Introducción
Con la creciente demanda de infraestructuras fiables y de alto rendimiento diseñadas para servir a sistemas críticos, los términos escalabilidad y alta disponibilidad no podrían ser más populares. Si bien el manejo de una mayor carga del sistema es una preocupación común, la disminución del tiempo de inactividad y la eliminación de puntos únicos de fallo son igual de importantes. La alta disponibilidad es una cualidad del diseño de la infraestructura a escala que aborda estas últimas consideraciones.
En esta guía, hablaremos de lo que significa exactamente alta disponibilidad y de cómo puede mejorar la fiabilidad de su infraestructura.
¿Qué es la alta disponibilidad?
En informática, el término disponibilidad se utiliza para describir el periodo de tiempo en el que un servicio está disponible, así como el tiempo que necesita un sistema para responder a una solicitud realizada por un usuario. La alta disponibilidad es una cualidad de un sistema o componente que asegura un alto nivel de rendimiento operativo durante un periodo de tiempo determinado.
Medir la disponibilidad
La disponibilidad se expresa a menudo como un porcentaje que indica el tiempo de actividad que se espera de un sistema o componente concreto en un periodo de tiempo determinado, donde un valor del 100% indicaría que el sistema nunca falla. Por ejemplo, un sistema que garantiza un 99% de disponibilidad en un periodo de un año puede tener hasta 3,65 días de inactividad (1%).
Estos valores se calculan en base a varios factores, incluyendo los periodos de mantenimiento programados y no programados, así como el tiempo de recuperación de un posible fallo del sistema.
¿Cómo funciona la alta disponibilidad?
La alta disponibilidad funciona como un mecanismo de respuesta a fallos para la infraestructura. Su funcionamiento es bastante sencillo desde el punto de vista conceptual, pero suele requerir un software y una configuración especializados.
¿Cuándo es importante la alta disponibilidad?
Cuando se configuran sistemas de producción robustos, minimizar el tiempo de inactividad y las interrupciones del servicio suele ser una gran prioridad. Independientemente de lo fiables que sean sus sistemas y su software, pueden surgir problemas que hagan caer sus aplicaciones o sus servidores.
Implementar la alta disponibilidad para su infraestructura es una estrategia útil para reducir el impacto de este tipo de eventos. Los sistemas de alta disponibilidad pueden recuperarse de un fallo del servidor o de un componente de forma automática.
¿Qué hace que un sistema sea de alta disponibilidad?
Uno de los objetivos de la alta disponibilidad es eliminar los puntos únicos de fallo en su infraestructura. Un punto único de fallo es un componente de su pila tecnológica que causaría una interrupción del servicio si no estuviera disponible. Como tal, cualquier componente que sea un requisito para la correcta funcionalidad de su aplicación que no tenga redundancia se considera un punto único de fallo.
Para eliminar los puntos únicos de fallo, cada capa de su pila debe estar preparada para la redundancia. Por ejemplo, imagine que tiene una infraestructura que consiste en dos servidores web idénticos y redundantes detrás de un equilibrador de carga. El tráfico procedente de los clientes se distribuirá por igual entre los servidores web, pero si uno de los servidores se cae, el equilibrador de carga redirigirá todo el tráfico al servidor restante en línea.
La capa del servidor web en este escenario no es un punto único de fallo porque:
- existen componentes redundantes para la misma tarea
- el mecanismo que se encuentra encima de esta capa (el equilibrador de carga) es capaz de detectar fallos en los componentes y adaptar su comportamiento para una recuperación oportuna
¿Pero qué ocurre si el equilibrador de carga se queda sin conexión?
Con el escenario descrito, que no es infrecuente en la vida real, la propia capa de equilibrio de carga sigue siendo un único punto de fallo. Eliminar este punto único de fallo restante, sin embargo, puede ser un reto; aunque se puede configurar fácilmente un equilibrador de carga adicional para lograr la redundancia, no hay un punto obvio por encima de los equilibradores de carga para implementar la detección de fallos y la recuperación.
La redundancia por sí sola no puede garantizar la alta disponibilidad. Debe existir un mecanismo para detectar fallos y tomar medidas cuando uno de los componentes de su pila deja de estar disponible.
