Je travaille beaucoup sur des choses liées à la norme ces derniers temps et il est temps d’en parler. Dans ce post, nous allons discuter de toute une famille de norme.
Qu’est-ce qu’une norme ?
Mathématiquement, une norme est une taille ou une longueur totale de tous les vecteurs dans un espace vectoriel ou des matrices. Pour simplifier, nous pouvons dire que plus la norme est élevée, plus la (valeur dans) la matrice ou le vecteur est grande. La norme peut se présenter sous de nombreuses formes et de nombreux noms, dont ces noms populaires : distance euclidienne, erreur quadratique moyenne, etc.
La plupart du temps, vous verrez la norme apparaître dans une équation comme celle-ci :
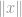 où
où  peut être un vecteur ou une matrice.
peut être un vecteur ou une matrice.
Par exemple, une norme euclidienne d’un vecteur 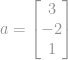 est
est 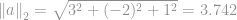 qui est la taille du vecteur
qui est la taille du vecteur 
L’exemple ci-dessus montre comment calculer une norme euclidienne, ou formellement appelée une 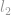 -norme. Il existe de nombreux autres types de normes qui dépassent notre explication ici, en fait pour chaque nombre réel unique, il y a une norme qui lui correspond (Remarquez le mot réel souligné, cela signifie qu’il n’est pas limité aux seuls nombres entiers.)
-norme. Il existe de nombreux autres types de normes qui dépassent notre explication ici, en fait pour chaque nombre réel unique, il y a une norme qui lui correspond (Remarquez le mot réel souligné, cela signifie qu’il n’est pas limité aux seuls nombres entiers.)
Formellement, la  -norme de
-norme de  est définie comme:
est définie comme:
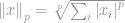 où
où 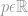
C’est tout ! Une p-ième racine d’une sommation de tous les éléments à la p-ième puissance est ce que nous appelons une norme.
Le point intéressant est que même si toutes les -normes sont toutes très similaires les unes aux autres, leurs propriétés mathématiques sont très différentes et donc leur application sont dramatiquement différentes aussi. Nous allons ici examiner certaines de ces normes en détail.
l0-norme
La première norme que nous allons aborder est une 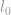 -norme. Par définition, la -norme de est
-norme. Par définition, la -norme de est
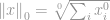
Strictement parlant, la -norme n’est pas réellement une norme. C’est une fonction de cardinalité qui a sa définition sous la forme de -norme, bien que beaucoup de gens l’appellent une norme. Il est un peu délicat de travailler avec elle car il y a une présence de la puissance zéro et de la racine zéro en elle. Il est évident que tout 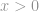 en deviendra un, mais les problèmes de définition de la puissance zéro et surtout de la racine zéro perturbent les choses ici. Donc, en réalité, la plupart des mathématiciens et des ingénieurs utilisent plutôt cette définition de la -norme:
en deviendra un, mais les problèmes de définition de la puissance zéro et surtout de la racine zéro perturbent les choses ici. Donc, en réalité, la plupart des mathématiciens et des ingénieurs utilisent plutôt cette définition de la -norme:
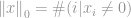
c’est un nombre total d’éléments non nuls dans un vecteur.
Parce que c’est un nombre d’élément non nul, il y a tellement d’applications qui utilisent la -norme. Dernièrement, elle est encore plus à l’honneur en raison de l’essor du schéma de détection compressive, qui tente de trouver la solution la plus spartiate du système linéaire sous-déterminé. La solution la plus éparse signifie la solution qui a le moins d’entrées non nulles, c’est-à-dire la plus petite -norme. Ce problème est généralement considéré comme un problème d’optimisation de la -norme ou -optimisation.
l0-optimisation
De nombreuses applications, y compris la détection compressive, essaient de minimiser la -norme d’un vecteur correspondant à certaines contraintes, d’où le nom de « -minimisation ». Un problème de minimisation standard est formulé comme suit :
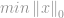 soumis à
soumis à 
Pour autant, le faire n’est pas une tâche facile. En raison de l’absence de représentation mathématique de la -norme, la -minimisation est considérée par les informaticiens comme un problème NP-hard, ce qui signifie simplement qu’il est trop complexe et presque impossible à résoudre.
Dans de nombreux cas, le problème de -minimisation est relaxé pour être un problème de norme d’ordre supérieur tel que la 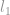 -minimisation et la -minimisation.
-minimisation et la -minimisation.
l1-norm
Suivant la définition de la norme, la -norme de est définie comme
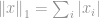
Cette norme est assez commune parmi la famille des normes. Elle a plusieurs noms et plusieurs formes parmi divers domaines, à savoir la norme Manhattan est son surnom. Si la -norme est calculée pour une différence entre deux vecteurs ou matrices, c’est-à-dire
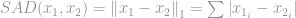
elle est appelée somme des différences absolues (SAD) chez les informaticiens de la vision.
Dans le cas plus général de la mesure de la différence de signal, elle peut être mise à l’échelle d’un vecteur unitaire par :
 où
où  est une taille de .
est une taille de .
qui est connue sous le nom d’erreur absolue moyenne (EAM).
l2-norm
La plus populaire de toutes les normes est la -norm. Elle est utilisée dans presque tous les domaines de l’ingénierie et de la science dans son ensemble. Suivant la définition de base, la -norme est définie comme
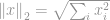
-norme est bien connue comme une norme euclidienne, qui est utilisée comme une quantité standard pour mesurer une différence vectorielle. Comme dans -norme, si la norme euclidienne est calculée pour une différence vectorielle, elle est connue comme une distance euclidienne:
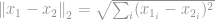
ou dans sa forme au carré, connue comme une somme de différence au carré (SSD) parmi les scientifiques de la vision par ordinateur :

