Introduction
Avec une demande accrue d’infrastructures fiables et performantes conçues pour servir les systèmes critiques, les termes d’évolutivité et de haute disponibilité ne pourraient pas être plus populaires. Si la gestion de l’augmentation de la charge du système est une préoccupation commune, la diminution des temps d’arrêt et l’élimination des points uniques de défaillance sont tout aussi importantes. La haute disponibilité est une qualité de conception d’infrastructure à l’échelle qui répond à ces dernières considérations.
Dans ce guide, nous allons discuter de ce que signifie exactement la haute disponibilité et comment elle peut améliorer la fiabilité de votre infrastructure.
Qu’est-ce que la haute disponibilité ?
En informatique, le terme disponibilité est utilisé pour décrire la période de temps pendant laquelle un service est disponible, ainsi que le temps nécessaire à un système pour répondre à une demande faite par un utilisateur. La haute disponibilité est une qualité d’un système ou d’un composant qui assure un haut niveau de performance opérationnelle pendant une période de temps donnée.
Mesurer la disponibilité
La disponibilité est souvent exprimée sous la forme d’un pourcentage indiquant le temps de disponibilité attendu d’un système ou d’un composant particulier pendant une période de temps donnée, où une valeur de 100% indiquerait que le système ne tombe jamais en panne. Par exemple, un système qui garantit 99% de disponibilité sur une période d’un an peut avoir jusqu’à 3,65 jours de temps d’arrêt (1%).
Ces valeurs sont calculées en fonction de plusieurs facteurs, y compris les périodes de maintenance programmées et non programmées, ainsi que le temps de récupération d’une éventuelle défaillance du système.
Comment fonctionne la haute disponibilité ?
La haute disponibilité fonctionne comme un mécanisme de réponse aux défaillances pour l’infrastructure. La façon dont elle fonctionne est assez simple sur le plan conceptuel, mais nécessite généralement un logiciel et une configuration spécialisés.
Quand la haute disponibilité est-elle importante ?
Lors de la mise en place de systèmes de production robustes, la minimisation des temps d’arrêt et des interruptions de service est souvent une priorité élevée. Quel que soit le degré de fiabilité de vos systèmes et logiciels, des problèmes peuvent survenir et entraîner l’arrêt de vos applications ou de vos serveurs.
La mise en place de la haute disponibilité pour votre infrastructure est une stratégie utile pour réduire l’impact de ces types d’événements. Les systèmes à haute disponibilité peuvent se remettre automatiquement de la défaillance d’un serveur ou d’un composant.
Qu’est-ce qui rend un système à haute disponibilité ?
L’un des objectifs de la haute disponibilité est d’éliminer les points uniques de défaillance dans votre infrastructure. Un point unique de défaillance est un composant de votre pile technologique qui provoquerait une interruption de service s’il devenait indisponible. En tant que tel, tout composant nécessaire au bon fonctionnement de votre application qui n’est pas redondant est considéré comme un point unique de défaillance.
Pour éliminer les points uniques de défaillance, chaque couche de votre pile doit être préparée à la redondance. Par exemple, imaginez que vous avez une infrastructure composée de deux serveurs web identiques et redondants derrière un équilibreur de charge. Le trafic provenant des clients sera réparti de manière égale entre les serveurs web, mais si l’un des serveurs tombe en panne, l’équilibreur de charge redirigera tout le trafic vers le serveur en ligne restant.
La couche de serveur web dans ce scénario n’est pas un point de défaillance unique car :
- des composants redondants pour la même tâche sont en place
- le mécanisme au sommet de cette couche (l’équilibreur de charge) est capable de détecter les défaillances des composants et d’adapter son comportement pour une récupération opportune
Mais que se passe-t-il si l’équilibreur de charge se déconnecte ?
Avec le scénario décrit, qui n’est pas rare dans la vie réelle, la couche d’équilibrage de charge elle-même reste un point unique de défaillance. L’élimination de ce point de défaillance unique restant, cependant, peut être difficile ; même si vous pouvez facilement configurer un équilibreur de charge supplémentaire pour obtenir la redondance, il n’y a pas de point évident au-dessus des équilibreurs de charge pour mettre en œuvre la détection et la récupération des défaillances.
La redondance seule ne peut pas garantir la haute disponibilité. Un mécanisme doit être mis en place pour détecter les défaillances et prendre des mesures lorsqu’un des composants de votre pile devient indisponible.
