Esittely
Kriittisiä järjestelmiä palvelemaan suunniteltujen luotettavien ja suorituskykyisten infrastruktuurien kasvaneen kysynnän myötä termit skaalautuvuus ja korkea saatavuus eivät voisi olla suositumpia. Vaikka lisääntyneen järjestelmäkuormituksen käsittely on yleinen huolenaihe, käyttökatkosten vähentäminen ja yksittäisten vikapisteiden poistaminen ovat yhtä tärkeitä. Korkea käytettävyys on skaalautuvan infrastruktuurin suunnittelun laatu, joka ottaa huomioon nämä jälkimmäiset näkökohdat.
Tässä oppaassa keskustelemme siitä, mitä korkea käytettävyys tarkalleen ottaen tarkoittaa ja miten se voi parantaa infrastruktuurisi luotettavuutta.
Mitä on korkea käytettävyys?
Laskennassa käytettävyydellä kuvataan ajanjaksoa, jonka aikana palvelu on käytettävissä, sekä aikaa, jonka järjestelmä tarvitsee vastatakseen käyttäjän esittämään pyyntöön. Korkea käytettävyys on järjestelmän tai komponentin ominaisuus, joka takaa korkean operatiivisen suorituskyvyn tietyn ajanjakson ajan.
Käytettävyyden mittaaminen
Käytettävyys ilmaistaan usein prosenttiosuutena, joka osoittaa, kuinka paljon käytettävyyttä odotetaan tietylta järjestelmältä tai komponentilta tietyllä ajanjaksolla, jolloin arvo 100 % merkitsisi, että järjestelmä ei koskaan vikaannu. Esimerkiksi järjestelmässä, joka takaa 99 %:n käytettävyyden yhden vuoden aikana, voi olla enintään 3,65 päivää seisokkiaikaa (1 %).
Nämä arvot lasketaan useiden tekijöiden perusteella, mukaan lukien sekä suunnitellut että suunnittelemattomat huoltojaksot sekä aika, joka kuluu järjestelmän mahdollisesta vikaantumisesta toipumiseen.
Miten korkea käytettävyys toimii?
Korkea käytettävyys toimii infrastruktuurin vikaantumisreagointijärjestelmänä. Toimintatapa on käsitteellisesti melko yksinkertainen, mutta vaatii tyypillisesti jonkin verran erikoisohjelmistoja ja -määrityksiä.
Milloin korkea käytettävyys on tärkeää?
Vahvoja tuotantojärjestelmiä perustettaessa seisokkiaikojen ja palvelukeskeytysten minimointi on usein ensisijaisen tärkeää. Riippumatta siitä, kuinka luotettavia järjestelmät ja ohjelmistot ovat, voi esiintyä ongelmia, jotka voivat kaataa sovelluksesi tai palvelimesi.
Hyvän käytettävyyden toteuttaminen infrastruktuurissasi on hyödyllinen strategia tällaisten tapahtumien vaikutusten vähentämiseksi. Korkean käytettävyyden järjestelmät voivat toipua palvelin- tai komponenttivioista automaattisesti.
Mikä tekee järjestelmästä korkean käytettävyyden?
Yksi korkean käytettävyyden tavoitteista on yksittäisten vikapisteiden poistaminen infrastruktuuristasi. Yksittäinen vikaantumispiste on teknologiapinon komponentti, joka aiheuttaisi palvelukatkoksen, jos se ei olisi käytettävissä. Näin ollen mitä tahansa komponenttia, joka on välttämätön sovelluksen asianmukaisen toiminnan kannalta ja jota ei ole redundantoitu, pidetään yksittäisenä vikaantumispisteenä.
Yksittäisten vikaantumispisteiden eliminoimiseksi jokainen pinon kerros on valmisteltava redundanssin varalta.
