Modélisation dimensionnelle
La modélisation dimensionnelle (DM) est une technique de structure de données optimisée pour le stockage des données dans un entrepôt de données. L’objectif de la modélisation dimensionnelle est d’optimiser la base de données pour une récupération plus rapide des données. Le concept de modélisation dimensionnelle a été développé par Ralph Kimball et se compose de tables « fact » et « dimension ».
Un modèle dimensionnel dans un entrepôt de données est conçu pour lire, résumer, analyser des informations numériques comme des valeurs, des balances, des comptes, des poids, etc. En revanche, les modèles relationnels sont optimisés pour l’ajout, la mise à jour et la suppression de données dans un système de transactions en ligne en temps réel.
Ces modèles dimensionnels et relationnels ont leur façon unique de stocker les données qui présente des avantages spécifiques.
Par exemple, dans le mode relationnel, la normalisation et les modèles ER réduisent la redondance des données. Au contraire, le modèle dimensionnel dans l’entrepôt de données organise les données de telle sorte qu’il est plus facile de récupérer les informations et de générer des rapports.
Hence, les modèles dimensionnels sont utilisés dans les systèmes d’entrepôt de données et ne conviennent pas aux systèmes relationnels.
Dans ce tutoriel, vous apprendrez…
- Éléments du modèle de données dimensionnel
- Fait
- Dimension
- Attributs
- Tableau des faits
- Tableau des dimensions
- Types de dimensions dans l’entrepôt de données
- Étapes de la modélisation dimensionnelle
- Étape 1) Identifier le processus métier
- Étape 2) Identifier le grain.
- Étape 3) Identifier les dimensions
- Étape 4) Identifier le fait
- Étape 5) Construire le schéma
- Règles pour la modélisation dimensionnelle
- Avantages de la modélisation dimensionnelle
Éléments du modèle de données dimensionnel
Fait
Les faits sont les mesures/métriques ou les faits de votre processus métier. Pour un processus métier Ventes, une mesure serait le nombre de ventes trimestrielles
Dimension
Les dimensions fournissent le contexte entourant un événement du processus métier. En termes simples, elles donnent qui, quoi, où d’un fait. Dans le processus d’affaires Ventes, pour le fait nombre de ventes trimestrielles, les dimensions seraient
- Qui – Noms des clients
- Où – Lieu
- Quoi – Nom du produit
En d’autres termes, une dimension est une fenêtre pour visualiser les informations dans les faits.
Attributs
Les attributs sont les différentes caractéristiques de la dimension dans la modélisation des données dimensionnelles.
Dans la dimension Emplacement, les attributs peuvent être
- Etat
- Pays
- Code postal etc.
Les attributs sont utilisés pour rechercher, filtrer ou classer les faits. Les tables de dimension contiennent des attributs
Table de faits
Une table de faits est une table primaire dans la modélisation des dimensions.
Une table de faits contient
- Mesures/faits
- Clé étrangère à la table de dimension
Table de dimension
- Une table de dimension contient les dimensions d’un fait.
- Elles sont jointes à la table des faits via une clé étrangère.
- Les tables de dimension sont des tables dé-normalisées.