La détection et la récupération des défaillances pour les systèmes redondants peuvent être mises en œuvre en utilisant une approche de haut en bas : la couche du dessus devient responsable de la surveillance des défaillances de la couche immédiatement inférieure. Dans notre exemple de scénario précédent, l’équilibreur de charge est la couche supérieure. Si l’un des serveurs web (couche inférieure) devient indisponible, l’équilibreur de charge cessera de rediriger les demandes pour ce serveur spécifique.
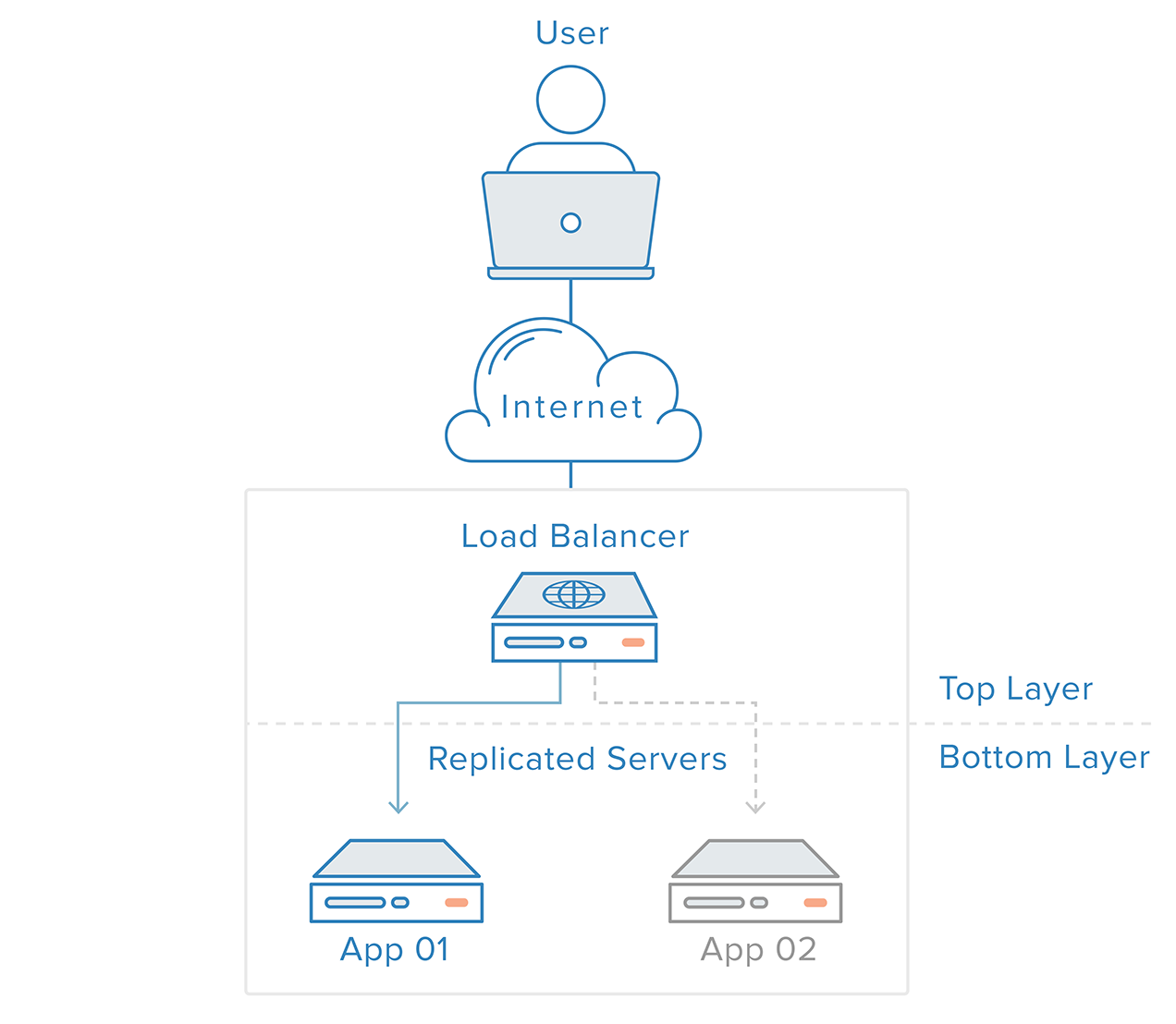
Cette approche tend à être plus simple, mais elle a des limites : il y aura un point dans votre infrastructure où une couche supérieure est soit inexistante, soit hors de portée, ce qui est le cas de la couche de l’équilibreur de charge. Créer un service de détection de défaillance pour l’équilibreur de charge dans un serveur externe ne ferait que créer un nouveau point de défaillance unique.