Yksittäisten vikaantumispisteiden eliminoimiseksi jokainen pino on valmisteltava redundanssin varalta. Kuvittele esimerkiksi, että sinulla on infrastruktuuri, joka koostuu kahdesta identtisestä, redundantista verkkopalvelimesta kuormantasaajan takana. Asiakkailta tuleva liikenne jakautuu tasaisesti verkkopalvelimien kesken, mutta jos toinen palvelimista kaatuu, kuorman tasaaja ohjaa kaiken liikenteen jäljelle jäävälle verkkopalvelimelle.
Verkkopalvelinkerros ei tässä skenaariossa ole yksittäinen vikaantumispiste, koska:
- redundantit komponentit samaa tehtävää varten
- kerroksen päällä oleva mekanismi (kuormanpainotin) pystyy havaitsemaan komponenttien vikaantumiset ja mukauttamaan käyttäytymistään oikea-aikaista toipumista varten
Mutta mitä tapahtuu, jos kuormanpainotin menee pois käytöstä?
Kuvatussa skenaariossa, joka ei ole harvinainen tosielämässä, kuormanjakokerros itsessään jää yksittäiseksi vikapisteeksi. Tämän jäljelle jäävän yksittäisen vikaantumispisteen poistaminen voi kuitenkin olla haastavaa; vaikka voit helposti määrittää ylimääräisen kuormantasaajan redundanssin aikaansaamiseksi, kuormantasaajien yläpuolella ei ole ilmeistä kohtaa vian havaitsemisen ja toipumisen toteuttamiseksi.
