Tässä artikkelissa opimme tunnistamaan ja ratkaisemaan SQL Serverin indeksin pirstaloitumisen. Indeksin pirstaleisuuden tunnistaminen ja indeksin ylläpito ovat tärkeitä osia tietokannan ylläpitotehtävässä. Microsoft SQL Server päivittää indeksitilastoja jatkuvasti taulun Insert-, Update- tai Delete-aktiviteetin yhteydessä. Indeksin pirstoutuneisuus on indeksin suorituskykyarvo prosentteina, jotka voidaan hakea SQL Server DMV:llä. Indeksin suorituskykyarvon mukaan käyttäjät voivat ottaa indeksit ylläpitoon tarkistamalla pirstaloitumisprosenttia Rebuild- tai Reorganize-operaation avulla.
Miksi indeksin pirstaloitumisprosentti vaihtelee?
Indeksin pirstaloitumisprosentti vaihtelee, kun loogiset sivujärjestykset eivät sovi yhteen fyysisen sivujärjestyksen kanssa indeksin sivujakamisessa. Taulukon tietomuutoksella tietoja voidaan muuttaa tietosivun kokoa. Sivu oli ylitäynnä ennen taulukon päivitysoperaatiota. Tietosivulta löytyi kuitenkin vapaata tilaa taulukon päivitysoperaatiolla. Käyttäjät voivat tarkkailla häiritsevää sivun järjestystä taulukon massiivisella poisto-operaatiolla. Yhdessä päivitys- ja poisto-operaatioiden kanssa datasivu ei ole ylitäysi tai tyhjä sivu. Siksi käyttämätön vapaa tila lisää loogisen sivun ja fyysisen sivun välistä epäsuhtaa pirstaloitumisen lisääntyessä, mikä voi aiheuttaa huonoimman kyselyn suorituskyvyn ja kuluttaa myös enemmän palvelimen resursseja.
Olennaisempaa on täsmentää, että indeksin pirstaloituminen vaikuttaa kyselyn suorituskykyyn vain sivujen skannauksen yhteydessä. Tällaisissa tapauksissa se lisää myös muiden SQL-pyyntöjen huonon suorituskyvyn mahdollisuuksia, koska kysely, jonka taulukon indeksi on erittäin pirstaloitunut, vie enemmän aikaa suorittaa ja kuluttaa enemmän resursseja, kuten välimuistia, suorittimen ja IO:n resursseja. Näin ollen muiden SQL-pyyntöjen on vaikea suorittaa operaatiota loppuun epäjohdonmukaisilla palvelinresursseilla. Päivitys- ja poisto-operaatioissa voi esiintyä jopa estymistä, koska optimoija ei kerää tietoa indeksin pirstaleisuudesta, kun se luo kyselyn suoritussuunnitelmaa.
Yhdelle taululle voi olla luotu useita indeksejä, joissa on eri sarakkeiden yhdistelmä, ja kullakin indeksillä voi olla erilainen pirstaleisuusprosentti. Nyt, ennen kuin se tehdään tarkoituksenmukaiseksi tai indeksin ottamista ylläpitoon, käyttäjien on löydettävä kyseinen kynnysarvo tietokannasta. Alla oleva T-SQL-lause on tehokas tapa löytää se objektin yksityiskohdilla.
