はじめに
重要なシステムに対応するために設計された信頼性とパフォーマンスの高いインフラストラクチャへの要求が高まる中、スケーラビリティと高可用性という言葉がこれ以上ないほど一般的になってきました。 増加するシステム負荷に対処することは一般的な懸念事項ですが、ダウンタイムを減らし、単一障害点を排除することも同様に重要です。 高可用性とは、これらの後者の考慮事項に対処する、規模に応じたインフラストラクチャ設計の品質です。
このガイドでは、高可用性とは厳密に何を意味するのか、そして、インフラの信頼性をどのように向上させることができるのかについて説明します。
Measuring Availability
可用性は、特定のシステムまたはコンポーネントから、ある期間にどれだけの稼働時間が期待できるかを示すパーセントで表されることが多く、値が 100% の場合は、システムが決して故障しないことを意味します。 たとえば、1 年間で 99% の可用性を保証するシステムの場合、ダウンタイムは最大 3.65 日 (1%) です。
これらの値は、予定されているメンテナンス期間と予定外のメンテナンス期間、および考えられるシステム障害からの回復時間などのいくつかの要因に基づいて計算されます。
High Availability はいつ重要か。
堅牢な生産システムを構築する場合、ダウンタイムやサービスの中断を最小限に抑えることが優先されることがよくあります。 システムやソフトウェアの信頼性にかかわらず、アプリケーションやサーバーを停止させるような問題が発生することがあります。
インフラストラクチャに高可用性を実装することは、この種のイベントの影響を軽減する有用な戦略です。 高可用性のシステムは、サーバーまたはコンポーネントの障害から自動的に回復できます。
高可用性のシステムを構成するもの
高可用性の目標の 1 つは、インフラストラクチャにおける単一障害点を排除することです。 単一障害点とは、利用できなくなった場合にサービス中断の原因となる、テクノロジー スタックのコンポーネントのことです。 そのため、アプリケーションの適切な機能のために必要な、冗長性のないコンポーネントは、単一障害点とみなされます。
単一障害点を排除するには、スタックの各層が冗長性のために準備されている必要があります。 たとえば、ロードバランサーの背後にある 2 つの同一で冗長な Web サーバーからなるインフラストラクチャがあるとします。 クライアントから来るトラフィックは、ウェブサーバー間で均等に分散されますが、サーバーの1つがダウンした場合、ロードバランサーはすべてのトラフィックを残りのオンラインサーバーにリダイレクトします。
- 同じタスクの冗長コンポーネントが配置されている。