La detección y recuperación de fallos para los sistemas redundantes puede implementarse utilizando un enfoque de arriba a abajo: la capa superior se hace responsable de supervisar la capa inmediatamente inferior en busca de fallos. En nuestro ejemplo anterior, el equilibrador de carga es la capa superior. Si uno de los servidores web (capa inferior) deja de estar disponible, el equilibrador de carga dejará de redirigir las peticiones para ese servidor específico.
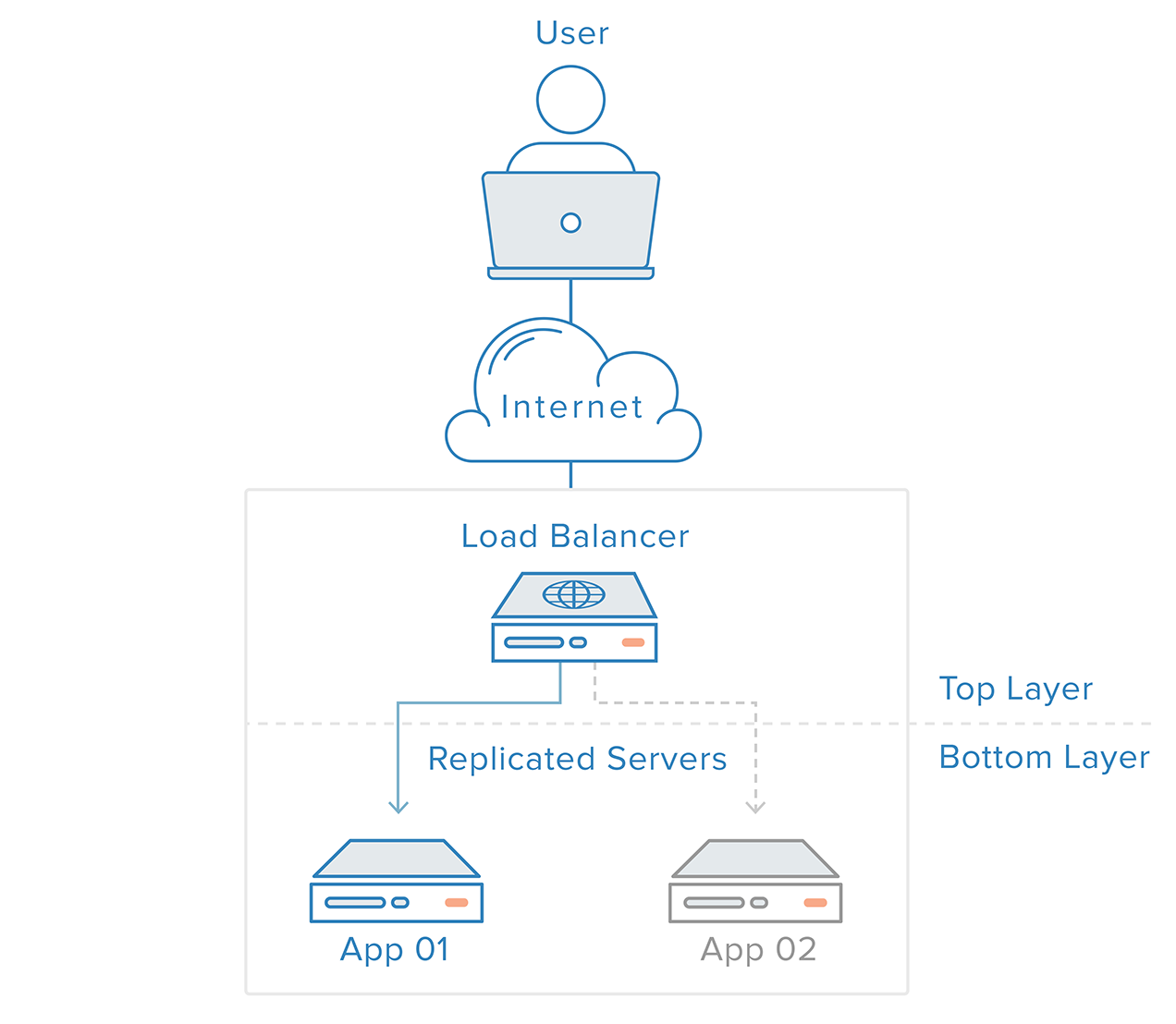
Este enfoque tiende a ser más simple, pero tiene limitaciones: habrá un punto en su infraestructura donde una capa superior es inexistente o está fuera de alcance, que es el caso de la capa del equilibrador de carga. Crear un servicio de detección de fallos para el balanceador de carga en un servidor externo simplemente crearía un nuevo punto único de fallo.
