Jeg har arbejdet meget med ting relateret til norm på det seneste, og det er på tide at tale om det. I dette indlæg skal vi diskutere en hel familie af norm.
Hvad er en norm?
Matematisk set er en norm en samlet størrelse eller længde af alle vektorer i et vektorrum eller matricer. For enkelhedens skyld kan vi sige, at jo højere normen er, jo større er (værdien i) matrixen eller vektoren. Norm kan komme i mange former og mange navne, herunder disse populære navn: Euklidisk afstand, Mean-squared Error osv.
De fleste gange vil du se, at normen optræder i en ligning som denne:
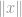 hvor
hvor  kan være en vektor eller en matrix.
kan være en vektor eller en matrix.
For eksempel er en euklidisk norm for en vektor 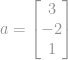
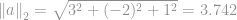 , som er størrelsen af vektor
, som er størrelsen af vektor 
Overstående eksempel viser, hvordan man beregner en euklidisk norm, eller formelt kaldet en 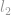 -norm. Der findes mange andre typer normer, som ligger uden for vores forklaring her, faktisk er der for hvert enkelt reelt tal en norm, der svarer til det (bemærk det fremhævede ord reelt tal, det betyder, at det ikke kun er begrænset til hele tal).
-norm. Der findes mange andre typer normer, som ligger uden for vores forklaring her, faktisk er der for hvert enkelt reelt tal en norm, der svarer til det (bemærk det fremhævede ord reelt tal, det betyder, at det ikke kun er begrænset til hele tal).
Formelt set er  -normen for
-normen for  defineret som:
defineret som:
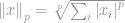 hvor
hvor 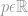
Det er det hele! En p-te rod af en summering af alle elementer til p-te potens er det, vi kalder en norm.
Det interessante er, at selv om alle -normer alle ligner hinanden meget, er deres matematiske egenskaber meget forskellige, og dermed er deres anvendelse også dramatisk forskellig. Hermed vil vi se nærmere på nogle af disse normer i detaljer.
l0-norm
Den første norm, vi vil diskutere, er en 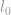 -norm. Per definition er -norm af
-norm. Per definition er -norm af
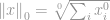
Strengt taget er -norm faktisk ikke en norm. Det er en kardinalitetsfunktion, som har sin definition i form af -norm, selv om mange kalder det en norm. Den er lidt vanskelig at arbejde med, fordi der er en tilstedeværelse af nul-power og nul-root i den. Naturligvis vil enhver 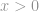 blive en sådan, men problemerne med definitionen af zeroth-power og især zeroth-root roder tingene rundt her. Så i virkeligheden bruger de fleste matematikere og ingeniører i stedet denne definition af -norm:
blive en sådan, men problemerne med definitionen af zeroth-power og især zeroth-root roder tingene rundt her. Så i virkeligheden bruger de fleste matematikere og ingeniører i stedet denne definition af -norm:
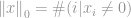
det er et samlet antal ikke-nul-elementer i en vektor.
Da det er et antal ikke-nul-elementer, er der så mange anvendelser, der bruger -norm. På det seneste er det endnu mere i fokus på grund af fremkomsten af Compressive Sensing-ordningen, som forsøger at finde den sparsomste løsning af det underbestemte lineære system. Ved den sparsomste løsning forstås den løsning, der har færrest ikke-nulposter, dvs. den laveste -norm. Dette problem betragtes normalt som et optimeringsproblem med -norm eller -optimering.
l0-optimering
Mange applikationer, herunder Compressive Sensing, forsøger at minimere -normen af en vektor, der svarer til nogle begrænsninger, og kaldes derfor “-minimisering”. Et standardminimeringsproblem er formuleret som:
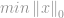 med forbehold af
med forbehold af 
Det er imidlertid ikke nogen nem opgave at gøre dette. På grund af manglen på -normens matematiske repræsentation betragtes -minimisering af dataloger som et NP-hårdt problem, hvilket ganske enkelt betyder, at det er for komplekst og næsten umuligt at løse.
I mange tilfælde er -minimiseringsproblemet afslappet til at være et normproblem af højere orden, såsom 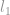 -minimisering og -minimisering.
-minimisering og -minimisering.
l1-norm
Ifølge definitionen af norm er -norm af defineret som
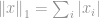
Denne norm er ganske almindelig blandt normfamilien. Den har mange navne og mange former blandt forskellige områder, nemlig Manhattan-norm er dens kælenavn. Hvis -normen beregnes for en forskel mellem to vektorer eller matricer, dvs.
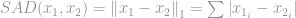
, kaldes den for Sum of Absolute Difference (SAD) blandt forskere inden for computervision.
I det mere generelle tilfælde af måling af signalforskelle kan den skaleres til en enhedsvektor ved:
 hvor
hvor  er en størrelse på .
er en størrelse på .
som er kendt som Mean-Absolute Error (MAE).
l2-norm
Den mest populære af alle normer er -normen. Den anvendes inden for næsten alle områder inden for teknik og videnskab som helhed. Efter den grundlæggende definition er -norm defineret som
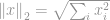
-norm er velkendt som en euklidisk norm, der bruges som en standardmængde til måling af en vektordifference. Som i -norm, hvis den euklidiske norm beregnes for en vektordifference, er den kendt som en euklidisk afstand:
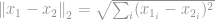
eller i sin kvadrerede form, kendt som en sum af kvadreret forskel (Sum of Squared Difference (SSD) blandt Computer Vision-forskere:

