Az utóbbi időben sokat foglalkozom normával kapcsolatos dolgokkal, és itt az ideje, hogy beszéljek róla. Ebben a bejegyzésben a normák egy egész családjáról fogunk beszélni.
Mi a norma?
Matematikailag a norma egy vektortér vagy mátrix összes vektorának teljes mérete vagy hossza. Az egyszerűség kedvéért azt mondhatjuk, hogy minél nagyobb a norma, annál nagyobb a (benne lévő) mátrix vagy vektor. A normának sokféle formája és neve lehet, többek között ezek a népszerű nevek: euklideszi távolság, átlagos négyzetes hiba stb.
A legtöbbször a norma egy ilyen egyenletben jelenik meg:
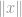 ahol
ahol  lehet egy vektor vagy egy mátrix.
lehet egy vektor vagy egy mátrix.
Euklideszi normája például egy 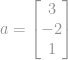 vektornak
vektornak 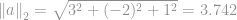 , ami a
, ami a
A fenti példa azt mutatja, hogyan lehet kiszámítani az euklideszi normát, vagy formálisan 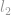 -normának nevezik. Sok más típusú norma is létezik, ami túlmutat az itteni magyarázatunkon, valójában minden egyes valós számnak van egy normája, ami megfelel neki (Figyeljük meg a hangsúlyos valós szám szót, ez azt jelenti, hogy nem csak egész számokra korlátozódik.)
-normának nevezik. Sok más típusú norma is létezik, ami túlmutat az itteni magyarázatunkon, valójában minden egyes valós számnak van egy normája, ami megfelel neki (Figyeljük meg a hangsúlyos valós szám szót, ez azt jelenti, hogy nem csak egész számokra korlátozódik.)
Formálisan a 
 -normája a következőképpen definiált:
-normája a következőképpen definiált:
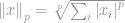 ahol
ahol 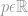
Ez az! Az összes elem p-edik hatványra történő összegzésének p-edik gyökét nevezzük normának.
Az érdekes az, hogy bár minden -norma nagyon hasonlóan néz ki egymáshoz, matematikai tulajdonságaik nagyon különbözőek, és így alkalmazásuk is drámaian különbözik. Az alábbiakban néhány ilyen normát fogunk részletesen megvizsgálni.
l0-norma
Az első norma, amelyet tárgyalni fogunk, egy 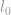 -norma. Definíció szerint a -norma
-norma. Definíció szerint a -norma
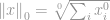
A -norma szigorúan véve valójában nem norma. Ez egy kardinalitásfüggvény, amelynek definíciója a -norma formájában van, bár sokan normának nevezik. Kicsit trükkös vele dolgozni, mert jelen van benne a nulladik hatvány és a nulladik gyök. Nyilvánvalóan bármelyik 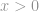 azzá válik, de a nulladik hatalom és különösen a nulladik gyökér definíciójának problémái itt összekuszálják a dolgokat. Így a valóságban a legtöbb matematikus és mérnök ehelyett a -norma definícióját használja:
azzá válik, de a nulladik hatalom és különösen a nulladik gyökér definíciójának problémái itt összekuszálják a dolgokat. Így a valóságban a legtöbb matematikus és mérnök ehelyett a -norma definícióját használja:
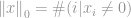
az egy vektor nem nulla elemeinek teljes száma.
Mert ez a nem nulla elemek száma, nagyon sok olyan alkalmazás van, amely a -normát használja. Az utóbbi időben még inkább a középpontban van, mert a Compressive Sensing rendszer emelkedése miatt, amely megpróbálja megtalálni az aluldeterminált lineáris rendszer legritkább megoldását. A legritkább megoldás azt a megoldást jelenti, amely a legkevesebb nem nulla bejegyzéssel rendelkezik, azaz a legalacsonyabb -normával. Ezt a problémát általában a -norma optimalizálási problémának vagy -optimalizálásnak tekintik.
l0-optimalizálás
Sok alkalmazás, köztük a tömörítő érzékelés is, megpróbálja minimalizálni egy bizonyos megkötéseknek megfelelő vektor -normáját, ezért “-minimalizálásnak” nevezik. Egy szabványos minimalizálási probléma a következőképpen fogalmazódik meg:
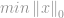 a
a 
feltételnek
Ez azonban nem könnyű feladat. Mivel a -norma matematikai reprezentációjának hiánya miatt a -minimalizálást az informatikusok NP-nehez problémának tekintik, ami egyszerűen azt jelenti, hogy túl bonyolult és szinte lehetetlen megoldani.
Sok esetben a -minimalizálási problémát relaxálják magasabb rendű normaproblémává, mint például a 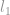 -minimalizálás és a -minimalizálás.
-minimalizálás és a -minimalizálás.
l1-norma
A norma definícióját követve a -norma a
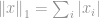
Ez a norma meglehetősen gyakori a normacsaládban. Sok neve és sok formája van a különböző területek között, nevezetesen a Manhattan norma a beceneve. Ha a -normát két vektor vagy mátrix különbségére számítjuk ki, azaz
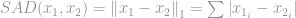
a számítógépes látáskutatók körében Sum of Absolute Difference (SAD) néven emlegetik.
A jelkülönbségmérés általánosabb esetében egységvektorra skálázható:
 ahol
ahol  egy méretű
egy méretű
amit Mean-Absolute Error (MAE) néven ismerünk.
l2-norma
A normák közül a legnépszerűbb a -norma. A mérnöki és az egész tudomány szinte minden területén használják. Az alapdefiníciót követve a -normát a következőképpen határozzuk meg:
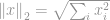
-norma jól ismert euklideszi norma, amelyet a vektorkülönbség mérésére használt szabványos mennyiségként használnak. Az -normához hasonlóan, ha az euklideszi normát egy vektorkülönbségre számoljuk ki, akkor azt euklideszi távolságnak nevezzük:
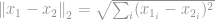
vagy négyzetes formában, amit a számítógépes látáskutatók körében négyzetes különbség összegének (SSD) neveznek:

A jelfeldolgozás területén legismertebb alkalmazása a Mean-Squared Error (MSE) mérés, amelyet két jel közötti hasonlóság, minőség vagy korreláció kiszámítására használnak. Az MSE
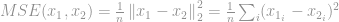
Amint azt korábban a -optimalizálás fejezetben tárgyaltuk, számos probléma miatt mind számítási szempontból, mind matematikai szempontból sok -optimalizálási probléma lazul el, hogy helyettük – és -optimalizálássá váljon. Emiatt most a -optimalizálásról lesz szó.
l2-optimalizálás
Mint a -optimalizálás esetében, a -norma minimalizálásának problémája a következőképpen fogalmazódik meg:
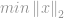 a
a
feltételezve, hogy a 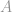 kényszermátrix teljes rangú, ez a probléma most egy alulterminált rendszer, amelynek végtelen sok megoldása van. A cél ebben az esetben az, hogy ezekből a végtelen sok megoldásból kihúzzuk a legjobb, azaz a legkisebb -normával rendelkező megoldást. Ez nagyon fárasztó munka lehetne, ha közvetlenül kellene kiszámítani. Szerencsére van egy matematikai trükk, ami sokat segíthet nekünk ebben a munkában.
kényszermátrix teljes rangú, ez a probléma most egy alulterminált rendszer, amelynek végtelen sok megoldása van. A cél ebben az esetben az, hogy ezekből a végtelen sok megoldásból kihúzzuk a legjobb, azaz a legkisebb -normával rendelkező megoldást. Ez nagyon fárasztó munka lehetne, ha közvetlenül kellene kiszámítani. Szerencsére van egy matematikai trükk, ami sokat segíthet nekünk ebben a munkában.
A Lagrange-szorzók trükközésével ezután definiálhatunk egy Lagrange

ahol  a bevezetett Lagrange-szorzók. Vegyük ennek az egyenletnek a deriváltját nullával egyenlőre, hogy megtaláljuk az optimális megoldást, és megkapjuk
a bevezetett Lagrange-szorzók. Vegyük ennek az egyenletnek a deriváltját nullával egyenlőre, hogy megtaláljuk az optimális megoldást, és megkapjuk
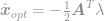
Ezt a megoldást bedugva a kényszerbe megkapjuk
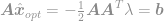
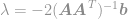
és végül
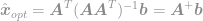
Az egyenlet segítségével most már azonnal kiszámíthatjuk a -optimalizálási feladat optimális megoldását. Ezt az egyenletet Moore-Penrose pszeudoinverzként ismerjük, magát a problémát pedig Legkisebb négyzet probléma, Legkisebb négyzet regresszió vagy Legkisebb négyzet optimalizálás néven szokták emlegetni.
Mindamellett, hogy a Legkisebb négyzet módszer megoldása könnyen kiszámítható, nem feltétlenül ez lesz a legjobb megoldás. Magának a -normának a simasága miatt nehéz egyetlen, legjobb megoldást találni a problémára.