Con este escenario, es necesario un enfoque distribuido. Múltiples nodos redundantes deben conectarse juntos como un clúster en el que cada nodo debe ser igualmente capaz de detectar y recuperar los fallos.
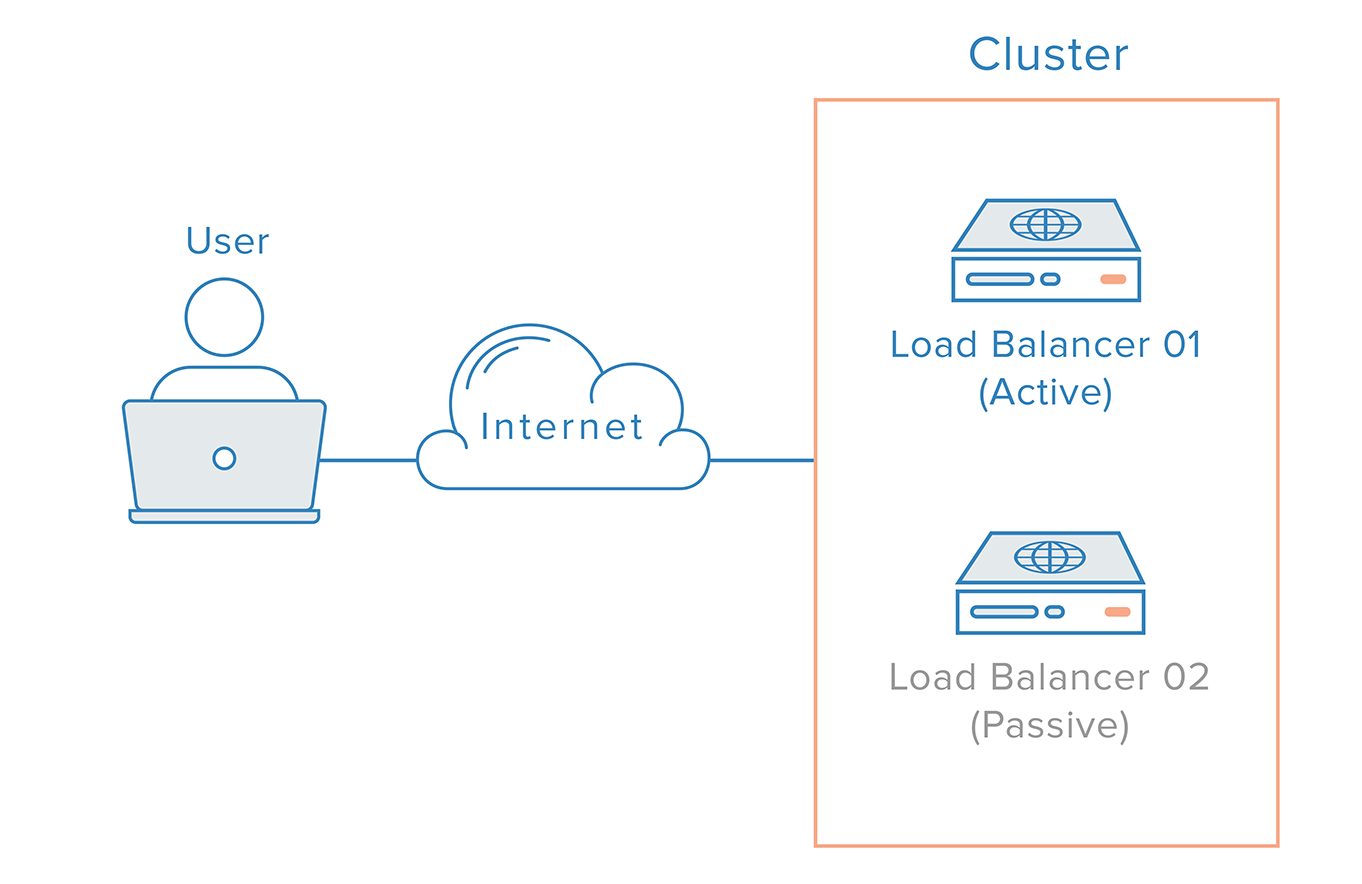
Para el caso del equilibrador de carga, sin embargo, hay una complicación adicional, debido a la forma en que funcionan los servidores de nombres. La recuperación de un fallo del equilibrador de carga suele significar una conmutación por error a un equilibrador de carga redundante, lo que implica que se debe realizar un cambio de DNS para apuntar un nombre de dominio a la dirección IP del equilibrador de carga redundante. Un cambio de este tipo puede tardar un tiempo considerable en propagarse por Internet, lo que provocaría un grave tiempo de inactividad en este sistema.