- この層の上のメカニズム(ロード バランサー)は、コンポーネントでの障害を検出でき、タイムリーに回復するために動作を適応させることが可能である。
現実には珍しくない前述のシナリオでは、ロード バランシング レイヤー自体が単一障害点であることに変わりはありません。 冗長性を実現するために追加のロードバランサーを簡単に構成できるにもかかわらず、ロードバランサーの上に障害検出と回復を実装する明白なポイントがないのです。
冗長システムの障害検出および回復は、上から下へのアプローチを使用して実装できます。 先ほどの例のシナリオでは、ロードバランサーが最上位レイヤーです。 もし、ウェブサーバー(下のレイヤー)の一つが利用できなくなると、ロードバランサーはその特定のサーバーへのリクエストのリダイレクトを停止します。
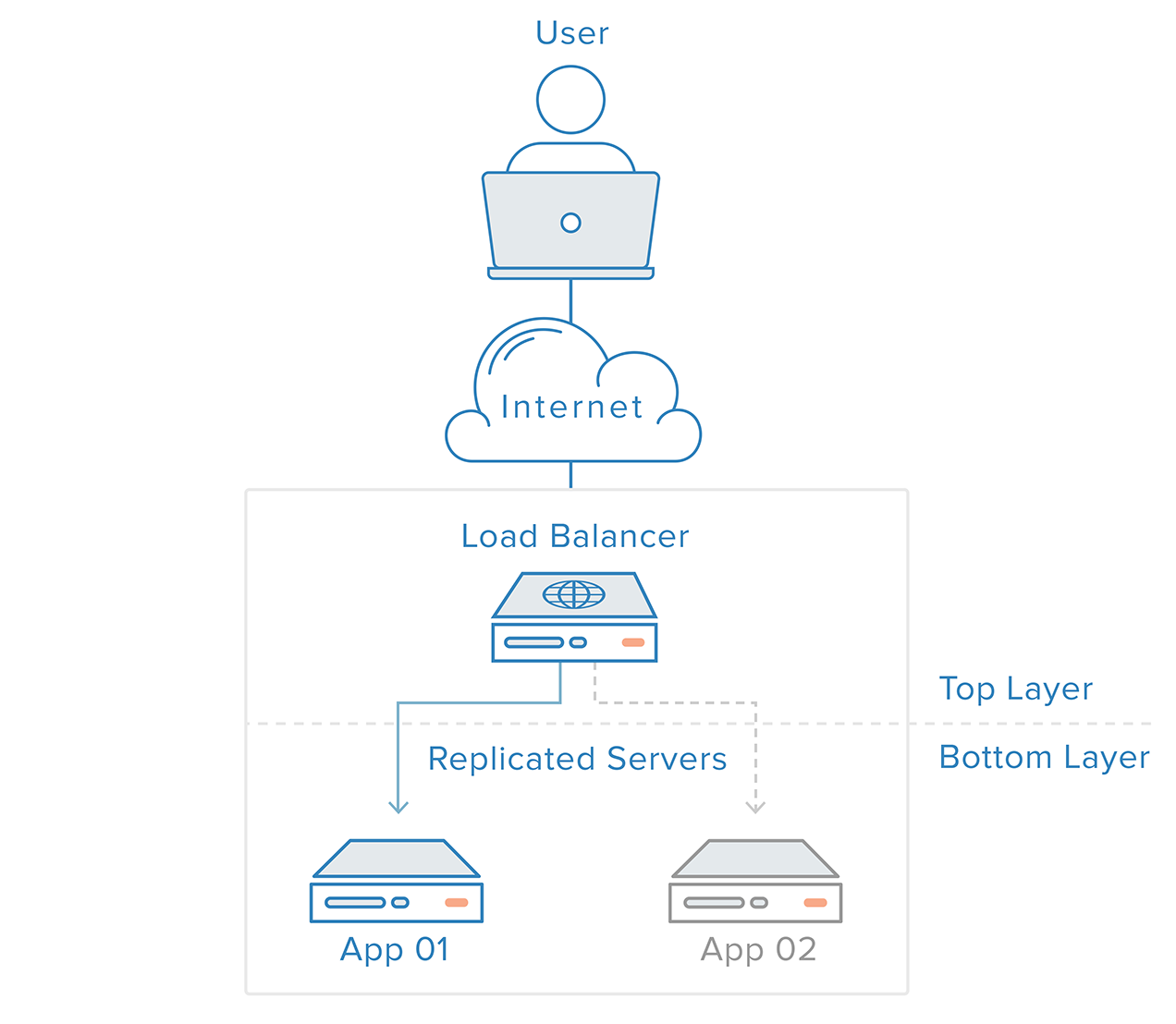
このアプローチはより単純になる傾向がありますが、限界があります。トップ レイヤーが存在しないか、ロード バランサー レイヤーのような手の届かないところにある点が、インフラの中に存在することでしょう。 ロードバランサーの障害検知サービスを外部サーバーに作ると、単に新しい単一障害点を作ってしまうことになります。
このようなシナリオでは、分散型アプローチが必要です。 複数の冗長ノードをクラスタとして接続し、各ノードが等しく障害検出と回復ができるようにする必要があります。
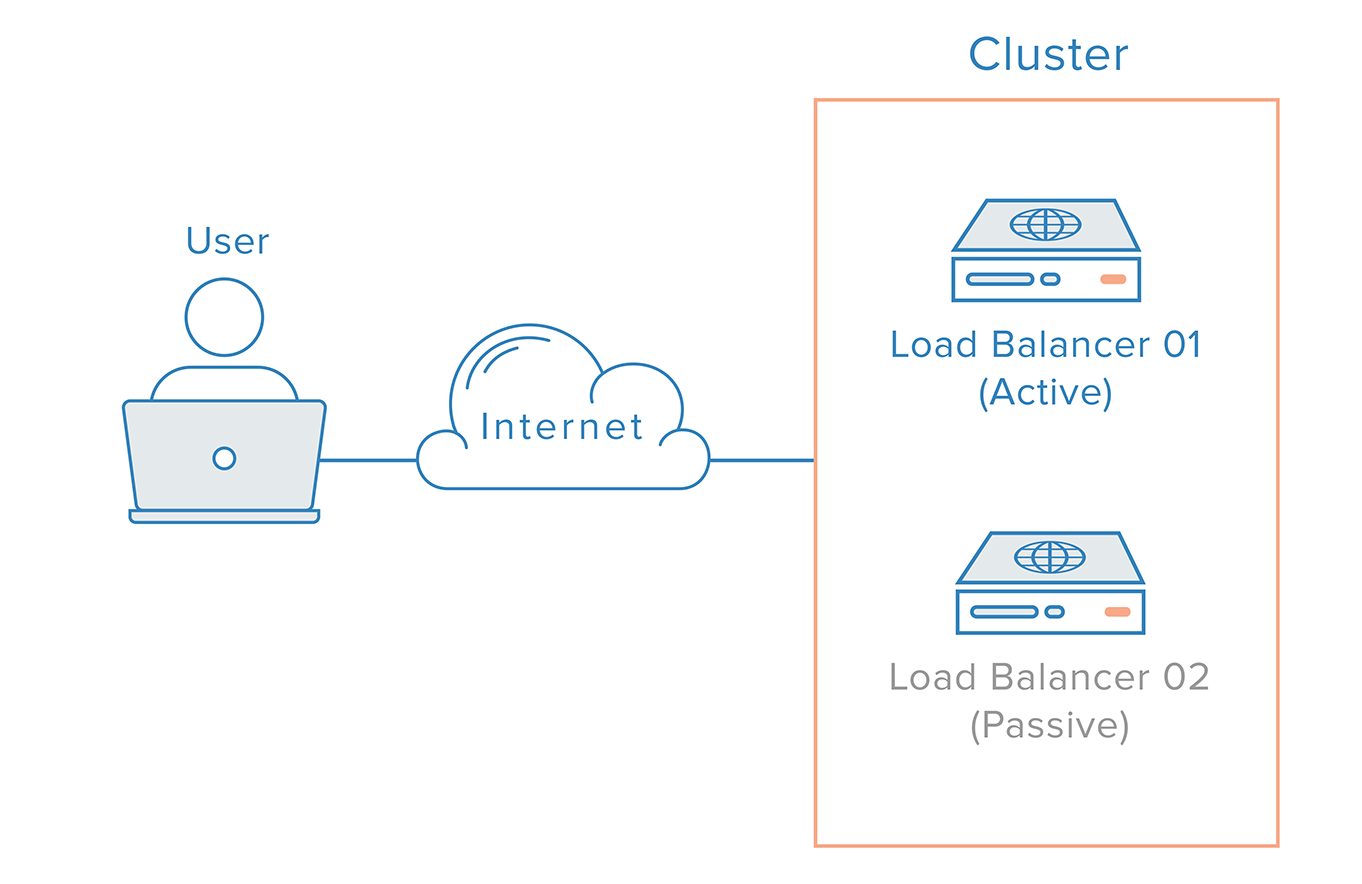
ロード バランサーの場合、ネーム サーバーの動作方法によって、さらに複雑な問題が発生します。 ロード バランサー障害からの回復は、通常、冗長ロード バランサーへのフェイルオーバーを意味し、これは、ドメイン名を冗長ロード バランサーの IP アドレスに向けるために DNS を変更する必要があることを意味します。 このような変更は、インターネット上で伝搬されるまでにかなりの時間がかかるため、このシステムに深刻なダウンタイムをもたらすことになります。
可能な解決策は、DNSラウンドロビン負荷分散を使用することです。
より堅牢で信頼性の高いソリューションは、フローティング IP などの柔軟な IP アドレスの再マッピングを可能にするシステムを使用することです。 オンデマンド IP アドレス再マッピングは、必要なときに簡単に再マッピングできる静的 IP アドレスを提供することにより、DNS の変更に固有の伝播とキャッシュの問題を排除します。 フローティング IP を使用した高可用性インフラストラクチャは次のようになります。

高可用性に必要なシステム コンポーネントとは