Redundanssilla yksinään ei voida taata korkeaa käytettävyyttä. On oltava käytössä mekanismi vikojen havaitsemiseksi ja toimenpiteisiin ryhtymiseksi, kun jokin pinon komponenteista ei ole käytettävissä.
Redundanttien järjestelmien vikojen havaitseminen ja toipuminen voidaan toteuttaa ylhäältä alas -lähestymistavalla: ylhäällä oleva kerros tulee vastuulliseksi tarkkailemaan välittömästi sen alapuolella olevaa kerrosta vikojen varalta. Edellisessä esimerkkiskenaariossamme kuorman tasaaja on ylin kerros. Jos jokin verkkopalvelimista (alempi kerros) ei ole käytettävissä, kuorman tasaaja lopettaa pyyntöjen ohjaamisen kyseiselle palvelimelle.
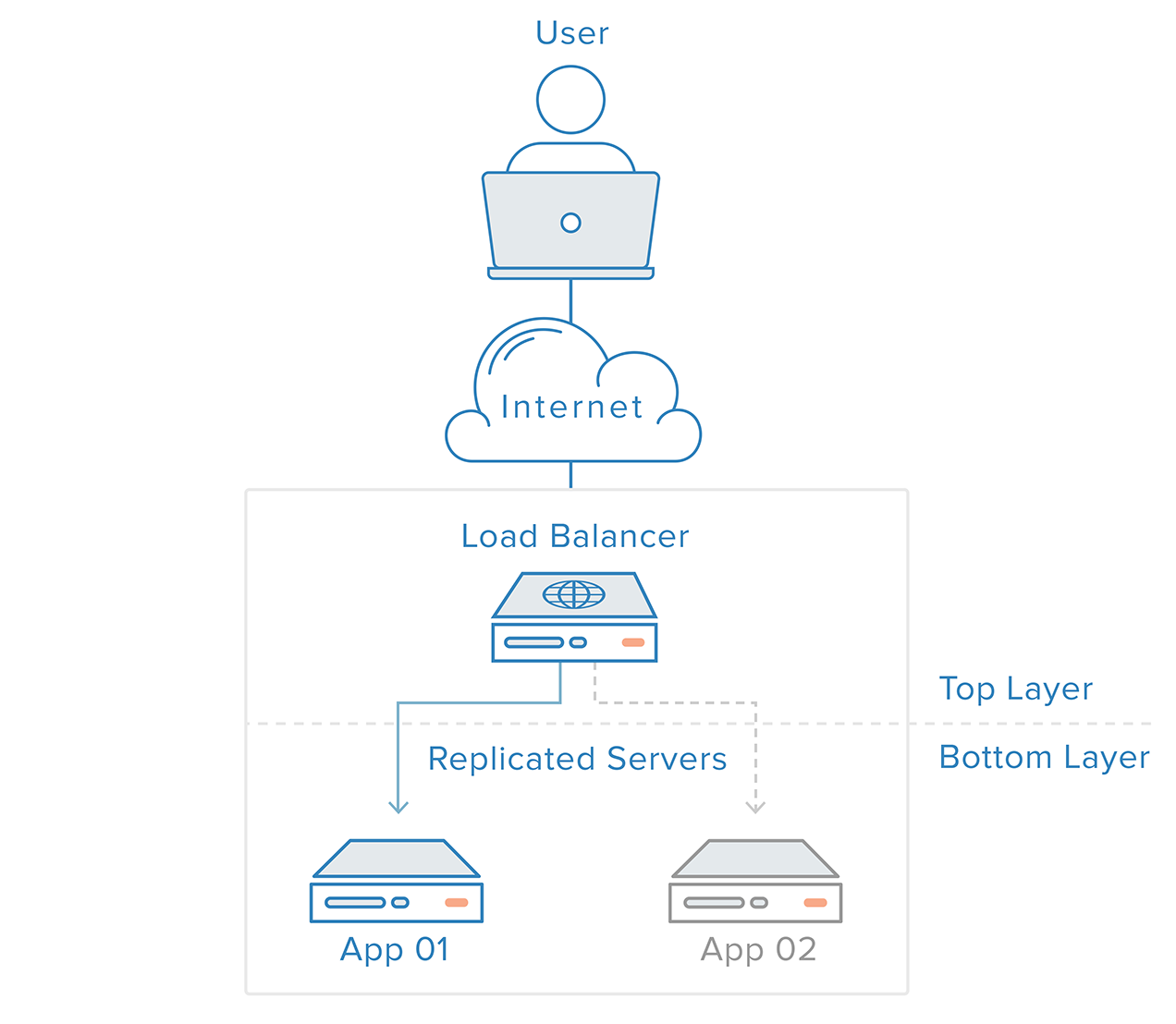
Tämä lähestymistapa on yleensä yksinkertaisempi, mutta sillä on rajoituksensa: infrastruktuurissasi on kohta, jossa ylin kerros on joko olematon tai tavoittamattomissa, mikä on tilanne kuormanpainotuskerroksessa. Kuormantasaajan vianmäärityspalvelun luominen ulkoiseen palvelimeen loisi yksinkertaisesti uuden yksittäisen vikapisteen.
Tällaisessa skenaariossa tarvitaan hajautettua lähestymistapaa. Useita redundantteja solmuja on liitettävä yhteen klusteriksi, jossa jokaisen solmun on kyettävä yhtä hyvin havaitsemaan ja korjaamaan vikaantuminen.