Find Index Fragmentation status using the T-SQL-lause
|
1
2
3
4
5
6
. name as ’Schema’, T.name as ’Table’,
I.name as ’Index’,
DDIPS.avg_fragmentation_in_percent,
DDIPS.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL, NULL) AS DDIPS
INNER JOIN sys.tables T on T.object_id = DDIPS.object_id
INNER JOIN sys.schemas S on T.schema_id = S.schema_id
INNER JOIN sys.indexes I ON I.object_id = DDIPS.object_id
AND DDIPS.index_id = I.index_id
WHERE DDIPS.database_id = DB_ID()
and I.name is not null
AND DDIPS.avg_fragmentation_in_percent > 0
ORDER BY DDIPS.avg_fragmentation_in_percent desc
|
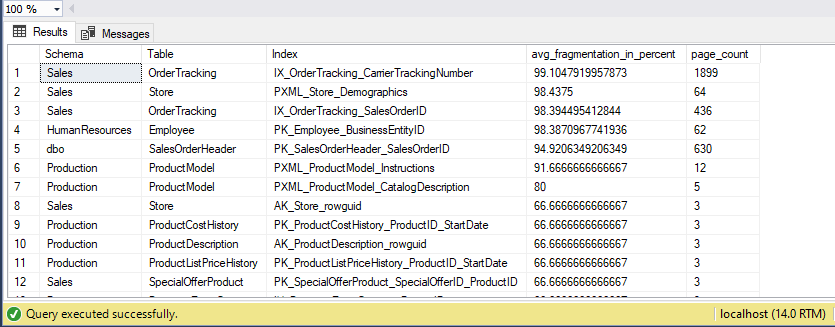
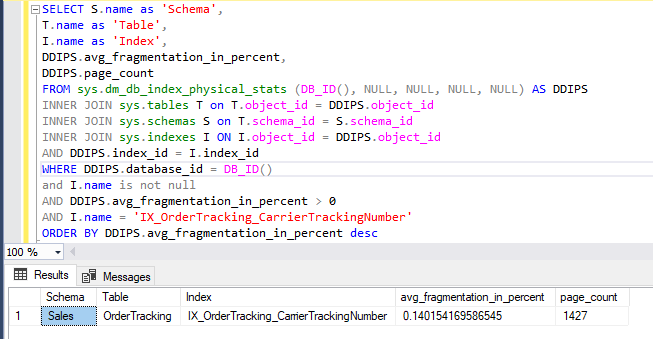
Tässä nähdään, että suurin keskimääräinen pirstoutumisprosenttiosuus on havaittavissa 99 %:n suuruisena, mikä on kytkettävä toimenpiteellä, jolla pyritään pienentämään pirstoutuneisuutta valinnoilla REBUILD (uudelleenrakentaminen) tai REORGANIZE (uudelleenjärjestäminen). REBUILD tai REORGANIZE on indeksin ylläpitokomento, joka voidaan suorittaa ALTER INDEX -lausekkeen kanssa. Käyttäjät voivat suorittaa tämän komennon myös SSMS:n avulla.
Rebuild and Reorganize Index using SQL Server Management Studio (SSMS)
Etsi ja laajenna taulukko Object Explorerissa >> Avaa indeksit >> Napsauta hiiren kakkospainikkeella kohdeindeksiä >> Rebuild or Reorganize.
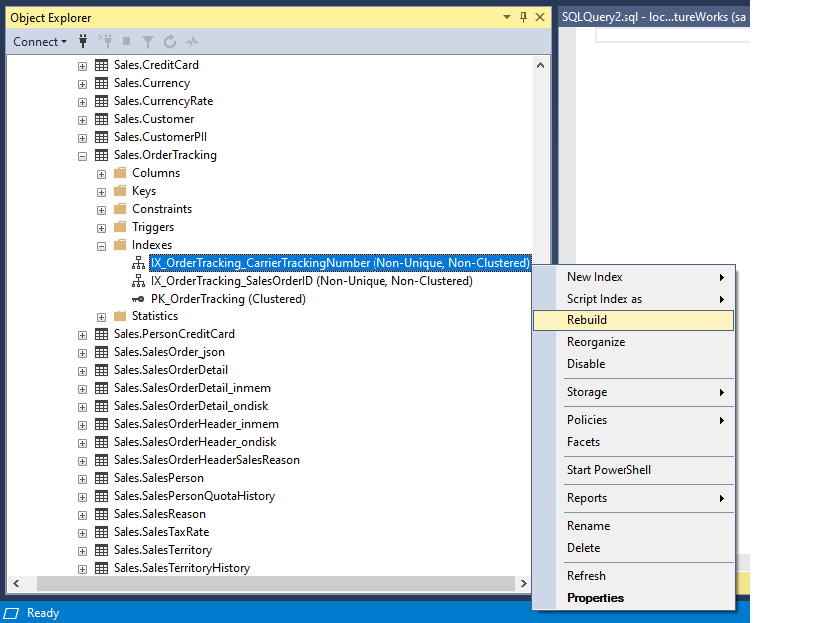
Kuten yllä olevasta kuvasta näkyy, REBUILD (Uudelleenrakentaminen) ja REORGANIZE (Uudelleenjärjestäminen) ovat kaksi käytettävissä olevaa vaihtoehtoa, joiden avulla trimmausoperaatio voidaan suorittaa sivulla. Ihannetapauksessa tämä operaatio olisi suoritettava ruuhka-ajan ulkopuolella, jotta se ei vaikuttaisi muihin tapahtumiin ja käyttäjiin. Microsoft SQL Server Enterprise Edition tukee indeksin online- ja offline-ominaisuuksia indeksin REBUILDin avulla.