Son application la plus connue dans le domaine du traitement du signal est la mesure de l’erreur quadratique moyenne (EQM), qui est utilisée pour calculer une similarité, une qualité ou une corrélation entre deux signaux. L’EQM est
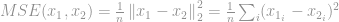
Comme nous l’avons vu précédemment dans la section -optimisation, en raison de nombreux problèmes tant du point de vue du calcul que du point de vue mathématique, de nombreux problèmes de -optimisation se détendent pour devenir plutôt des – et -optimisation. Pour cette raison, nous allons maintenant discuter de l’optimisation de .
l2-optimisation
Comme dans le cas de -optimisation, le problème de minimiser la -norme est formulé par
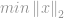 soumis à
soumis à
Supposons que la matrice de contrainte 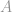 a un rang complet, ce problème est maintenant un système sous-déterminé qui a des solutions infinies. Le but dans ce cas est de tirer la meilleure solution, c’est-à-dire celle qui a la plus petite -norme, de ces infinies solutions. Ce travail pourrait être très fastidieux s’il devait être calculé directement. Heureusement, il est une astuce mathématique qui peut nous aider beaucoup dans ce travail.
a un rang complet, ce problème est maintenant un système sous-déterminé qui a des solutions infinies. Le but dans ce cas est de tirer la meilleure solution, c’est-à-dire celle qui a la plus petite -norme, de ces infinies solutions. Ce travail pourrait être très fastidieux s’il devait être calculé directement. Heureusement, il est une astuce mathématique qui peut nous aider beaucoup dans ce travail.
En utilisant une astuce de multiplicateurs de Lagrange, nous pouvons alors définir un Lagrangien

où  est le multiplicateur de Lagrange introduit. Prenez la dérivée de cette équation égale à zéro pour trouver une solution optimale et obtenir
est le multiplicateur de Lagrange introduit. Prenez la dérivée de cette équation égale à zéro pour trouver une solution optimale et obtenir
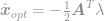
plongez cette solution dans la contrainte pour obtenir
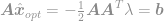
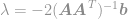
et enfin
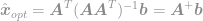
En utilisant cette équation, nous pouvons maintenant calculer instantanément une solution optimale du problème d’optimisation . Cette équation est bien connue sous le nom de pseudo-inverse de Moore-Penrose et le problème lui-même est généralement connu sous le nom de problème des moindres carrés, de régression des moindres carrés ou d’optimisation des moindres carrés.
Mais, même si la solution de la méthode des moindres carrés est facile à calculer, il n’est pas nécessaire d’être la meilleure solution. En raison de la nature lisse de la -norme elle-même, il est difficile de trouver une seule, meilleure solution pour le problème.

