Käsittelen normiin liittyviä asioita paljon viime aikoina ja on aika puhua siitä. Tässä postauksessa keskustelemme koko normiperheestä.
Mikä on normi?
Matemaattisesti normi on vektoriavaruuden tai matriisien kaikkien vektoreiden yhteenlaskettu koko tai pituus. Yksinkertaisuuden vuoksi voidaan sanoa, että mitä suurempi normi on, sitä suurempi (arvo) matriisi tai vektori on. Normi voi esiintyä monessa muodossa ja monella nimellä, kuten näillä suosituilla nimillä: Euklidinen etäisyys, keskineliövirhe jne.
Viimeisimmin normi esiintyy tällaisessa yhtälössä:
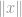 missä
missä  voi olla vektori tai matriisi.
voi olla vektori tai matriisi.
Etuklidinen normi esimerkiksi vektorille 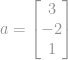 on
on 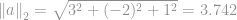 , joka on vektorin
, joka on vektorin
Yllä oleva esimerkki osoittaa, miten lasketaan euklidinen normi eli muodollisesti 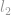 -normi. On olemassa monia muita normityyppejä, joita emme voi selittää tässä, itse asiassa jokaiselle reaaliluvulle on olemassa sitä vastaava normi (Huomaa korostettu sana reaaliluku, joka tarkoittaa, että se ei rajoitu vain kokonaislukuihin.)
-normi. On olemassa monia muita normityyppejä, joita emme voi selittää tässä, itse asiassa jokaiselle reaaliluvulle on olemassa sitä vastaava normi (Huomaa korostettu sana reaaliluku, joka tarkoittaa, että se ei rajoitu vain kokonaislukuihin.)
Formallisesti  -normi
-normi  :lle määritellään seuraavasti:
:lle määritellään seuraavasti:
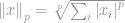 missä
missä 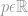
Siinä se! Kaikkien alkioiden yhteenlaskun p:nnen potenssin p:nnen potenssiin on se, mitä kutsumme normiksi.
Erityisen mielenkiintoista on se, että vaikka kaikki -normit näyttävät hyvin samankaltaisilta, niiden matemaattiset ominaisuudet ovat hyvin erilaiset ja näin ollen myös niiden sovellukset ovat dramaattisesti erilaisia. Seuraavassa tarkastelemme joitakin näistä normeista yksityiskohtaisesti.
l0-normi
Ensimmäinen normi, jota käsittelemme, on 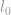 -normi. Määritelmän mukaan :n -normi on
-normi. Määritelmän mukaan :n -normi on
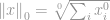
Suoraan ottaen -normi ei varsinaisesti ole normi. Se on kardinaalisuusfunktio, jonka määritelmä on muodossa -normi, vaikka monet kutsuvatkin sitä normiksi. Sen kanssa on hieman hankala työskennellä, koska siinä esiintyy nollapotentiaalia ja nollajuurta. Ilmeisesti mistä tahansa 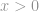 :stä tulee sellainen, mutta nollavoiman ja erityisesti nollan juuren määritelmään liittyvät ongelmat sotkevat asioita tässä. Niinpä todellisuudessa useimmat matemaatikot ja insinöörit käyttävät sen sijaan tätä -normin määritelmää:
:stä tulee sellainen, mutta nollavoiman ja erityisesti nollan juuren määritelmään liittyvät ongelmat sotkevat asioita tässä. Niinpä todellisuudessa useimmat matemaatikot ja insinöörit käyttävät sen sijaan tätä -normin määritelmää:
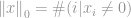
Se on nollasta poikkeavien elementtien kokonaislukumäärä vektorissa.
Koska se on nollasta poikkeavien elementtien lukumäärä, on niin monia sovelluksia, jotka käyttävät -normia. Viime aikoina se on vieläkin enemmän esillä, koska nousu Compressive Sensing järjestelmä, joka on yrittää löytää harvinaisin ratkaisu alideterminoituun lineaariseen järjestelmään. Harvinaisin ratkaisu tarkoittaa ratkaisua, jossa on vähiten nollasta poikkeavia merkintöjä eli pienin -normi. Tätä ongelmaa pidetään yleensä -normin optimointiongelmana tai -optimointiongelmana.
l0-optimointi
Monissa sovelluksissa, kuten kompressiivisessa sensoinnissa, yritetään minimoida joidenkin rajoitusten mukaisen vektorin -normia, mistä käytetään nimitystä ”-minimointi”. Tavallinen minimointiongelma muotoillaan seuraavasti:
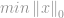 subject to
subject to 
Mutta sen tekeminen ei ole helppo tehtävä. Koska -normin matemaattisen esityksen puuttuessa -minimointia pidetään tietojenkäsittelytieteilijöiden keskuudessa NP-vaikeana ongelmana, mikä kertoo yksinkertaisesti siitä, että se on liian monimutkainen ja lähes mahdoton ratkaista.
Monissa tapauksissa -minimointiongelma relaksoidaan korkeamman asteen normiongelmaksi, kuten 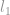 -minimointi ja -minimointi.
-minimointi ja -minimointi.
l1-normi
Normin määritelmää noudattaen -normi määritellään seuraavasti:
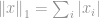
Tämä normi on varsin yleinen normiperheen keskuudessa. Sillä on monta nimeä ja monta muotoa eri alojen keskuudessa, nimittäin Manhattan-normi on sen lempinimi. Jos -normi lasketaan kahden vektorin tai matriisin erotukselle, eli
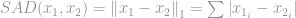
sitä kutsutaan tietokonenäön tutkijoiden keskuudessa Sum of Absolute Difference (SAD).
Yleisemmässä tapauksessa signaalien eron mittauksessa se voidaan skaalata yksikkövektoriin seuraavasti:
 missä
missä  on koko .
on koko .
jota kutsutaan nimellä Mean-Absolute Error (MAE).
l2-normi
Normista suosituin on -normi. Sitä käytetään lähes kaikilla tekniikan ja koko tieteen aloilla. Perusmääritelmän mukaisesti -normi määritellään seuraavasti:
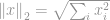
-normi tunnetaan hyvin euklidisena normina, jota käytetään vakiosuureena vektorieron mittaamisessa. Kuten -normi, jos Euklidinen normi lasketaan vektorierolle, se tunnetaan Euklidisena etäisyytenä:
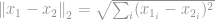
tai neliömuodossaan, joka tunnetaan tietokonenäön tutkijoiden keskuudessa nimellä Sum of Squared Difference (SSD):

