Bevezetés
A kritikus rendszerek kiszolgálására tervezett, megbízható és teljesítőképes infrastruktúrák iránti megnövekedett igény miatt a skálázhatóság és a magas rendelkezésre állás fogalma nem is lehetne népszerűbb. Míg a megnövekedett rendszerterhelés kezelése általános aggodalomra ad okot, az állásidő csökkentése és az egyetlen hibapontok kiküszöbölése ugyanilyen fontos. A magas rendelkezésre állás az infrastruktúra méretarányos tervezésének olyan minősége, amely ez utóbbi szempontokat kezeli.
Ezzel az útmutatóval azt fogjuk megvitatni, hogy pontosan mit jelent a magas rendelkezésre állás, és hogyan javíthatja infrastruktúrája megbízhatóságát.
Mi a magas rendelkezésre állás?
A számítástechnikában a rendelkezésre állás kifejezés azt az időtartamot jelöli, amikor egy szolgáltatás elérhető, valamint azt az időt, amely alatt egy rendszer válaszol egy felhasználó által benyújtott kérésre. A magas rendelkezésre állás egy rendszer vagy komponens olyan tulajdonsága, amely egy adott időtartamra magas szintű működési teljesítményt biztosít.
A rendelkezésre állás mérése
A rendelkezésre állást gyakran százalékban fejezik ki, ami azt jelzi, hogy egy adott rendszertől vagy komponenstől mennyi üzemidő várható egy adott időtartam alatt, ahol a 100%-os érték azt jelentené, hogy a rendszer soha nem hibásodik meg. Például egy olyan rendszer, amely egy év alatt 99%-os rendelkezésre állást garantál, legfeljebb 3,65 napos (1%-os) kieséssel számolhat.
Az értékek kiszámítása több tényező alapján történik, beleértve a tervezett és a nem tervezett karbantartási időszakokat, valamint az esetleges rendszerhiba utáni helyreállítási időt.
Hogyan működik a magas rendelkezésre állás?
A magas rendelkezésre állás az infrastruktúra hibára reagáló mechanizmusaként működik. Működésének módja koncepcionálisan meglehetősen egyszerű, de jellemzően speciális szoftvert és konfigurációt igényel.
Mikor fontos a magas rendelkezésre állás?
A robusztus termelési rendszerek létrehozásakor gyakran kiemelt fontosságú az állásidő és a szolgáltatás megszakadásának minimalizálása. Függetlenül attól, hogy mennyire megbízhatóak a rendszerek és a szoftverek, előfordulhatnak olyan problémák, amelyek miatt leállhatnak az alkalmazások vagy a szerverek.
A magas rendelkezésre állás megvalósítása az infrastruktúrában hasznos stratégia az ilyen típusú események hatásának csökkentésére. A magas rendelkezésre állású rendszerek automatikusan helyreállnak a kiszolgáló vagy komponensek meghibásodásából.
Mitől lesz egy rendszer magas rendelkezésre állású?
A magas rendelkezésre állás egyik célja, hogy kiküszöbölje az egyetlen hibapontokat az infrastruktúrában. Az egyetlen hibapont a technológiai stack olyan összetevője, amely a szolgáltatás megszakadását okozná, ha elérhetetlenné válna. Így az alkalmazás megfelelő működéséhez szükséges minden olyan komponens, amely nem rendelkezik redundanciával, egyetlen hibapontnak minősül.
Az egyetlen hibapontok kiküszöbölése érdekében a stack minden rétegét fel kell készíteni a redundanciára. Képzelje el például, hogy van egy infrastruktúrája, amely két azonos, redundáns webkiszolgálóból áll egy terheléselosztó mögött. Az ügyfelektől érkező forgalom egyenlően oszlik meg a webkiszolgálók között, de ha az egyik szerver leáll, a terheléselosztó az összes forgalmat átirányítja a megmaradt online szerverre.
A webkiszolgáló réteg ebben a forgatókönyvben nem egyetlen hibapont, mert:
- redundáns komponensek vannak ugyanarra a feladatra
- a réteg tetején lévő mechanizmus (a terheléselosztó) képes észlelni a komponensek hibáit, és a viselkedését az időben történő helyreállításhoz igazítani
De mi történik, ha a terheléselosztó leáll?
A leírt forgatókönyv szerint, ami a való életben nem ritka, maga a terheléselosztó réteg marad az egyetlen hibapont. Ennek a fennmaradó egyetlen hibapontnak a kiküszöbölése azonban kihívást jelenthet; bár a redundancia elérése érdekében könnyen konfigurálhatunk egy további terheléselosztót, a terheléselosztók felett nincs egyértelmű pont a hibaérzékelés és helyreállítás megvalósítására.