Avec un tel scénario, une approche distribuée est nécessaire. Plusieurs nœuds redondants doivent être connectés ensemble en tant que cluster où chaque nœud doit être également capable de détecter et de récupérer les pannes.
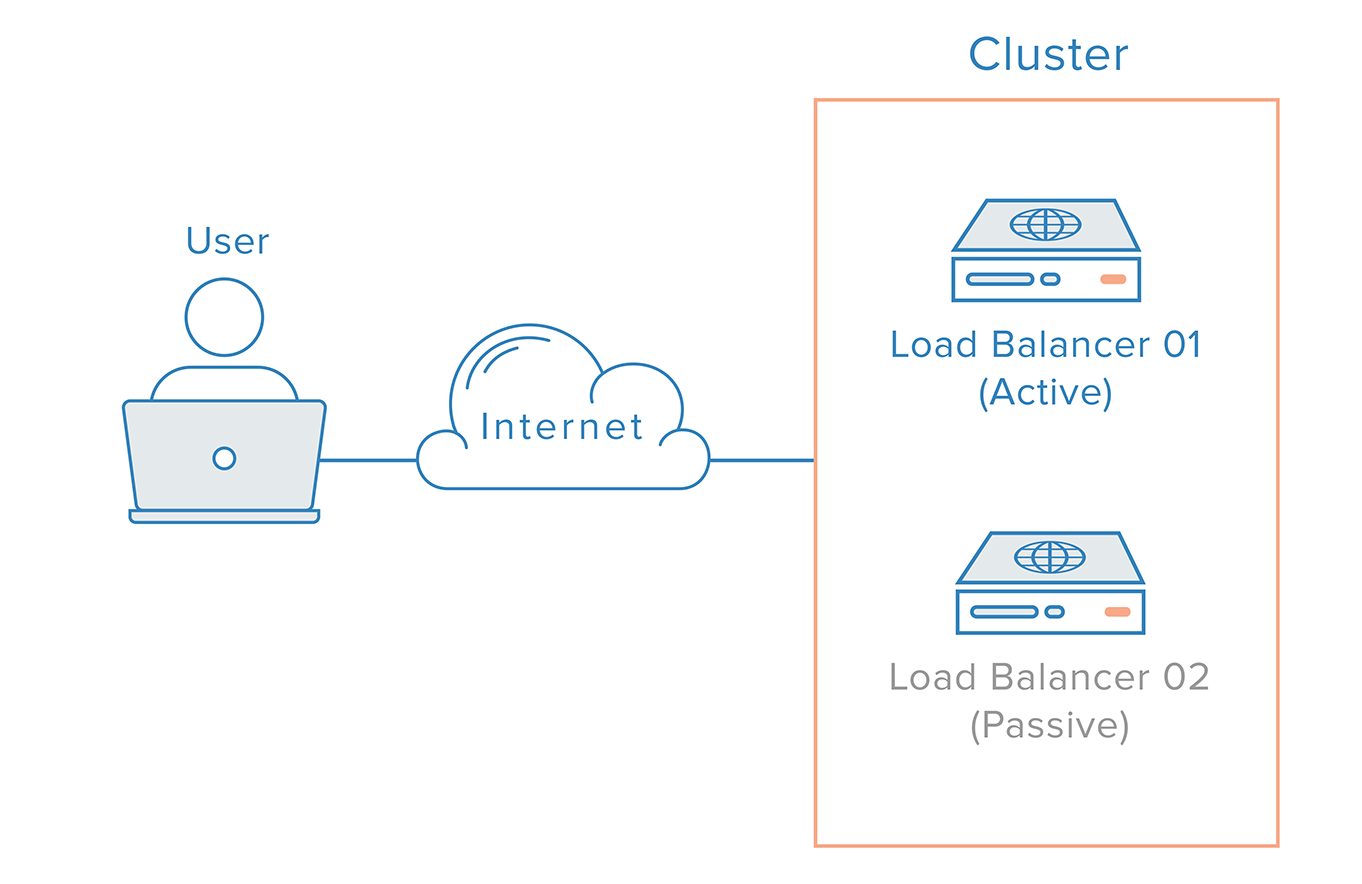
Pour le cas de l’équilibreur de charge, cependant, il y a une complication supplémentaire, en raison de la façon dont les serveurs de noms fonctionnent. La récupération d’une panne d’équilibreur de charge signifie généralement un basculement vers un équilibreur de charge redondant, ce qui implique qu’un changement DNS doit être effectué afin de faire pointer un nom de domaine vers l’adresse IP de l’équilibreur de charge redondant. Un tel changement peut prendre un temps considérable pour être propagé sur Internet, ce qui entraînerait une sérieuse indisponibilité de ce système.
