Modellazione dimensionale
La modellazione dimensionale (DM) è una tecnica di struttura dei dati ottimizzata per lo stoccaggio dei dati in un Data Warehouse. Lo scopo della modellazione dimensionale è di ottimizzare il database per un recupero più veloce dei dati. Il concetto di modellazione dimensionale è stato sviluppato da Ralph Kimball e consiste in tabelle “fact” e “dimension”.
Un modello dimensionale nel data warehouse è progettato per leggere, riassumere, analizzare informazioni numeriche come valori, saldi, conteggi, pesi, ecc. Al contrario, i modelli di relazione sono ottimizzati per l’aggiunta, l’aggiornamento e la cancellazione di dati in un sistema di transazioni online in tempo reale.
Questi modelli dimensionali e relazionali hanno il loro modo unico di memorizzare i dati che ha vantaggi specifici.
Per esempio, nel modo relazionale, la normalizzazione e i modelli ER riducono la ridondanza dei dati. Al contrario, il modello dimensionale nel data warehouse organizza i dati in modo tale che sia più facile recuperare le informazioni e generare rapporti.
Quindi, i modelli dimensionali sono usati nei sistemi di data warehouse e non sono adatti ai sistemi relazionali.
In questo tutorial, imparerete…
- Elementi del modello di dati dimensionali
- Fatto
- Dimensione
- Attributi
- Tabella dei fatti
- Tabella delle dimensioni
- Tipi di dimensioni nel Data Warehouse
- Fasi della modellazione dimensionale
- Passo 1) Identificare il processo aziendale
- Passo 2) Identificare il grano
- Passo 3) Identificare le dimensioni
- Passo 4) Identificare il fatto
- Passo 5) Costruire lo schema
- Regole per la modellazione dimensionale
- Benefici della modellazione dimensionale
Elementi del modello di dati dimensionali
Fatto
I fatti sono le misure/metriche o fatti dal tuo processo aziendale. Per un processo commerciale di vendita, una misura sarebbe il numero di vendite trimestrali
Dimensione
La dimensione fornisce il contesto che circonda un evento del processo commerciale. In termini semplici, danno chi, cosa, dove di un fatto. Nel processo d’affari Vendite, per il fatto numero di vendite trimestrali, le dimensioni sarebbero
- Chi – Nomi dei clienti
- Dove – Posizione
- Cosa – Nome del prodotto
In altre parole, una dimensione è una finestra per visualizzare le informazioni nei fatti.
Attributi
Gli attributi sono le varie caratteristiche della dimensione nella modellazione dei dati dimensionali.
Nella dimensione Posizione, gli attributi possono essere
- Stato
- Paese
- Codice postale ecc.
Gli attributi sono usati per cercare, filtrare o classificare i fatti. Le tabelle di dimensione contengono attributi
Tabella dei fatti
Una tabella dei fatti è una tabella primaria nella modellazione delle dimensioni.
Una tabella fatti contiene
- Misure/fatti
- Chiave esterna alla tabella di dimensione
Tabella di dimensione
- Una tabella di dimensione contiene dimensioni di un fatto.
- Sono unite alla tabella dei fatti tramite una chiave esterna.
- Le tabelle di dimensione sono tabelle de-normalizzate.