- Les attributs de dimension sont les différentes colonnes d’une table de dimension
- Les dimensions offrent des caractéristiques descriptives des faits à l’aide de leurs attributs
- Aucune limite fixée pour donnée pour le nombre de dimensions
- La dimension peut également contenir une ou plusieurs relations hiérarchiques
Types de dimensions dans le Data Warehouse
Voici les types de dimensions dans le Data Warehouse :
- Dimension conformée
- Dimension de déclenchement
- Dimension d’enfouissement
- Dimension de rôle.playing Dimension
- Dimension to Dimension Table
- Junk Dimension
- Degenerate Dimension
- Swappable Dimension
- Step Dimension
Steps of Dimensional Modelling
La précision dans la création de votre modélisation Dimensionnelle détermine le succès de votre implémentation d’entrepôt de données. Voici les étapes pour créer un modèle dimensionnel
- Identifier le processus métier
- Identifier le grain (niveau de détail)
- Identifier les dimensions
- Identifier les faits
- Construire l’étoile
Le modèle doit décrire le Pourquoi, Combien, Quand/Où/Qui et Quoi de votre processus métier
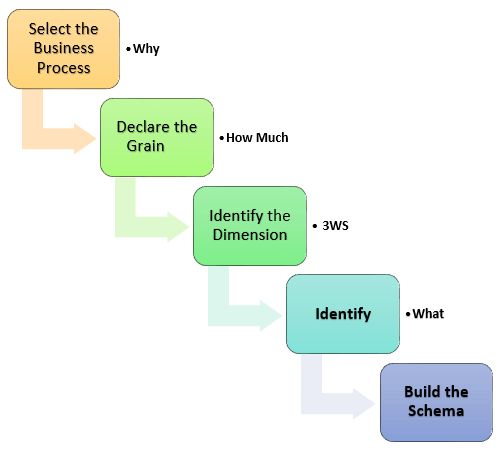
Étape 1) Identifier le processus métier
Identifier le processus métier réel qu’un entrepôt de données doit couvrir. Cela peut être le marketing, les ventes, les RH, etc. selon les besoins d’analyse de données de l’organisation. La sélection du processus métier dépend également de la qualité des données disponibles pour ce processus. C’est l’étape la plus importante du processus de modélisation des données, et un échec ici aurait des défauts en cascade et irréparables.
Pour décrire le processus métier, vous pouvez utiliser du texte brut ou utiliser la notation de base de modélisation des processus métier (BPMN) ou le langage unifié de modélisation (UML).
Étape 2) Identifier le Grain
Le Grain décrit le niveau de détail pour le problème/solution métier. C’est le processus d’identification du niveau d’information le plus bas pour toute table de votre entrepôt de données. Si une table contient des données de ventes pour chaque jour, alors elle doit avoir une granularité quotidienne. Si une table contient des données de ventes totales pour chaque mois, alors elle a une granularité mensuelle.
Pendant cette étape, vous répondez à des questions telles que
- Nous faut-il stocker tous les produits disponibles ou seulement quelques types de produits ? Cette décision dépend des processus métier sélectionnés pour le Datawarehouse
- Devons-nous stocker les informations de vente des produits sur une base mensuelle, hebdomadaire, quotidienne ou horaire ? Cette décision dépend de la nature des rapports demandés par les cadres
- Comment les deux choix ci-dessus affectent-ils la taille de la base de données ?
Exemple de Grain :
Le PDG d’un MNC veut trouver les ventes de produits spécifiques dans différents endroits sur une base quotidienne.
Donc, le grain est « l’information sur les ventes de produits par emplacement, par jour ».
Étape 3) Identifier les dimensions
Les dimensions sont des noms comme date, magasin, inventaire, etc. Ces dimensions sont l’endroit où toutes les données doivent être stockées. Par exemple, la dimension date peut contenir des données comme l’année, le mois et le jour de la semaine.
Exemple de dimensions :
Le PDG d’un MNC veut trouver les ventes de produits spécifiques dans différents endroits sur une base quotidienne.
Dimensions : Produit, emplacement et temps
Attributs : Pour le produit : Clé de produit (clé étrangère), nom, type, spécifications
Hiérarchies : Pour Location : Pays, État, Ville, Adresse municipale, Nom
Étape 4) Identifier le fait
Cette étape est co-associée aux utilisateurs métier du système car c’est là qu’ils ont accès aux données stockées dans l’entrepôt de données. La plupart des lignes de la table de faits sont des valeurs numériques comme le prix ou le coût par unité, etc.
Exemple de faits :
Le PDG d’un MNC veut trouver les ventes de produits spécifiques dans différents endroits sur une base quotidienne.
Le fait ici est Somme des ventes par produit par emplacement par temps.
Étape 5) Construire le schéma
Dans cette étape, vous implémentez le modèle de dimension. Un schéma n’est rien d’autre que la structure de la base de données (disposition des tables). Il existe deux schémas populaires
- Schéma en étoile
L’architecture du schéma en étoile est facile à concevoir. On l’appelle schéma en étoile parce que le schéma ressemble à une étoile, avec des points rayonnant à partir d’un centre. Le centre de l’étoile est constitué de la table de faits, et les points de l’étoile sont des tables de dimension.
