Indledning
Med en øget efterspørgsel efter pålidelige og effektive infrastrukturer, der er designet til at betjene kritiske systemer, kunne begreberne skalerbarhed og høj tilgængelighed ikke være mere populære. Mens håndtering af øget systembelastning er en fælles bekymring, er det lige så vigtigt at mindske nedetid og eliminere enkeltstående fejlpunkter. Høj tilgængelighed er en kvalitet af infrastrukturdesign på skala, der tager højde for disse sidstnævnte overvejelser.
I denne vejledning vil vi diskutere, hvad høj tilgængelighed præcist betyder, og hvordan det kan forbedre din infrastrukturs pålidelighed.
Hvad er høj tilgængelighed?
I databehandling bruges udtrykket tilgængelighed til at beskrive den periode, hvor en tjeneste er tilgængelig, samt den tid, som et system skal bruge til at reagere på en anmodning fra en bruger. Høj tilgængelighed er en kvalitet af et system eller en komponent, der sikrer et højt niveau af operationel ydeevne i en given periode.
Måling af tilgængelighed
Beredygtighed udtrykkes ofte som en procentdel, der angiver, hvor meget oppetid der forventes af et bestemt system eller en bestemt komponent i en given periode, hvor en værdi på 100 % vil betyde, at systemet aldrig fejler. F.eks. kan et system, der garanterer 99 % tilgængelighed i en periode på et år, have op til 3,65 dages nedetid (1 %).
Disse værdier beregnes på grundlag af flere faktorer, herunder både planlagte og uplanlagte vedligeholdelsesperioder samt tiden til at genoprette fra en eventuel systemfejl.
Hvordan fungerer høj tilgængelighed?
Høj tilgængelighed fungerer som en fejlreaktionsmekanisme for infrastruktur. Den måde, den fungerer på, er ret enkel konceptuelt set, men kræver typisk noget specialiseret software og konfiguration.
Hvornår er høj tilgængelighed vigtig?
Når man opsætter robuste produktionssystemer, er det ofte en høj prioritet at minimere nedetid og serviceafbrydelser. Uanset hvor pålidelige dine systemer og din software er, kan der opstå problemer, som kan få dine applikationer eller dine servere til at gå ned.
Indførelse af høj tilgængelighed for din infrastruktur er en nyttig strategi til at reducere virkningen af disse typer hændelser. Systemer med høj tilgængelighed kan automatisk genoprette fra server- eller komponentfejl.
Hvad gør et system høj tilgængelighed?
Et af målene med høj tilgængelighed er at eliminere enkeltstående fejlpunkter i din infrastruktur. Et single point of failure er en komponent i din teknologistak, som ville forårsage en serviceafbrydelse, hvis den blev utilgængelig. Som sådan betragtes enhver komponent, der er en forudsætning for, at din applikation kan fungere korrekt, og som ikke har redundans, som et single point of failure.