Una posible solución es utilizar el equilibrio de carga DNS round-robin. Sin embargo, este enfoque no es fiable, ya que deja la conmutación por error a la aplicación del lado del cliente.
Una solución más robusta y fiable es utilizar sistemas que permitan la reasignación flexible de direcciones IP, como las IPs flotantes. La reasignación de direcciones IP bajo demanda elimina los problemas de propagación y almacenamiento en caché inherentes a los cambios de DNS, proporcionando una dirección IP estática que puede ser fácilmente reasignada cuando sea necesario. El nombre de dominio puede seguir asociado a la misma dirección IP, mientras que la propia dirección IP se mueve entre servidores.
Así es como se ve una infraestructura de alta disponibilidad que utiliza IPs flotantes:

¿Qué componentes del sistema son necesarios para la alta disponibilidad?
Hay varios componentes que se deben tener en cuenta cuidadosamente para implementar la alta disponibilidad en la práctica. Mucho más que una implementación de software, la alta disponibilidad depende de factores como:
- Entorno: si todos sus servidores están ubicados en la misma zona geográfica, una condición ambiental como un terremoto o una inundación podría hacer caer todo su sistema. Tener servidores redundantes en diferentes centros de datos y zonas geográficas aumentará la fiabilidad.
- Hardware: los servidores de alta disponibilidad deben ser resistentes a los cortes de energía y a los fallos de hardware, incluidos los discos duros y las interfaces de red.
- Software: toda la pila de software, incluyendo el sistema operativo y la propia aplicación, debe estar preparada para manejar fallos inesperados que podrían requerir un reinicio del sistema, por ejemplo.
- Datos: la pérdida de datos y la inconsistencia pueden ser causadas por varios factores, y no se limita a los fallos del disco duro. Los sistemas de alta disponibilidad deben tener en cuenta la seguridad de los datos en caso de fallo.
- Red: las interrupciones imprevistas de la red representan otro posible punto de fallo para los sistemas de alta disponibilidad. Es importante que exista una estrategia de red redundante para posibles fallos.
¿Qué software se puede utilizar para configurar la alta disponibilidad?
Cada capa de un sistema de alta disponibilidad tendrá diferentes necesidades en términos de software y configuración. Sin embargo, a nivel de aplicación, los balanceadores de carga representan una pieza de software esencial para crear cualquier configuración de alta disponibilidad.
HAProxy (Proxy de alta disponibilidad) es una opción común para el equilibrio de carga, ya que puede manejar el equilibrio de carga en múltiples capas, y para diferentes tipos de servidores, incluyendo los servidores de bases de datos.
Subiendo en la pila del sistema, es importante implementar una solución redundante fiable para su punto de entrada de la aplicación, normalmente el equilibrador de carga. Para eliminar este punto único de fallo, como se ha mencionado anteriormente, necesitamos implementar un cluster de balanceadores de carga detrás de una IP flotante. Corosync y Pacemaker son opciones populares para crear una configuración de este tipo, tanto en servidores Ubuntu como CentOS.
Conclusión
La alta disponibilidad es un subconjunto importante de la ingeniería de fiabilidad, enfocado a asegurar que un sistema o componente tenga un alto nivel de rendimiento operativo en un periodo de tiempo determinado. A primera vista, su aplicación puede parecer bastante compleja; sin embargo, puede aportar enormes beneficios a los sistemas que requieren una mayor fiabilidad.