- Gli attributi di dimensione sono le varie colonne in una tabella di dimensione
- Le dimensioni offrono caratteristiche descrittive dei fatti con l’aiuto dei loro attributi
- Nessun limite fissato per il numero di dimensioni
- La dimensione può anche contenere una o più relazioni gerarchiche
Tipi di dimensioni in Data Warehouse
Sono i tipi di dimensioni in Data Warehouse:
- Dimensione conformata
- Dimensione outrigger
- Dimensione schiacciata
- Dimensione ruologiocando la dimensione
- Dimensione alla tabella delle dimensioni
- Dimensione spazzatura
- Dimensione degenerata
- Dimensione scambiabile
- Dimensione a passi
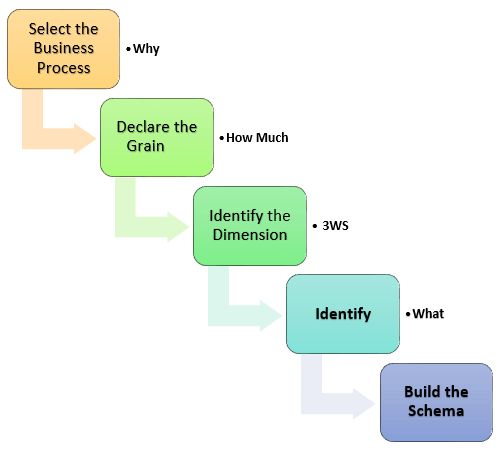
Fasi della modellazione dimensionale
La precisione nella creazione della modellazione dimensionale determina il successo dell’implementazione del data warehouse. Ecco i passi per creare il Modello Dimensionale
- Identificare il Processo di Business
- Identificare il Grain (livello di dettaglio)
- Identificare le Dimensioni
- Identificare i Fatti
- Costruire la Stella
Il modello dovrebbe descrivere il Perché, Quanto, Quando/Dove/Chi e Cosa del tuo processo di business
Passo 1) Identificare il processo di business
Identificare il processo di business effettivo che un datarehouse dovrebbe coprire. Questo potrebbe essere Marketing, Vendite, Risorse Umane, ecc. secondo i bisogni di analisi dei dati dell’organizzazione. La selezione del processo di business dipende anche dalla qualità dei dati disponibili per quel processo. È il passo più importante del processo di Data Modelling, e un fallimento qui avrebbe difetti a cascata e irreparabili.
Per descrivere il processo di business, si può usare il testo semplice o usare la Business Process Modelling Notation (BPMN) o l’Unified Modelling Language (UML).
Passo 2) Identificare il Grain
Il Grain descrive il livello di dettaglio del problema/soluzione del business. È il processo di identificazione del livello più basso di informazione per qualsiasi tabella nel tuo data warehouse. Se una tabella contiene dati di vendita per ogni giorno, allora dovrebbe avere una granularità giornaliera. Se una tabella contiene dati di vendita totali per ogni mese, allora ha granularità mensile.
Durante questa fase, si risponde a domande come
- Dobbiamo memorizzare tutti i prodotti disponibili o solo alcuni tipi di prodotti? Questa decisione si basa sui processi di business selezionati per il Datawarehouse
- Abbiamo bisogno di memorizzare le informazioni di vendita dei prodotti su base mensile, settimanale, giornaliera o oraria? Questa decisione dipende dalla natura dei rapporti richiesti dai dirigenti
- Come influiscono le due scelte precedenti sulla dimensione del database?
Esempio di grano:
Il CEO di una MNC vuole trovare le vendite di prodotti specifici in diverse località su base giornaliera.
Quindi, il grano è “informazioni sulla vendita di prodotti per località in base al giorno”.
Passo 3) Identificare le dimensioni
Le dimensioni sono sostantivi come data, negozio, inventario, ecc. Queste dimensioni sono dove tutti i dati devono essere memorizzati. Per esempio, la dimensione data può contenere dati come anno, mese e giorno della settimana.
Esempio di dimensioni:
Il CEO di una multinazionale vuole trovare le vendite di prodotti specifici in diverse località su base giornaliera.
Dimensioni: Prodotto, Luogo e Tempo
Attributi: Per Prodotto: Product key (Foreign Key), Name, Type, Specifications
Hierarchies: Per Località: Paese, Stato, Città, Indirizzo, Nome
Passo 4) Identificare il Fatto
Questo passo è co-associato con gli utenti aziendali del sistema perché è qui che ottengono l’accesso ai dati memorizzati nel data warehouse. La maggior parte delle righe della tabella dei fatti sono valori numerici come il prezzo o il costo per unità, ecc.
Esempio di fatti:
Il CEO di una MNC vuole trovare le vendite per prodotti specifici in diverse località su base giornaliera.
Il fatto qui è Somma delle vendite per prodotto per località per tempo.
Passo 5) Costruire lo schema
In questo passo, si implementa il modello di dimensione. Uno schema non è altro che la struttura del database (disposizione delle tabelle). Ci sono due schemi popolari
- Schema a stella
L’architettura dello schema a stella è facile da progettare. Si chiama schema a stella perché lo schema assomiglia ad una stella, con punti che si irradiano da un centro. Il centro della stella consiste nella tabella dei fatti, e i punti della stella sono tabelle dimensionali.