Au contraire, l’optimisation – peut fournir un bien meilleur résultat que cette solution.
l1-optimisation
Comme d’habitude, le problème de -minimisation est formulé comme
 soumis à
soumis à
Parce que la nature de la -norme n’est pas lisse comme dans le cas de la -norme, la solution de ce problème est bien meilleure et plus unique que la -optimisation.

Cependant, même si le problème de la -minimisation a presque la même forme que la -minimisation, il est beaucoup plus difficile à résoudre. Comme ce problème n’a pas de fonction lisse, l’astuce que nous avons utilisée pour résoudre le problème n’est plus valable. Le seul moyen qui reste pour trouver sa solution est de la chercher directement. La recherche de la solution signifie que nous devons calculer chaque solution possible pour trouver la meilleure dans le pool des « infiniment nombreuses » solutions possibles.
Puisqu’il n’y a pas de moyen facile de trouver la solution de ce problème mathématiquement, l’utilité de -optimisation est très limitée depuis des décennies. Jusqu’à récemment, le progrès des ordinateurs à haute puissance de calcul nous permet de « balayer » toutes les solutions. En utilisant de nombreux algorithmes utiles, à savoir l’algorithme d’optimisation convexe tel que la programmation linéaire, ou la programmation non linéaire, etc. il est maintenant possible de trouver la meilleure solution à cette question. De nombreuses applications qui s’appuient sur l’optimisation , notamment la détection compressive, sont maintenant possibles.
Il existe de nos jours de nombreuses boîtes à outils pour l’optimisation . Ces boîtes à outils utilisent généralement différentes approches et/ou algorithmes pour résoudre la même question. Les exemples de ces boîtes à outils sont l1-magic, SparseLab, ISAL1,
Maintenant que nous avons discuté de nombreux membres de la famille des normes, en commençant par la norme , la norme et la norme . Il est temps de passer à la suivante. Comme nous avons discuté au tout début qu’il peut y avoir n’importe quelle norme l-whatever suivant la même définition de base de la norme, cela va prendre beaucoup de temps pour parler de toutes ces normes. Heureusement, à part -, – , et -norm, les autres sont généralement peu communes et n’ont donc pas tant de choses intéressantes à regarder. Nous allons donc regarder le cas extrême de la norme qui est une 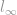 -norme (norme de l’infini).
-norme (norme de l’infini).
norme de l’infini
Comme toujours, la définition de la -norme est
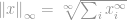
Maintenant cette définition semble encore une fois délicate, mais en fait elle est assez directe. Considérons le vecteur  , disons que si
, disons que si 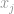 est l’entrée la plus élevée du vecteur , par la propriété même de l’infini, nous pouvons dire que
est l’entrée la plus élevée du vecteur , par la propriété même de l’infini, nous pouvons dire que
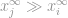

alors
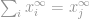
alors
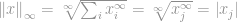
Maintenant nous pouvons simplement dire que la -norme est

c’est la magnitude des entrées maximales de ce vecteur. Cela a sûrement démystifié la signification de -norme
Maintenant nous avons discuté de toute la famille de norme de à , j’espère que cette discussion aiderait à comprendre la signification de la norme, ses propriétés mathématiques, et son implication dans le monde réel.
Référence et lecture complémentaire:
Norme mathématique – wikipedia
Norme mathématique – MathWorld
Michael Elad – « Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing » , Springer, 2010.
Programmation linéaire – MathWorld
Détection compressive – Rice University
Édition (15/02/15) : Correction d’imprécisions du contenu.