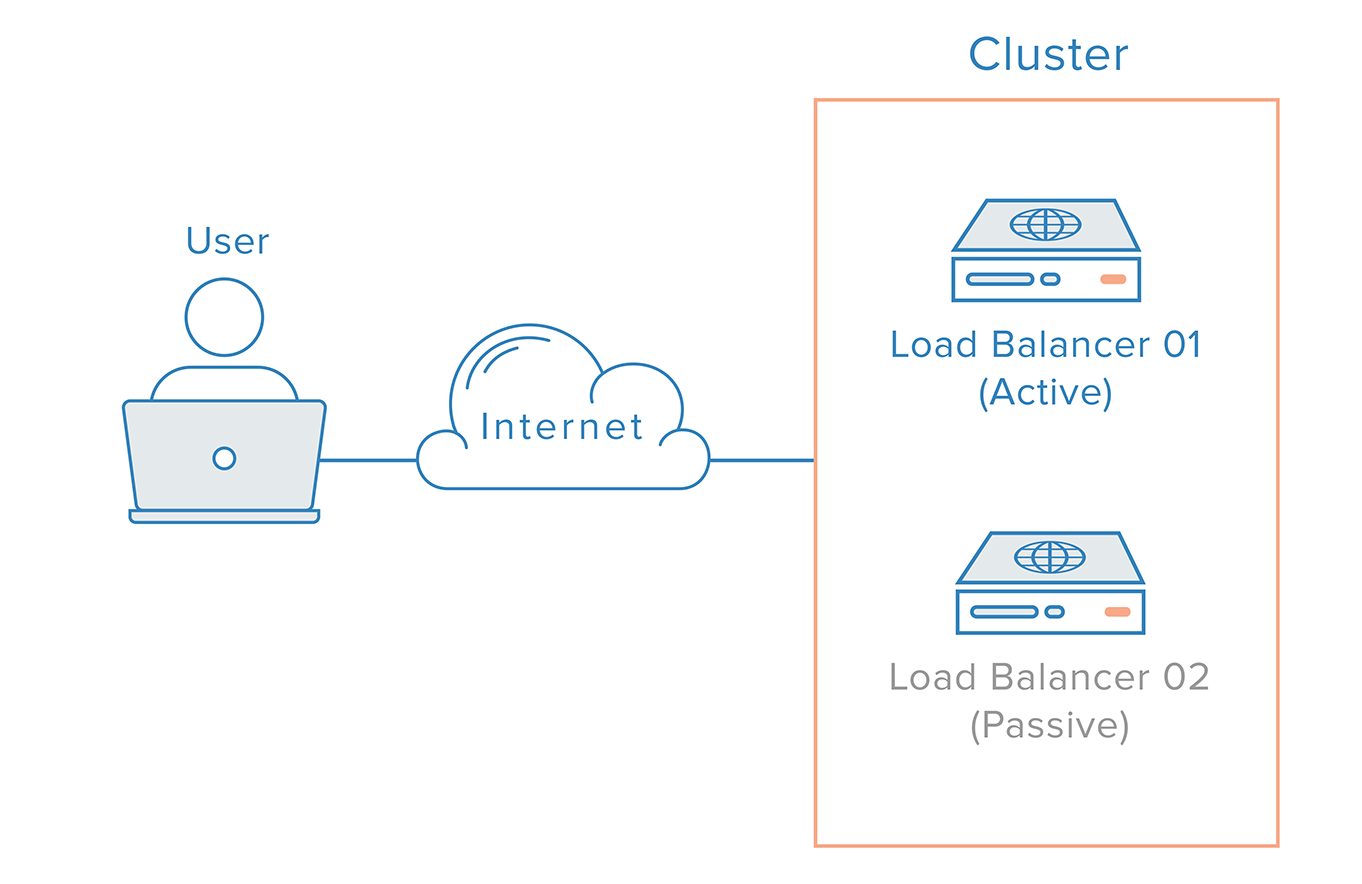
Kuormantasaustapauksessa on kuitenkin lisäkomplikaatio, joka johtuu nimipalvelimien toimintatavasta. Kuormantasaajan vikaantumisesta toipuminen tarkoittaa tyypillisesti siirtymistä redundanttiin kuormantasaajan käyttöön, mikä tarkoittaa, että DNS-muutos on tehtävä, jotta verkkotunnus voidaan osoittaa redundantin kuormantasaajan IP-osoitteeseen. Tällaisen muutoksen leviäminen Internetissä voi kestää huomattavan kauan, mikä aiheuttaisi tälle järjestelmälle vakavan käyttökatkoksen.
Mahdollinen ratkaisu on käyttää DNS-kuormantasauksen round-robin-toimintoa. Tämä lähestymistapa ei kuitenkaan ole luotettava, koska se jättää vikasietoisuuden siirtämisen asiakassovelluksen tehtäväksi.
Kestävämpi ja luotettavampi ratkaisu on käyttää järjestelmiä, jotka mahdollistavat joustavan IP-osoitteiden uudelleenkohdentamisen, kuten kelluvat IP-osoitteet. Tarvittaessa tapahtuva IP-osoitteen uudelleenkartoitus eliminoi DNS-muutoksiin liittyvät leviämis- ja välimuistiongelmat tarjoamalla staattisen IP-osoitteen, joka voidaan tarvittaessa helposti vaihtaa uudelleen. Verkkotunnus voi pysyä liitettynä samaan IP-osoitteeseen, kun taas itse IP-osoite siirretään palvelimien välillä.