Les tables de faits dans un schéma en étoile qui est la troisième forme normale alors que les tables de dimension sont dé-normalisées.
- Schéma en flocon de neige
Le schéma en flocon de neige est une extension du schéma en étoile. Dans un schéma snowflake, chaque dimension est normalisée et connectée à plus de tables de dimension.
Règles de la modélisation dimensionnelle
Voici les règles et les principes de la modélisation dimensionnelle :
- Chargez des données atomiques dans des structures dimensionnelles.
- Construisez des modèles dimensionnels autour des processus d’affaires.
- Nécessité de s’assurer que chaque table de faits a une table de dimension de date associée.
- S’assurer que tous les faits dans une seule table de faits sont au même grain ou niveau de détail.
- Il est essentiel de stocker les étiquettes de rapport et les valeurs de domaine de filtrage dans les tables de dimension
- Nécessité de s’assurer que les tables de dimension utilisent une clé de substitution
- Equilibrer continuellement les exigences et les réalités pour fournir une solution d’affaires pour soutenir leur prise de décision
Avantages de la modélisation dimensionnelle
- La normalisation des dimensions permet un reporting facile à travers les domaines de l’entreprise.
- Les tables de dimensions stockent l’historique des informations dimensionnelles.
- Elle permet d’introduire une dimension entièrement nouvelle sans perturbations majeures de la table de faits.
- Dimensionnelle aussi pour stocker les données d’une manière telle qu’il est plus facile de récupérer l’information des données une fois que les données sont stockées dans la base de données.
- Par rapport au modèle normalisé la table dimensionnelle est plus facile à comprendre.
- Les informations sont regroupées en catégories professionnelles claires et simples.
- Le modèle dimensionnel est très compréhensible par le métier. Ce modèle est basé sur des termes métier, de sorte que le métier sait ce que signifie chaque fait, dimension ou attribut.
- Les modèles dimensionnels sont déformalisés et optimisés pour une interrogation rapide des données. De nombreuses plateformes de bases de données relationnelles reconnaissent ce modèle et optimisent les plans d’exécution des requêtes pour aider à la performance.
- La modélisation dimensionnelle dans l’entrepôt de données crée un schéma qui est optimisé pour une haute performance. Cela signifie moins de jointures et aide à minimiser la redondance des données.
- Le modèle dimensionnel permet également d’augmenter les performances des requêtes. Il est plus dénormalisé donc il est optimisé pour les requêtes.
- Les modèles dimensionnels peuvent confortablement s’adapter au changement. Les tables de dimension peuvent avoir plus de colonnes ajoutées sans affecter les applications de business intelligence existantes qui utilisent ces tables.
Qu’est-ce que le modèle de données multidimensionnel dans l’entrepôt de données ?
Le modèle de données multidimensionnel dans l’entrepôt de données est un modèle qui représente les données sous forme de cubes de données. Il permet de modéliser et de visualiser les données en plusieurs dimensions et il est défini par des dimensions et des faits. Le modèle de données multidimensionnel est généralement catégorisé autour d’un thème central et représenté par une table de faits.
Résumé :
- Un modèle dimensionnel est une technique de structure de données optimisée pour les outils de Data warehousing.
- Les faits sont les mesures/métriques ou les faits de votre processus métier.
- La dimension fournit le contexte entourant un événement du processus métier.
- Les attributs sont les différentes caractéristiques de la modélisation des dimensions.
- Une table de faits est une table primaire dans un modèle dimensionnel.
- Une table de dimensions contient les dimensions d’un fait.
- Il existe trois types de faits 1. Additif 2. Non-additif 3. Semi-additif.
- Les types de dimensions sont les suivantes : dimensions conformes, outrigger, rétrécissement, jeu de rôle, dimension à table de dimensions, junk, dégénéré, interchangeable et step.
- Les cinq étapes de la modélisation dimensionnelle sont 1. Identifier le processus métier 2. Identifier le grain (niveau de détail) 3. Identifier les dimensions 4. Identifier les faits 5. Construire l’étoile
- Pour la modélisation dimensionnelle dans l’entrepôt de données, il est nécessaire de s’assurer que chaque table de faits a une table de dimension de date associée.