Sen tunnetuin sovellus signaalinkäsittelyn alalla on keskineliövirheen (Mean-Squared Error, MSE) mittaus, jota käytetään kahden signaalin välisen samankaltaisuuden, laadun tai korrelaation laskemiseen. MSE on
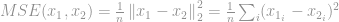
Kuten aiemmin -optimointi-osiossa käsiteltiin, monien sekä laskennallisesta että matemaattisesta näkökulmasta ilmenevien ongelmien vuoksi monet -optimointiongelmat rentoutuvat sen sijaan – ja -optimointiin. Tämän vuoksi keskustelemme nyt -optimoinnista.
l2-optimointi
Kuten -optimointitapauksessa -normin minimointiongelma muotoillaan
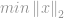 , jolle pätee
, jolle pätee
Asetetaan, että rajoitusmatriisilla 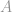 on täysi arvojärjestys (full rank), niin tämä ongelma on nyt aliterminoidun systeemin alainen systeemi, jolla on ääretön määrä ratkaisuja. Tavoitteena on tässä tapauksessa poimia näistä äärettömän monista ratkaisuista paras ratkaisu, eli jolla on pienin -normi. Tämä voisi olla hyvin työlästä, jos se laskettaisiin suoraan. Onneksi on olemassa matemaattinen kikka, joka voi auttaa meitä paljon tässä työssä.
on täysi arvojärjestys (full rank), niin tämä ongelma on nyt aliterminoidun systeemin alainen systeemi, jolla on ääretön määrä ratkaisuja. Tavoitteena on tässä tapauksessa poimia näistä äärettömän monista ratkaisuista paras ratkaisu, eli jolla on pienin -normi. Tämä voisi olla hyvin työlästä, jos se laskettaisiin suoraan. Onneksi on olemassa matemaattinen kikka, joka voi auttaa meitä paljon tässä työssä.
Käyttämällä Lagrangen kertoimien temppua voimme sitten määritellä Lagrangen

jossa  on esitelty Lagrangen kertoimet. Otetaan tämän yhtälön derivaatta nollaksi optimaalisen ratkaisun löytämiseksi ja saadaan
on esitelty Lagrangen kertoimet. Otetaan tämän yhtälön derivaatta nollaksi optimaalisen ratkaisun löytämiseksi ja saadaan
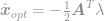
sovitetaan tämä ratkaisu rajoitukseen, jolloin saadaan
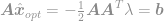
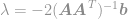
ja lopuksi
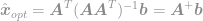
Käyttämällä tätä yhtälöä pystymme nyt välittömästi laskemaan optimaalisen ratkaisun -optimointiongelmaan. Tämä yhtälö tunnetaan hyvin nimellä Moore-Penrosen pseudoinversio ja itse ongelma tunnetaan yleensä nimellä pienimmän neliösumman ongelma, pienimmän neliösumman regressio tai pienimmän neliösumman optimointi.
Mutta vaikka pienimmän neliösumman menetelmän ratkaisu on helppo laskea, se ei välttämättä ole paras ratkaisu. Koska -normi itsessään on tasainen, on vaikea löytää yhtä ainoaa, parasta ratkaisua ongelmaan.