REBUILD INDEX
INDEX REBUILD pudottaa aina indeksin ja toistaa sen uusilla indeksisivuilla. Tämä toiminto voidaan suorittaa rinnakkain käyttämällä online-vaihtoehtoa (Enterprise Edition) ALTER INDEX -komennolla, mikä ei vaikuta samanlaisen taulukon käynnissä oleviin pyyntöihin ja tehtäviin.
REBUILD Indeksi voidaan asettaa online- tai offline-tilassa alla olevilla SQL-komennoilla:-REBUILD Index with ONLINE OPTION
Jos käyttäjä suorittaa REBUILD INDEX offline, indeksin objektiresurssi (taulukko) ei ole käytettävissä ennen REBUILD-prosessin päättymistä. Se vaikuttaa myös lukuisiin muihin tapahtumiin, jotka liittyvät tähän objektiin. Rebuild index -operaatio luo indeksin uudelleen. Siksi se luo uusia tilastoja ja liittää indeksin lokitietueet myös tietokannan tapahtumalokitiedostoon.
Otetaan esimerkiksi ennen indeksin uudelleenrakentamista AdventureWorks-tietokannan, Sales.OrderTracking-taulukon ja IX_OrderTracking_CarrierTrackingNumber-nimisen indeksin indeksin nykyinen sivumäärä.object_id) as db_name, si.name, extent_page_id, allocated_page_page_id, previous_page_page_id, next_page_page_id
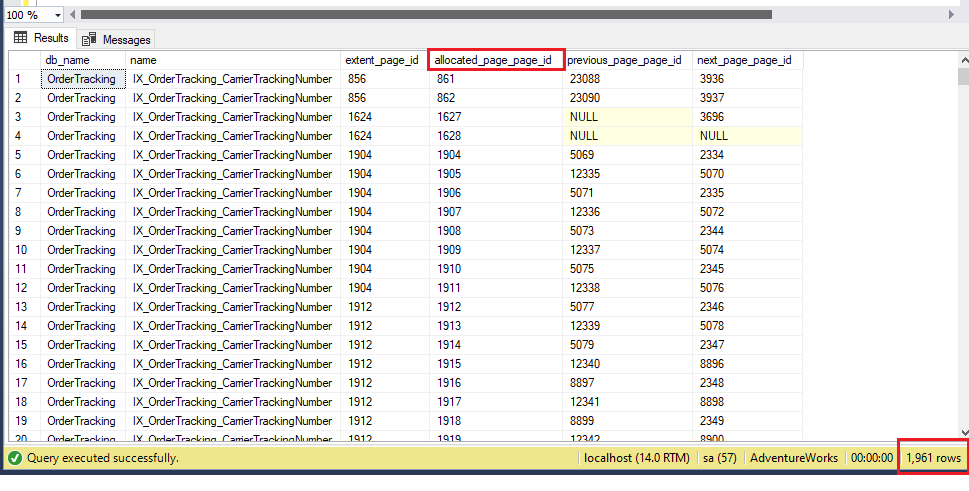
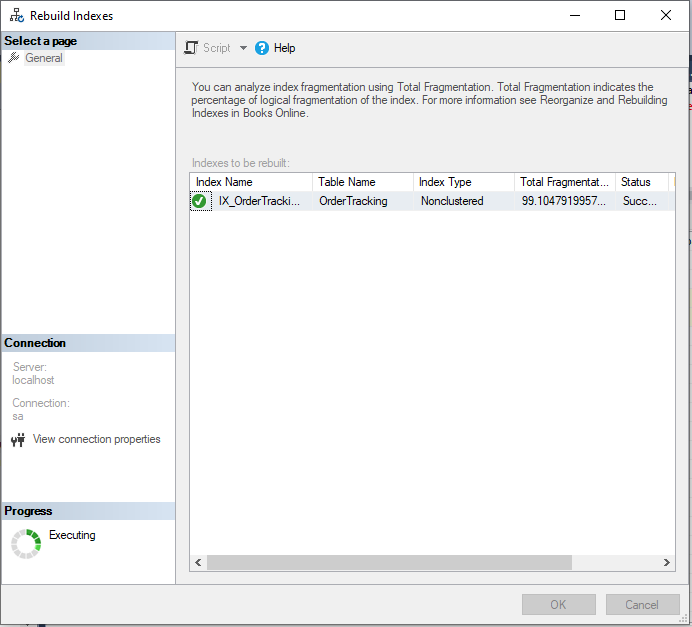
Here, Tämän indeksin tietokantatiedostossa on 1961 sivua, ja viisi ensimmäistä sivua ovat sivunumeron mukaisessa järjestyksessä sivut 861, 862, 1627, 1628 ja 1904. Rakennetaan nyt indeksi uudelleen SSMS:n avulla.