Tältä näyttää Floating IP:tä käyttävä korkean käytettävyyden infrastruktuuri:

Mitä järjestelmäkomponentteja korkean käytettävyyden toteuttaminen edellyttää?
On olemassa useita komponentteja, jotka on otettava tarkkaan huomioon, jotta korkea käytettävyys voidaan toteuttaa käytännössä. Paljon enemmän kuin ohjelmistototeutus, korkea saatavuus riippuu muun muassa seuraavista tekijöistä:
- Ympäristö: Jos kaikki palvelimesi sijaitsevat samalla maantieteellisellä alueella, ympäristöolosuhteet, kuten maanjäristys tai tulva, voivat kaataa koko järjestelmän. Luotettavuutta lisää se, että käytössäsi on redundantteja palvelimia eri konesaleissa ja eri maantieteellisillä alueilla.
- Laitteisto: Korkean käytettävyyden palvelimien tulisi kestää sähkökatkoksia ja laitteistovikoja, kuten kiintolevyjä ja verkkoliitäntöjä.
- Ohjelmistot: Koko ohjelmistopinon, mukaan lukien käyttöjärjestelmä ja itse sovellus, on oltava valmistautunut käsittelemään odottamattomia vikoja, jotka voivat mahdollisesti vaatia esimerkiksi järjestelmän uudelleenkäynnistystä.
- Data: Tiedon häviäminen ja epäjohdonmukaisuus voi johtua useista tekijöistä, eikä se rajoitu pelkästään kiintolevyvikoihin. Korkean käytettävyyden järjestelmissä on otettava huomioon tietojen turvallisuus vikatilanteissa.
- Verkko: Suunnittelemattomat verkkokatkokset ovat toinen mahdollinen vikapiste korkean käytettävyyden järjestelmille. On tärkeää, että käytössä on redundantti verkkostrategia mahdollisten vikojen varalta.
Mitä ohjelmistoja voidaan käyttää korkean käytettävyyden konfigurointiin?
Kullakin korkean käytettävyyden järjestelmän kerroksella on erilaiset tarpeet ohjelmistojen ja konfiguroinnin suhteen. Sovellustasolla kuorman tasaajat ovat kuitenkin olennainen osa ohjelmistoa minkä tahansa korkean käytettävyyden kokoonpanon luomisessa.
HAProxy (High Availability Proxy, korkean saatavuuden välityspalvelin) on yleinen valinta kuorman tasaamiseen, sillä se pystyy hoitamaan kuorman tasaamisen useilla kerroksilla ja erityyppisille palvelimille, mukaan lukien tietokantapalvelimet.
Korkeammalle järjestelmäpinossa siirryttäessä on tärkeää ottaa käyttöön luotettava redundanttiratkaisu sovelluksen sisääntulopisteeseen, joka on tavallisesti kuorman tasaajan. Tämän yksittäisen vikapisteen poistamiseksi, kuten aiemmin mainittiin, meidän on toteutettava kuorman tasaajien klusteri Floating IP:n takana. Corosync ja Pacemaker ovat suosittuja vaihtoehtoja tällaisen kokoonpanon luomiseen sekä Ubuntu- että CentOS-palvelimilla.
Johtopäätös
Korkea käytettävyys on tärkeä luotettavuussuunnittelun osa-alue, jossa keskitytään sen varmistamiseen, että järjestelmän tai komponentin toiminnallinen suorituskyky on korkealla tasolla tiettynä ajanjaksona. Ensisilmäyksellä sen toteuttaminen saattaa vaikuttaa melko monimutkaiselta, mutta se voi kuitenkin tuoda valtavia hyötyjä järjestelmille, jotka vaativat lisääntynyttä luotettavuutta.