrebbe essere ugualmente in grado di rilevare e recuperare i guasti.
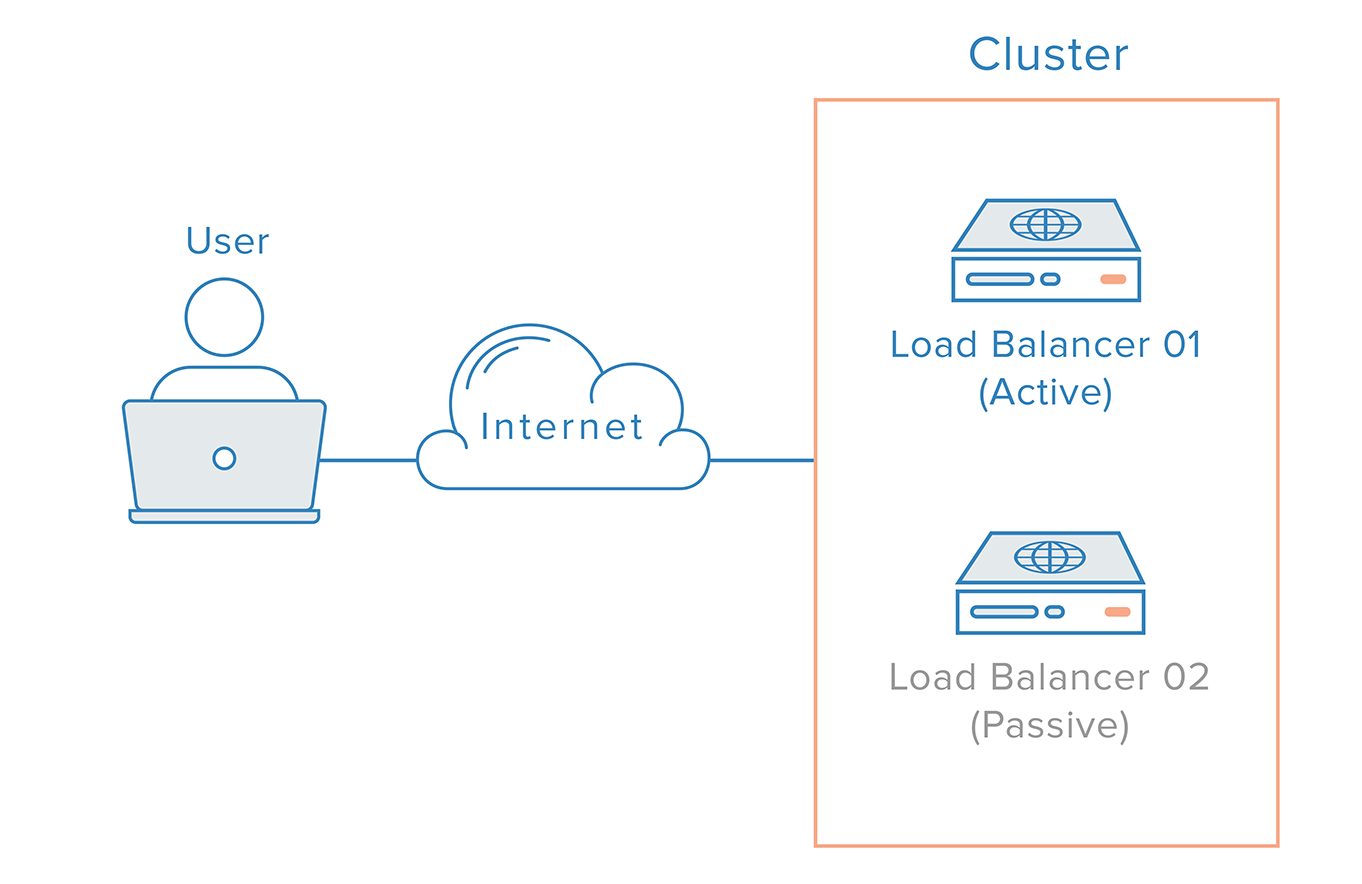
Per il caso del bilanciatore di carico, tuttavia, c’è un’ulteriore complicazione, dovuta al modo in cui lavorano i nameserver. Riprendersi da un guasto del bilanciatore di carico significa tipicamente un failover a un bilanciatore di carico ridondante, il che implica che un cambiamento DNS deve essere fatto per puntare un nome di dominio all’indirizzo IP del bilanciatore di carico ridondante. Un cambiamento come questo può richiedere un tempo considerevole per essere propagato su Internet, il che causerebbe un grave tempo di inattività a questo sistema.