高可用性を実際に実装するには、慎重に考慮しなければならないコンポーネントがいくつかあります。 ソフトウェアの実装以上に、高可用性は次のような要因に依存します。
- 環境:すべてのサーバーが同じ地域に配置されている場合、地震や洪水などの環境条件によってシステム全体がダウンする可能性があります。 異なるデータセンターや地域に冗長化されたサーバーを設置することで、信頼性を高めることができます。
- ハードウェア:可用性の高いサーバーは、停電やハードディスク、ネットワーク・インターフェイスなどのハードウェア障害に強いことが必要です。
- ソフトウェア: オペレーティング システムとアプリケーション自体を含むソフトウェア スタック全体は、たとえばシステムの再起動を必要とする可能性のある予期せぬ障害に対応できるように準備されている必要があります。
- データ: データの損失や不整合はいくつかの要因によって引き起こされる可能性があり、それはハードディスク障害に限定されるものではありません。 高可用性システムは、障害発生時のデータの安全性を考慮しなければなりません。
- ネットワーク:計画外のネットワーク停止は、高可用性システムの障害の可能性がある別のポイントに相当します。 起こりうる障害に備え、冗長ネットワーク戦略を導入することが重要です。
高可用性を構成するために使用できるソフトウェアとは
高可用性システムの各層には、ソフトウェアと構成の面で異なるニーズがあります。 しかし、アプリケーション レベルでは、ロード バランサーは、あらゆる高可用性設定を作成するために不可欠なソフトウェアの一部です。
HAProxy (High Availability Proxy) は、複数のレイヤーで、またデータベース サーバーを含むさまざまな種類のサーバーの負荷分散を処理できるため、負荷分散の一般的な選択肢です。
システム スタックを上に移動すると、通常はロード バランサーであるアプリケーション入口に対して信頼できる冗長ソリューションを実装することが重要です。 この単一障害点を取り除くには、前述のように、フローティング IP の背後にロード バランサーのクラスターを実装する必要があります。 Corosync と Pacemaker は、Ubuntu と CentOS サーバーの両方で、このようなセットアップを作成するための一般的な選択肢です。
結論
高稼働率は信頼性エンジニアリングの重要なサブセットで、システムまたはコンポーネントが一定期間内に高いレベルの運用性能を持つことを保証することに焦点を合わせています。 一見すると、その実装は非常に複雑に見えるかもしれないが、信頼性の向上が必要なシステムには多大な利益をもたらすことができる
。