Le tabelle dei fatti in uno schema a stella che è la terza forma normale mentre le tabelle dimensionali sono de-normalizzate.
- Snowflake Schema
Lo snowflake schema è un’estensione dello star schema. In uno schema snowflake, ogni dimensione è normalizzata e collegata a più tabelle di dimensione.
Regole per la modellazione dimensionale
Seguono le regole e i principi della modellazione dimensionale:
- Caricare dati atomici in strutture dimensionali.
- Costruire modelli dimensionali intorno ai processi di business.
- Assicurarsi che ogni tabella di fatti abbia una tabella dimensionale data associata.
- Assicurarsi che tutti i fatti in una singola tabella di fatti siano alla stessa grana o livello di dettaglio.
- E’ essenziale memorizzare le etichette dei report e i valori del dominio dei filtri nelle tabelle dimensionali
- Necessario assicurarsi che le tabelle dimensionali usino una chiave surrogata
- Continua a bilanciare requisiti e realtà per fornire soluzioni di business che supportino il loro processo decisionale
Benefici della modellazione dimensionale
- La standardizzazione delle dimensioni permette un facile reporting tra aree del business.
- Le tabelle di dimensione memorizzano la storia delle informazioni dimensionali.
- Permette di introdurre completamente nuove dimensioni senza grandi interruzioni alla tabella dei fatti.
- Dimensionale anche per memorizzare i dati in modo tale che è più facile recuperare le informazioni dai dati una volta che i dati sono memorizzati nel database.
- Paragonato al modello normalizzato la tabella dimensionale è più facile da capire.
- Le informazioni sono raggruppate in categorie aziendali chiare e semplici.
- Il modello dimensionale è molto comprensibile per il business. Questo modello è basato su termini aziendali, in modo che l’azienda sappia cosa significa ogni fatto, dimensione o attributo.
- I modelli dimensionali sono deformalizzati e ottimizzati per una veloce interrogazione dei dati. Molte piattaforme di database relazionali riconoscono questo modello e ottimizzano i piani di esecuzione delle query per aiutare le prestazioni.
- La modellazione dimensionale nel data warehouse crea uno schema che è ottimizzato per alte prestazioni. Significa un minor numero di join e aiuta a minimizzare la ridondanza dei dati.
- Il modello dimensionale aiuta anche ad aumentare le prestazioni delle query. È più denormalizzato quindi è ottimizzato per l’interrogazione.
- I modelli dimensionali possono ospitare comodamente i cambiamenti. Le tabelle di dimensione possono avere più colonne aggiunte a loro senza influenzare le applicazioni di business intelligence esistenti che usano queste tabelle.
Cos’è il modello di dati multidimensionale nel data warehouse?
Il modello di dati multidimensionale nel data warehouse è un modello che rappresenta i dati sotto forma di cubi di dati. Permette di modellare e visualizzare i dati in più dimensioni ed è definito da dimensioni e fatti. Il modello di dati multidimensionale è generalmente categorizzato intorno a un tema centrale e rappresentato da una tabella di fatti.
Sommario:
- Un modello dimensionale è una tecnica di struttura dei dati ottimizzata per gli strumenti di Data warehousing.
- I fatti sono le misure/metriche o i fatti del vostro processo aziendale.
- La dimensione fornisce il contesto che circonda un evento del processo aziendale.
- Gli attributi sono le varie caratteristiche della modellazione delle dimensioni.
- Una tabella di fatti è una tabella primaria in un modello dimensionale.
- Una tabella di dimensioni contiene le dimensioni di un fatto.
- Ci sono tre tipi di fatti 1. Additivo 2. Non additivo 3. Semi-additivo.
- I tipi di dimensioni sono Conformate, Outrigger, Shrunken, Role-playing, Dimension to Dimension Table, Junk, Degenerate, Swappable e Step Dimensions.
- Cinque passi della modellazione dimensionale sono 1. Identificare il processo di business 2. Identificare il Grain (livello di dettaglio) 3. Identificare le dimensioni 4. Identificare i fatti 5. Costruire la stella
- Per la modellazione dimensionale nel data warehouse, c’è bisogno di assicurare che ogni tabella di fatti abbia una tabella dimensionale associata alla data.