Indeksin REBUILD-operaatio on suoritettu onnistuneesti ja otetaan saman indeksin sivunjakoviitteet uudelleen saman T-SQL-kyselyn avulla.object_id) as db_name, si.name, extent_page_id, allocated_page_page_id,
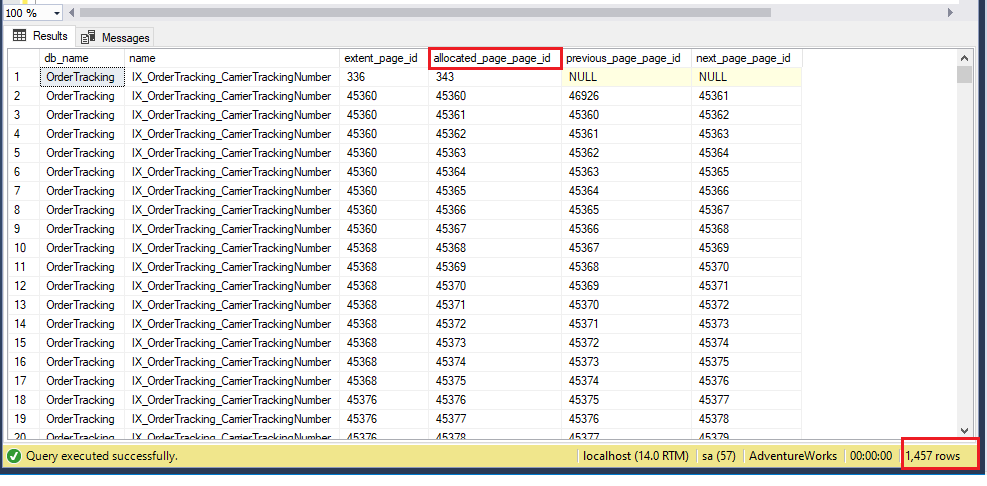
Indeksin uudelleenrakentamisen jälkeen indeksin päivitetty sivuluku on 1457, joka oli aiemmin 1961. Jos tarkistat saman indeksin 5 ensimmäistä varattua sivua, se on muuttunut uusilla sivuviittauksilla. Se olettaa, että indeksi on pudotettu ja tehty uudelleen. Tarkistetaan saman indeksin päivitetty pirstoutumisprosentti, ja kuten alla näkyy, se on nyt 0,1 %.
Taulukon REBUILD-klusteroitu indeksi vaikuttaa myös muihin taulukon indekseihin, koska REBUILD-klusteroitu indeksi rakentaa uudelleen myös taulukon ei-klusteroidun indeksin. Suorita uudelleenrakennusoperaatio kaikille taulun tai tietokannan indekseille yhdessä; käyttäjä voi käyttää DBCC DBREINDEX()-käskyä.
|
1
|
DBCC DBREINDEX (’TietokannanNimi’, ’TaulunNimi’);
|
REORGANIZED INDEX
REORGANIZE INDEX -komento järjestää indeksisivun uudelleen karkottamalla sivulta vapaata tai käyttämätöntä tilaa. Ihannetapauksessa indeksisivut järjestetään uudelleen fyysisesti datatiedostossa. REORGANIZE-komennolla ei pudoteta ja luoda indeksiä, vaan ainoastaan järjestetään sivun tiedot uudelleen. REORGANIZE-vaihtoehdossa ei ole offline-valintaa, eikä REORGANIZE vaikuta tilastoihin verrattuna REBUILD-vaihtoehtoon. REORGANIZE suoritetaan aina verkossa.