Une solution possible consiste à utiliser l’équilibrage de charge DNS round-robin. Cependant, cette approche n’est pas fiable car elle laisse le basculement à l’application côté client.
Une solution plus robuste et plus fiable consiste à utiliser des systèmes qui permettent un remappage flexible des adresses IP, comme les IP flottantes. Le remappage d’adresse IP à la demande élimine les problèmes de propagation et de mise en cache inhérents aux changements de DNS en fournissant une adresse IP statique qui peut être facilement remappée en cas de besoin. Le nom de domaine peut rester associé à la même adresse IP, tandis que l’adresse IP elle-même est déplacée entre les serveurs.
Voici à quoi ressemble une infrastructure hautement disponible utilisant des IP flottantes :

Quels sont les composants système nécessaires à la haute disponibilité ?
Il existe plusieurs composants qui doivent être soigneusement pris en compte pour mettre en œuvre la haute disponibilité dans la pratique. Bien plus qu’une mise en œuvre logicielle, la haute disponibilité dépend de facteurs tels que :
- Environnement : si tous vos serveurs sont situés dans la même zone géographique, une condition environnementale telle qu’un tremblement de terre ou une inondation pourrait faire tomber tout votre système. Avoir des serveurs redondants dans différents centres de données et zones géographiques augmentera la fiabilité.
- Matériel : les serveurs hautement disponibles doivent être résilients aux pannes de courant et aux défaillances matérielles, notamment les disques durs et les interfaces réseau.
- Logiciel : toute la pile logicielle, y compris le système d’exploitation et l’application elle-même, doit être préparée à gérer une panne inattendue qui pourrait potentiellement nécessiter un redémarrage du système, par exemple.
- Données : la perte et l’incohérence des données peuvent être causées par plusieurs facteurs, et cela ne se limite pas aux pannes de disque dur. Les systèmes à haute disponibilité doivent tenir compte de la sécurité des données en cas de panne.
- Réseau : les pannes de réseau non planifiées représentent un autre point de défaillance possible pour les systèmes à haute disponibilité. Il est important qu’une stratégie de réseau redondant soit en place pour les pannes éventuelles.
Quel logiciel peut être utilisé pour configurer la haute disponibilité ?
Chaque couche d’un système hautement disponible aura des besoins différents en termes de logiciel et de configuration. Cependant, au niveau de l’application, les équilibreurs de charge représentent un logiciel essentiel pour créer toute configuration de haute disponibilité.
HAProxy (High Availability Proxy) est un choix courant pour l’équilibrage de charge, car il peut gérer l’équilibrage de charge à plusieurs couches, et pour différents types de serveurs, y compris les serveurs de base de données.
En remontant dans la pile du système, il est important de mettre en œuvre une solution redondante fiable pour le point d’entrée de votre application, normalement l’équilibreur de charge. Pour supprimer ce point de défaillance unique, comme mentionné précédemment, nous devons mettre en œuvre un cluster d’équilibreurs de charge derrière une IP flottante. Corosync et Pacemaker sont des choix populaires pour créer une telle configuration, sur les serveurs Ubuntu et CentOS.
Conclusion
La haute disponibilité est un sous-ensemble important de l’ingénierie de la fiabilité, axé sur l’assurance qu’un système ou un composant a un haut niveau de performance opérationnelle dans une période donnée. À première vue, sa mise en œuvre peut sembler assez complexe ; cependant, elle peut apporter d’énormes avantages aux systèmes qui nécessitent une fiabilité accrue.