Vaikka päinvastoin, -optimointi voi antaa paljon paremman tuloksen kuin tämä ratkaisu.
l1-optimointi
Tavanomaiseen tapaan -minimointiongelma muotoillaan seuraavasti:
 jolle pätee
jolle pätee
Koska -normin luonne ei ole tasainen kuten -normin tapauksessa, tämän ongelman ratkaisu on paljon parempi ja yksikäsitteisempi kuin -optimoinnin.

Vaikka -minimoinnin ongelma on lähes samanmuotoinen kuin -minimoinnin ongelma, se on kuitenkin paljon vaikeampi ratkaista. Koska tässä ongelmassa ei ole sileää funktiota, temppu, jota käytimme -ongelman ratkaisemiseen, ei enää päde. Ainoa jäljellä oleva tapa löytää sen ratkaisu on etsiä sitä suoraan. Ratkaisun etsiminen tarkoittaa sitä, että meidän on laskettava jokainen yksittäinen mahdollinen ratkaisu löytääksemme parhaan ”äärettömän monen” mahdollisen ratkaisun joukosta.
Koska ei ole helppoa tapaa löytää ratkaisua tälle ongelmalle matemaattisesti, -optimoinnin käyttökelpoisuus on hyvin rajallinen vuosikymmeniä. Viime aikoihin asti suuren laskentatehon omaavien tietokoneiden kehittyminen on mahdollistanut sen, että voimme ”pyyhkäistä” läpi kaikki ratkaisut. Käyttämällä monia hyödyllisiä algoritmeja, nimittäin Convex Optimisation -algoritmia, kuten lineaarista ohjelmointia tai epälineaarista ohjelmointia jne. on nyt mahdollista löytää paras ratkaisu tähän kysymykseen. Monet -optimointiin perustuvat sovellukset, kuten kompressiivinen anturointi, ovat nyt mahdollisia.
Nykyään on saatavilla monia -optimointiin tarkoitettuja työkalupakkeja. Nämä työkalupakit käyttävät yleensä erilaisia lähestymistapoja ja/tai algoritmeja saman kysymyksen ratkaisemiseen. Esimerkkinä näistä työkalupaketeista ovat l1-magic, SparseLab, ISAL1,
Nyt olemme käsitelleet monia normiperheen jäseniä alkaen -normista, -normista ja -normista. On aika siirtyä seuraavaan. Koska keskustelimme heti alussa siitä, että voi olla mitä tahansa l-minkä tahansa normia, joka noudattaa samaa normin perusmääritelmää, vie paljon aikaa puhua kaikista niistä. Onneksi -, – ja -normia lukuun ottamatta loput niistä ovat yleensä harvinaisia, joten niissä ei ole niin paljon mielenkiintoista tarkasteltavaa. Tarkastelemme siis normin ääritapausta, joka on 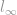 -normi (l-infiniteettinormi).
-normi (l-infiniteettinormi).
l-infiniteettinormi
Kuten aina, -normin määritelmä on
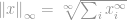
Nyt tämä määritelmä näyttää taas hankalalta, mutta itse asiassa se on aika suoraviivainen. Tarkastellaan vektoria  , sanotaan jos
, sanotaan jos 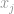 on vektorin korkein merkintä, itse äärettömyyden ominaisuuden mukaan, voimme sanoa, että
on vektorin korkein merkintä, itse äärettömyyden ominaisuuden mukaan, voimme sanoa, että
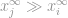

silloin
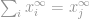
ton
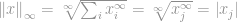
Nyt voimme yksinkertaisesti sanoa, että -normi on

eli tuon vektorin maksimimerkintöjen suuruus. Tämä varmasti demystifioi -normin
merkityksen Nyt olemme keskustelleet koko normiperheestä :sta :een, toivon, että tämä keskustelu auttaisi ymmärtämään normin merkityksen, sen matemaattiset ominaisuudet ja sen reaalimaailman seuraukset.
Viitteet ja jatkolukemista:
Matemaattinen normi – wikipedia
Matemaattinen normi – MathWorld
Michael Elad – ”Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing” , Springer, 2010.
Linear Programming – MathWorld
Compressive Sensing – Rice University
Muokattu (15/02/15) : Korjattu sisällön epätarkkuuksia.