Otetaan esimerkiksi ennen REORGANIZE:n suorittamista indeksille tietokannan ’AdventureWorks’, taulun ’Sales.OrderTracking’ ja indeksin nimeltä ’IX_OrderTracking_SalesOrderID’ pirstaloitumislukema.
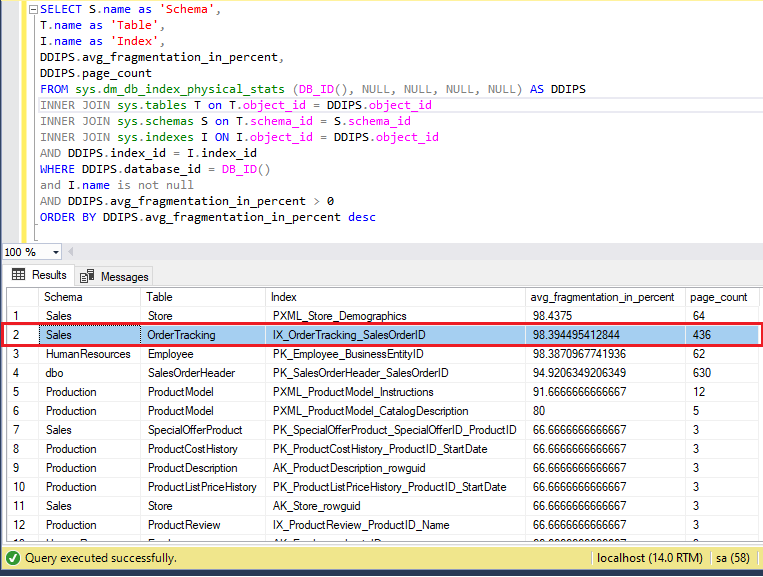
Tässä indeksin pirstaloitumisprosenttiosuus ennen REORGANIZE:a on 98,39. object_id) as db_name, si.name, extent_page_id, allocated_page_page_id,
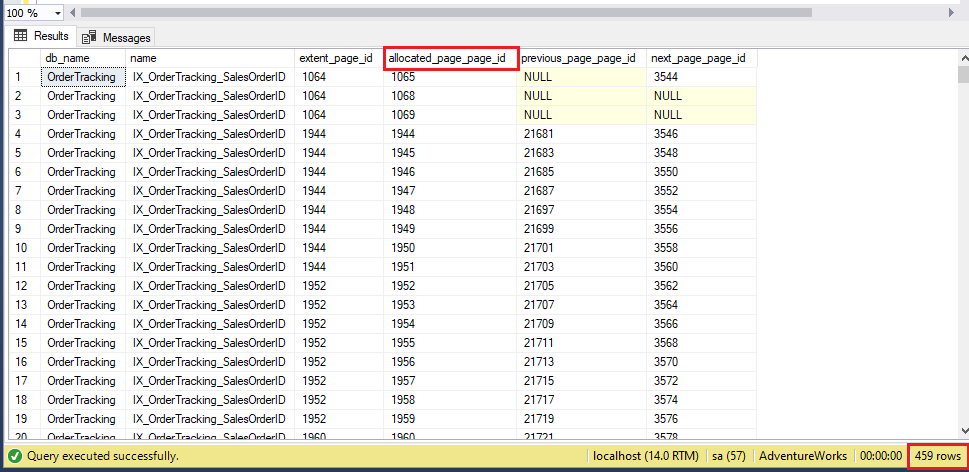
Tässä ylläolevassa kuvassa on lueteltu kaikkiaan 459 sivua, ja ensimmäiset viisi sivua ovat 1065, 1068, 1069, 1944 ja 1945. Suoritetaan nyt REORGANIZE-komento indeksille alla olevalla T-SQL-lausekkeella ja tarkastellaan sivunjakoa uudelleen.