A redundancia önmagában nem garantálja a magas rendelkezésre állást. Valamilyen mechanizmusra van szükség a hibák észlelésére és a cselekvésre, ha a verem egyik összetevője elérhetetlenné válik.
A redundáns rendszerek hibaérzékelése és helyreállítása felülről lefelé irányuló megközelítéssel valósítható meg: a legfelső réteg lesz felelős a közvetlenül alatta lévő réteg hibaellenőrzéséért. Az előző példaforgatókönyvünkben a terheléselosztó a legfelső réteg. Ha az egyik webkiszolgáló (alsó réteg) elérhetetlenné válik, a terheléselosztó leállítja a kérések átirányítását az adott kiszolgálóhoz.
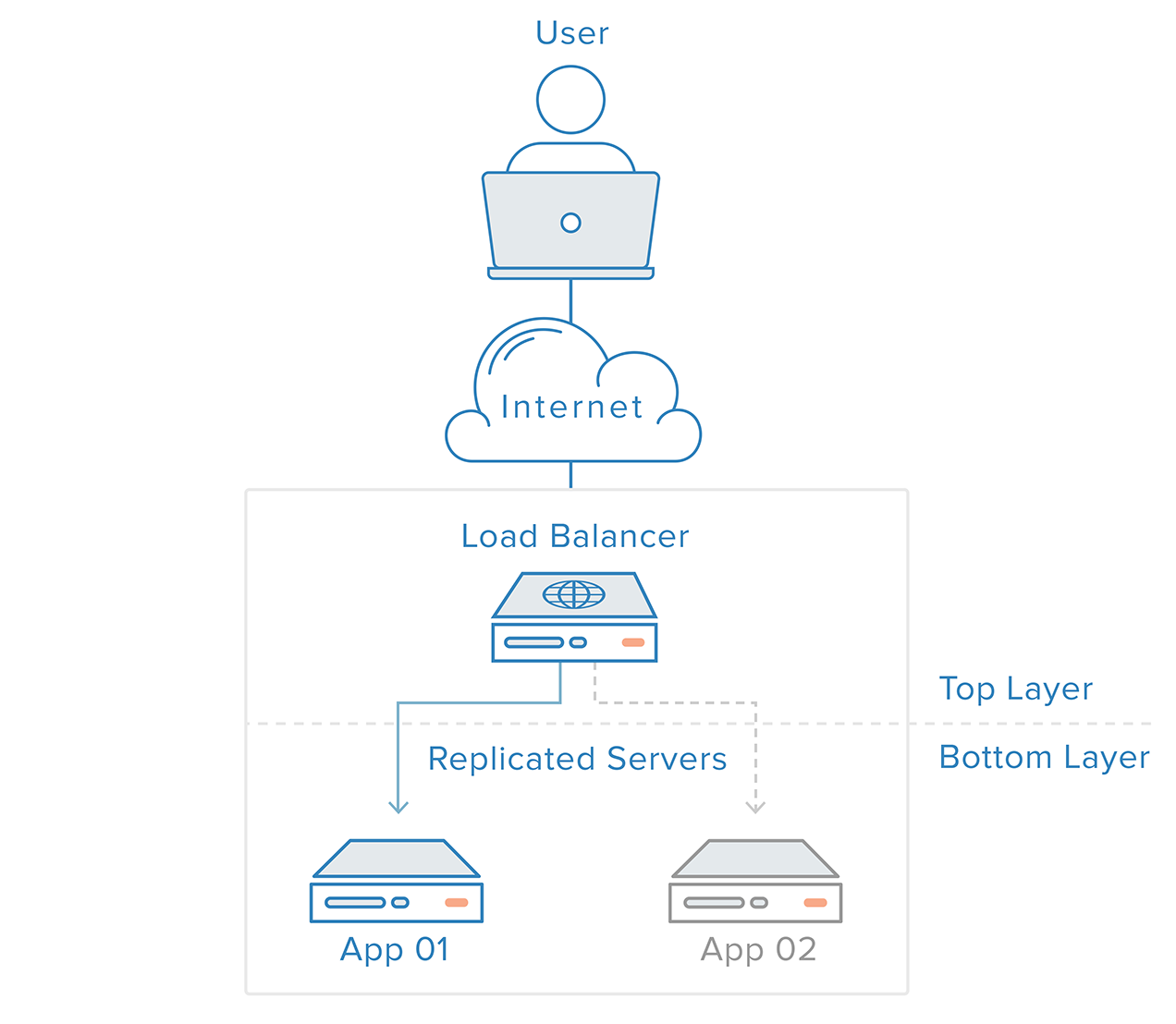
Ez a megközelítés általában egyszerűbb, de vannak korlátai: lesz egy pont az infrastruktúrában, ahol a legfelső réteg vagy nem létezik, vagy nem elérhető, ami a terheléselosztó réteg esetében fennáll. A terheléselosztó hibaérzékelő szolgáltatásának létrehozása egy külső kiszolgálóban egyszerűen egy új egyetlen hibapontot hozna létre.