Az -optimalizálás ezzel szemben sokkal jobb eredményt adhat, mint ez a megoldás.
l1-optimalizálás
A szokásos módon a -minimalizálási problémát a következőképpen fogalmazzuk meg:
 a
a
Mivel a -norma jellege nem sima, mint a -norma esetében, ennek a problémának a megoldása sokkal jobb és egyedibb, mint a -optimalizálásé.

Mégis, bár a -minimalizálás problémája majdnem ugyanolyan alakú, mint a -minimalizálásé, sokkal nehezebb megoldani. Mivel ennek a problémának nincs sima függvénye, az a trükk, amit a -probléma megoldására használtunk, már nem érvényes. Az egyetlen mód, ami maradt a megoldásának megtalálására, az a közvetlen keresés. A megoldás keresése azt jelenti, hogy minden egyes lehetséges megoldást ki kell számolnunk, hogy megtaláljuk a legjobbat a “végtelenül sok” lehetséges megoldásból.
Mivel nincs egyszerű módja annak, hogy ennek a problémának a megoldását matematikailag megtaláljuk, a -optimalizálás haszna évtizedek óta nagyon korlátozott. Egészen a közelmúltig a nagy számítási teljesítményű számítógépek fejlődése lehetővé tette, hogy “végigsöpörjük” az összes megoldást. Számos hasznos algoritmus, nevezetesen a konvex optimalizációs algoritmus, mint például a lineáris programozás, vagy a nemlineáris programozás stb. segítségével ma már lehetséges megtalálni a legjobb megoldást erre a kérdésre. Számos olyan alkalmazás, amely a -optimalizálásra támaszkodik, beleértve a kompresszív érzékelést is, most már lehetséges.
A -optimalizáláshoz ma már számos eszköztár áll rendelkezésre. Ezek az eszköztárak általában különböző megközelítéseket és/vagy algoritmusokat használnak ugyanazon kérdés megoldására. Ilyen eszköztárak például az l1-magic, SparseLab, ISAL1,
Most a normacsalád számos tagját tárgyaltuk, kezdve a -normától, a -normától és a -normától. Itt az ideje, hogy áttérjünk a következőre. Mivel már a legelején megbeszéltük, hogy a norma alapdefinícióját követve bármilyen l-vagyonú norma létezhet, sok időt fog igénybe venni, hogy mindegyikről beszéljünk. Szerencsére a -, – , és a -normán kívül a többi általában nem gyakori, és ezért nincs olyan sok érdekes dolog, amivel foglalkozhatnánk. Megnézzük tehát a norma szélsőséges esetét, ami a 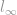 -norma (l-infinity norm).
-norma (l-infinity norm).
l-infinity norm
Mint mindig, a -norma definíciója
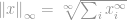
Most ez a definíció megint trükkösnek tűnik, de valójában elég egyenes. Tekintsük a  vektort, mondjuk, ha
vektort, mondjuk, ha 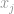 a legmagasabb bejegyzés a vektorban, maga a végtelen tulajdonsága alapján, azt mondhatjuk, hogy
a legmagasabb bejegyzés a vektorban, maga a végtelen tulajdonsága alapján, azt mondhatjuk, hogy
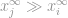

akkor
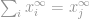
akkor
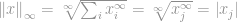
Most egyszerűen azt mondhatjuk, hogy a -norma

az a vektor legnagyobb bejegyzéseinek nagysága. Ez biztosan demisztifikálta a -norma
jelentését Most már megvitattuk a normák egész családját -től -ig, remélem, hogy ez a beszélgetés segít megérteni a norma jelentését, matematikai tulajdonságait és valós következményeit.
Hivatkozás és további olvasmányok:
Matematikai norma – wikipedia
Matematikai norma – MathWorld
Michael Elad – “Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing” , Springer, 2010.
Linear Programming – MathWorld
Compressive Sensing – Rice University
Szerkesztés (15/02/15) : Tartalmi pontatlanságokat javítottam.