Una possibile soluzione è quella di utilizzare il bilanciamento del carico DNS round-robin. Tuttavia, questo approccio non è affidabile in quanto lascia il failover all’applicazione lato client.
Una soluzione più robusta e affidabile è quella di utilizzare sistemi che permettono un remapping flessibile degli indirizzi IP, come i floating IP. La rimappatura dell’indirizzo IP su richiesta elimina i problemi di propagazione e caching inerenti alle modifiche del DNS, fornendo un indirizzo IP statico che può essere facilmente rimappato quando necessario. Il nome del dominio può rimanere associato allo stesso indirizzo IP, mentre l’indirizzo IP stesso viene spostato da un server all’altro.
Ecco come appare un’infrastruttura altamente disponibile che utilizza Floating IP:

Quali componenti del sistema sono necessari per l’alta disponibilità?
Ci sono diversi componenti che devono essere attentamente presi in considerazione per implementare l’alta disponibilità nella pratica. Molto più di un’implementazione software, l’alta disponibilità dipende da fattori come:
- Ambiente: se tutti i vostri server sono situati nella stessa area geografica, una condizione ambientale come un terremoto o un’inondazione potrebbe mettere fuori uso l’intero sistema. Avere server ridondanti in diversi data center e aree geografiche aumenterà l’affidabilità.
- Hardware: i server ad alta disponibilità dovrebbero essere resistenti alle interruzioni di corrente e ai guasti hardware, compresi i dischi rigidi e le interfacce di rete.
- Software: l’intero stack software, compreso il sistema operativo e l’applicazione stessa, deve essere preparato a gestire guasti imprevisti che potrebbero potenzialmente richiedere un riavvio del sistema, per esempio.
- Dati: la perdita e l’incoerenza dei dati può essere causata da diversi fattori, e non è limitata ai guasti del disco rigido. I sistemi altamente disponibili devono tenere conto della sicurezza dei dati in caso di guasto.
- Rete: le interruzioni di rete non pianificate rappresentano un altro possibile punto di guasto per i sistemi altamente disponibili. È importante che ci sia una strategia di rete ridondante per i possibili guasti.
Quale software può essere usato per configurare l’alta disponibilità?
Ogni livello di un sistema altamente disponibile avrà diverse esigenze in termini di software e configurazione. Tuttavia, a livello di applicazione, i bilanciatori di carico rappresentano un pezzo di software essenziale per creare qualsiasi configurazione ad alta disponibilità.
HAProxy (High Availability Proxy) è una scelta comune per il bilanciamento del carico, in quanto può gestire il bilanciamento del carico a più livelli e per diversi tipi di server, compresi i server di database.
Salendo nello stack del sistema, è importante implementare una soluzione ridondante affidabile per il punto di ingresso dell’applicazione, normalmente il bilanciatore di carico. Per rimuovere questo singolo punto di fallimento, come detto prima, abbiamo bisogno di implementare un cluster di bilanciatori di carico dietro un Floating IP. Corosync e Pacemaker sono scelte popolari per creare una tale configurazione, sia su server Ubuntu che CentOS.
Conclusione
L’alta disponibilità è un importante sottoinsieme dell’ingegneria dell’affidabilità, focalizzato ad assicurare che un sistema o un componente abbia un alto livello di prestazioni operative in un determinato periodo di tempo. A prima vista, la sua implementazione potrebbe sembrare abbastanza complessa; tuttavia, può portare enormi benefici per i sistemi che richiedono una maggiore affidabilità.