Egy ilyen forgatókönyv esetén elosztott megközelítésre van szükség. Több redundáns csomópontot kell fürtként összekapcsolni, ahol minden csomópontnak egyformán képesnek kell lennie a hiba észlelésére és helyreállítására.
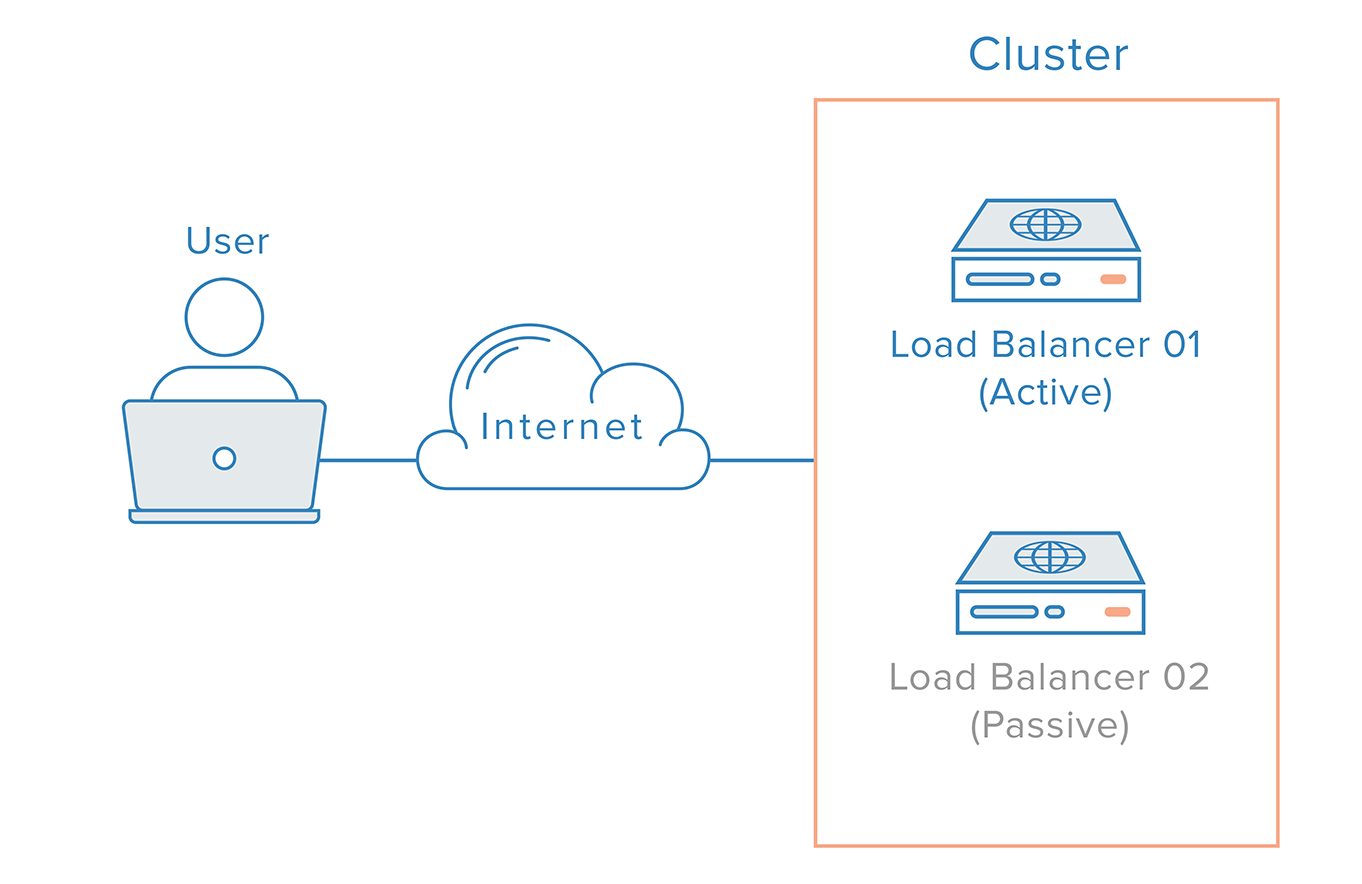
A terheléselosztó esetében azonban a névszerverek működése miatt további bonyodalom lép fel. A terheléselosztó meghibásodásából való helyreállítás általában egy redundáns terheléselosztóra való átállást jelent, ami azt jelenti, hogy DNS-módosítást kell végrehajtani annak érdekében, hogy egy tartománynevet a redundáns terheléselosztó IP-címére irányítsunk. Egy ilyen változtatás terjedése az interneten jelentős időt vehet igénybe, ami komoly leállást okozna a rendszernek.