Dets mest kendte anvendelse inden for signalbehandlingsområdet er MSE-målingen (Mean-Squared Error), som bruges til at beregne en lighed, en kvalitet eller en korrelation mellem to signaler. MSE er
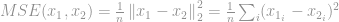
Som tidligere omtalt i afsnittet om -optimering slapper mange -optimeringsproblemer på grund af mange problemer fra både et beregningsteknisk synspunkt og et matematisk synspunkt af sig selv for i stedet at blive – og -optimering. På grund af dette vil vi nu diskutere om optimering af .
l2-optimering
Som i -optimeringstilfælde formuleres problemet med minimering af -norm ved
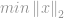 med forbehold af
med forbehold af
Hvis man antager, at begrænsningsmatrixen 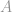 har fuld rang, er dette problem nu et underdertermineret system, som har uendelige løsninger. Målet i dette tilfælde er at udtrække den bedste løsning, dvs. har laveste -norm, blandt disse uendeligt mange løsninger. Dette kunne være et meget besværligt arbejde, hvis det skulle beregnes direkte. Heldigvis er der et matematisk trick, som kan hjælpe os meget i dette arbejde.
har fuld rang, er dette problem nu et underdertermineret system, som har uendelige løsninger. Målet i dette tilfælde er at udtrække den bedste løsning, dvs. har laveste -norm, blandt disse uendeligt mange løsninger. Dette kunne være et meget besværligt arbejde, hvis det skulle beregnes direkte. Heldigvis er der et matematisk trick, som kan hjælpe os meget i dette arbejde.
Ved hjælp af et trick med Lagrange-multiplikatorer kan vi så definere en lagrangian

hvor  er de indførte Lagrange-multiplikatorer. Tag afledning af denne ligning lig med nul for at finde en optimal løsning og få
er de indførte Lagrange-multiplikatorer. Tag afledning af denne ligning lig med nul for at finde en optimal løsning og få
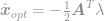
indsæt denne løsning i begrænsningen for at få
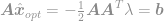
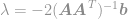
og endelig
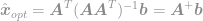
Ved hjælp af denne ligning kan vi nu straks beregne en optimal løsning af -optimeringsproblemet. Denne ligning er velkendt som Moore-Penrose Pseudoinverse, og selve problemet er normalt kendt som Least Square-problem, Least Square-regression eller Least Square-optimering.
Men selv om løsningen af Least Square-metoden er let at beregne, er det ikke nødvendigt, at det er den bedste løsning. På grund af -normens glatte natur i sig selv er det svært at finde en enkelt, bedste løsning til problemet.

Tværtimod kan -optimering give et langt bedre resultat end denne løsning.
l1-optimering
Som sædvanlig formuleres -minimeringsproblemet som
 med forbehold af
med forbehold af
Da -normens karakter ikke er glat som i -normens tilfælde, er løsningen af dette problem meget bedre og mere entydig end -optimeringen.

Men selv om problemet med -minimisering har næsten samme form som -minimiseringen, er det meget sværere at løse. Fordi dette problem ikke har en glat funktion, er det trick, vi brugte til at løse -problemet, ikke længere gyldigt. Den eneste måde, der er tilbage for at finde dets løsning, er at søge direkte efter det. At søge efter løsningen betyder, at vi skal beregne hver enkelt mulig løsning for at finde den bedste løsning fra puljen af “uendeligt mange” mulige løsninger.
Da der ikke er nogen nem måde at finde løsningen på dette problem matematisk, er -optimeringens nytteværdi meget begrænset i årtier. Indtil for nylig har udviklingen af computere med stor regnekraft gjort det muligt at “feje” gennem alle løsningerne. Ved at bruge mange nyttige algoritmer, nemlig den konvekse optimeringsalgoritme såsom lineær programmering eller ikke-lineær programmering osv. er det nu muligt at finde den bedste løsning på dette spørgsmål. Mange applikationer, der er afhængige af -optimering, herunder Compressive Sensing, er nu mulige.
Der findes i dag mange værktøjskasser til -optimering. Disse værktøjskasser anvender normalt forskellige tilgange og/eller algoritmer til at løse det samme spørgsmål. Eksemplet på disse værktøjskasser er l1-magic, SparseLab, ISAL1,
Nu har vi diskuteret mange medlemmer af normfamilien, begyndende med -norm, -norm og -norm. Det er tid til at gå videre til den næste. Da vi diskuterede helt fra starten, at der kan være enhver l-hvad-norm, der følger den samme grundlæggende definition af norm, vil det tage meget tid at tale om dem alle sammen. Heldigvis er det sådan, at bortset fra -, – , og -norm, er resten af dem normalt ualmindelige og har derfor ikke så mange interessante ting at se på. Så vi skal se på det ekstreme tilfælde af norm, som er en  -norm (l-infinity norm).
-norm (l-infinity norm).
l-infinity norm
Som altid er definitionen for -norm
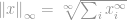
Nu ser denne definition igen vanskelig ud, men faktisk er den ret ligetil. Betragt vektoren  , lad os sige, om
, lad os sige, om 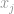 er den højeste post i vektoren , ved selve uendelighedens egenskab, kan vi sige, at
er den højeste post i vektoren , ved selve uendelighedens egenskab, kan vi sige, at
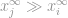

så
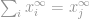
så
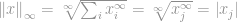
Nu kan vi simpelthen sige, at -normen er

det er den maksimale posters størrelse i denne vektor. Det afmystificerede sikkert betydningen af -norm
Nu har vi diskuteret hele familien af norm fra til , og jeg håber, at denne diskussion vil hjælpe med at forstå betydningen af norm, dens matematiske egenskaber og dens implikationer i den virkelige verden.
Reference og yderligere læsning:
Matematisk norm – wikipedia
Matematisk norm – MathWorld
Michael Elad – “Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing” , Springer, 2010.
Linear Programming – MathWorld
Compressive Sensing – Rice University
Edit (15/02/15) : Rettet unøjagtigheder i indholdet.