|
1
|
ALTER INDEX IX_OrderTracking_SalesOrderID ON Sales.OrderTracking REORGANIZE
|
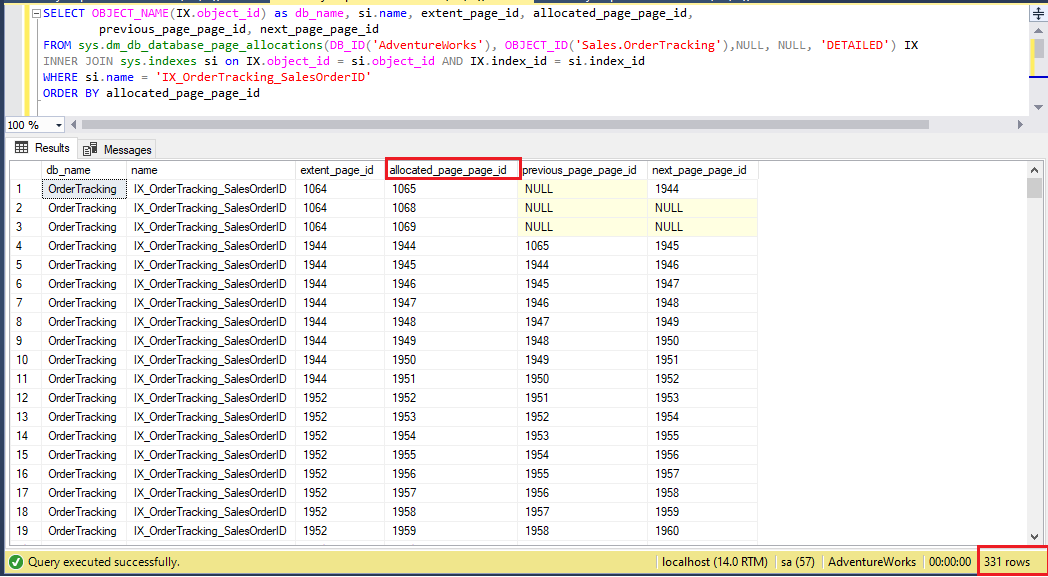
Tässä kokonaissivumäärä vähenee 331:een, joka oli aiemmin 459. Lisäksi emme näe uusia sivuja viiden ensimmäisen sivun luettelossa, mikä viittaa siihen, että tiedot on vain järjestetty uudelleen – ei täytetty uudelleen. Vaikka uusia sivuja voisi myös nähdä, se tapahtuu tilanteessa, jossa iso indeksi on voimakkaasti pirstaloitunut, ja tietojen uudelleenjärjestäminen käyttää uutta sivua.
Käyttäjä voi suorittaa REORGANIZE-indeksioperaation kaikille taulun tai tietokannan indekseille yhdessä käyttämällä komentoa DBCC INDEXDEFRAG():
|
1
|
DBCC INDEXDEFRAG(’TietokannanNimi’, ’TaulukonNimi’);
|
Kuten nähdään, indeksin REBUILD- ja REORGANIZE-käytäntöjen välille jää huomattava ero. Tässä käyttäjät voivat valita jommankumman vaihtoehdon indeksin pirstoutumisprosentin mukaan. Ymmärrämme, että dokumentoituja standardeja ei ole olemassa; tietokannan ylläpitäjä noudattaa kuitenkin vakioyhtälöä indeksin koon ja tietotyypin vaatimusten mukaisesti.
Yhtälön käytön tavanomainen määrittely :
- Kun fragmentaatioprosentti on välillä 15-30: REORGANIZE
- Kun fragmentaatio on yli 30: REBUILD
REBUILD-vaihtoehto on hyödyllisempi ONLINE-vaihtoehdon kanssa, kun tietokanta ei ole käytettävissä indeksin ylläpitoa varten ruuhka-aikojen ulkopuolella.
Johtopäätökset
Indeksin fragmentaatio on datatiedoston sisäinen pirstoutuminen. Tietokannan nopean suorituskyvyn ydinparametrit ovat tietokanta-arkkitehtuuri, tietokannan suunnittelu ja kyselyjen kirjoittaminen. Hyvä indeksisuunnittelu ylläpitoineen parantaa aina tietokantamoottorin kyselysuorituskykyä.
- Author
- Recent Posts

View all posts by Jignesh Raiyani
- Page Life Expectancy (PLE) in SQL Server – July 17, 2020
- Taulukoiden osioinnin automatisointi SQL Serverissä – 7. heinäkuuta 2020
- SQL Serverin Always On -saatavuusryhmien määrittäminen AWS EC2:ssa – 6. heinäkuuta 2020