Egy lehetséges megoldás a DNS körkörös terheléselosztás alkalmazása. Ez a megközelítés azonban nem megbízható, mivel a hibaelhárítást az ügyféloldali alkalmazásra bízza.
Szilárdabb és megbízhatóbb megoldás a rugalmas IP-cím-áthelyezést lehetővé tevő rendszerek, például a lebegő IP-k használata. Az igény szerinti IP-cím újratelepítés kiküszöböli a DNS-változásokban rejlő terjedési és gyorsítótárazási problémákat, mivel statikus IP-címet biztosít, amely szükség esetén könnyen újratelepíthető. A tartománynév továbbra is ugyanahhoz az IP-címhez társítható, miközben maga az IP-cím átkerül a szerverek között.
Így néz ki egy lebegő IP-ket használó, nagy rendelkezésre állású infrastruktúra:

Milyen rendszerelemek szükségesek a nagy rendelkezésre álláshoz?
A nagy rendelkezésre állás gyakorlati megvalósításához több olyan elemet is gondosan figyelembe kell venni. A magas rendelkezésre állás sokkal inkább, mint egy szoftveres megvalósítás, olyan tényezőktől függ, mint:
- Környezet: Ha az összes szerver ugyanazon a földrajzi területen található, egy környezeti körülmény, például egy földrengés vagy árvíz az egész rendszert tönkreteheti. A különböző adatközpontokban és földrajzi területeken lévő redundáns szerverek növelik a megbízhatóságot.
- Hardver: A nagy rendelkezésre állású szervereknek ellenállónak kell lenniük az áramkimaradásokkal és hardverhibákkal szemben, beleértve a merevlemezeket és a hálózati interfészeket.
- Szoftver: a teljes szoftverhalmazt, beleértve az operációs rendszert és magát az alkalmazást is, fel kell készíteni a váratlan meghibásodások kezelésére, amelyek potenciálisan például a rendszer újraindítását tehetik szükségessé.
- Adatok: Az adatvesztést és az inkonzisztenciát számos tényező okozhatja, és ez nem korlátozódik a merevlemez meghibásodására. A nagy rendelkezésre állású rendszereknek figyelembe kell venniük az adatok biztonságát meghibásodás esetén.
- Hálózat: A nem tervezett hálózati kiesések egy másik lehetséges hibapontot jelentenek a nagy rendelkezésre állású rendszerek számára. Fontos, hogy az esetleges meghibásodások esetére redundáns hálózati stratégia álljon rendelkezésre.
Milyen szoftverrel konfigurálható a magas rendelkezésre állás?
A magas rendelkezésre állású rendszer minden rétegének más-más szükségletei vannak a szoftver és a konfiguráció tekintetében. Az alkalmazás szintjén azonban a terheléselosztók alapvető szoftvert jelentenek bármely magas rendelkezésre állású beállítás létrehozásához.
A HAProxy (High Availability Proxy) gyakori választás a terheléselosztáshoz, mivel több rétegben és különböző típusú kiszolgálók, köztük az adatbázis-kiszolgálók terheléselosztását is képes kezelni.
A rendszer stackjében felfelé haladva fontos, hogy megbízható redundáns megoldást valósítsunk meg az alkalmazás belépési pontjához, általában a terheléselosztóhoz. Ennek az egyetlen hibapontnak a megszüntetéséhez, mint már említettük, terheléselosztók fürtjét kell megvalósítanunk egy lebegő IP mögött. A Corosync és a Pacemaker népszerű választás egy ilyen beállítás létrehozásához, mind Ubuntu, mind CentOS szervereken.
Végkövetkeztetés
A magas rendelkezésre állás a megbízhatósági tervezés egy fontos részhalmaza, amely arra összpontosít, hogy biztosítsa egy rendszer vagy komponens magas szintű működési teljesítményét egy adott időszakban. Megvalósítása első pillantásra meglehetősen bonyolultnak tűnhet, azonban a fokozott megbízhatóságot igénylő rendszerek számára óriási előnyökkel járhat.