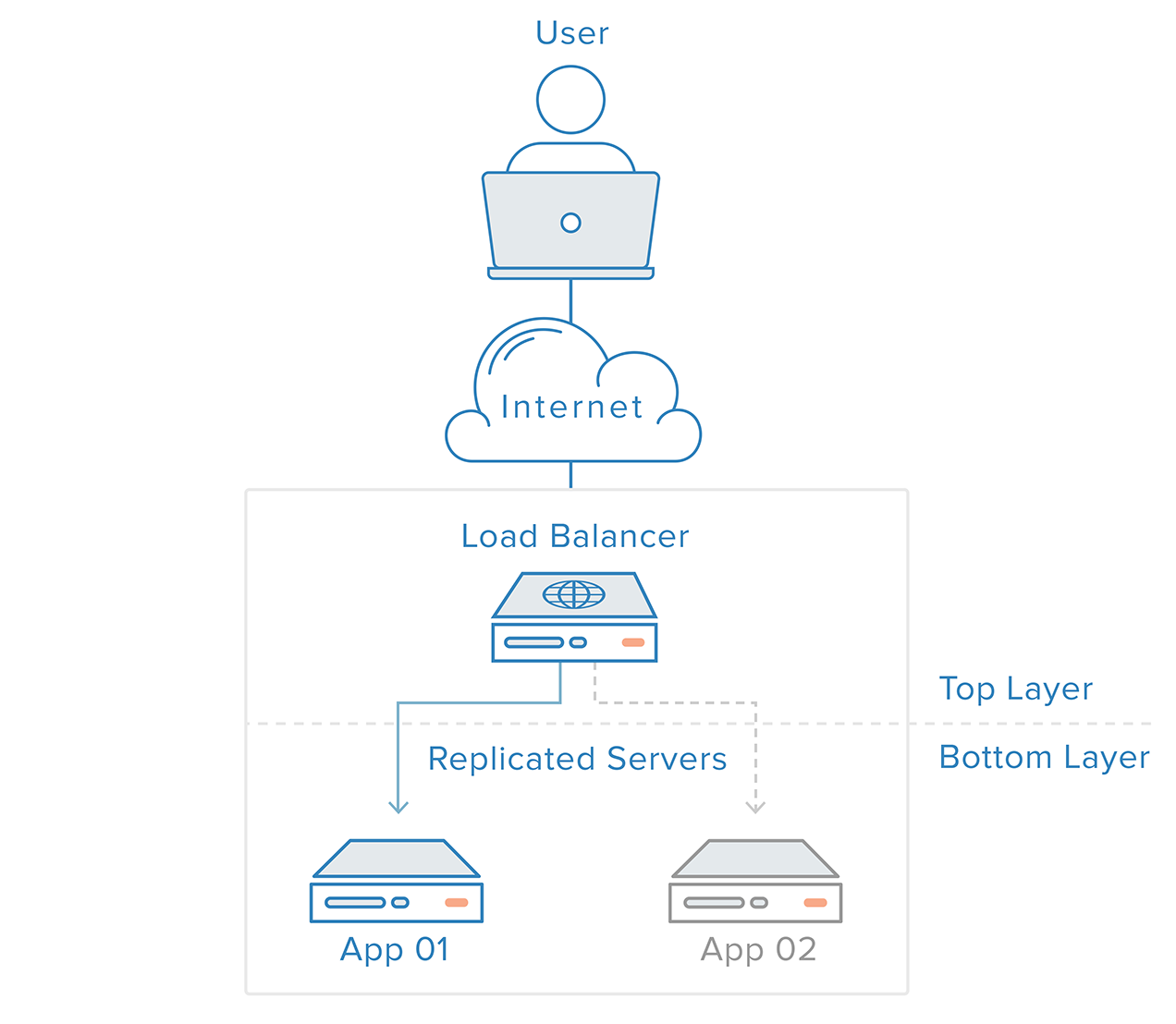
For at eliminere single point of failure skal hvert lag af din stak være forberedt på redundans. Forestil dig f.eks. at du har en infrastruktur bestående af to identiske, redundante webservere bag en load balancer. Trafikken fra kunderne vil blive fordelt ligeligt mellem webserverne, men hvis en af serverne går ned, vil load balanceren omdirigere al trafik til den resterende online server.
Webserverlaget i dette scenarie er ikke et enkelt fejlpunkt, fordi:
- der er redundante komponenter til den samme opgave på plads
- mekanismen ovenpå dette lag (load balancer) er i stand til at opdage fejl i komponenterne og tilpasse sin adfærd med henblik på en rettidig genopretning
Men hvad sker der, hvis load balancer går offline?
Med det beskrevne scenarie, som ikke er ualmindeligt i det virkelige liv, forbliver selve load balancing-laget et single point of failure. Det kan imidlertid være en udfordring at eliminere dette tilbageværende enkeltfejlpunkt; selv om du nemt kan konfigurere en ekstra load balancer for at opnå redundans, er der ikke et oplagt punkt over load balancerne til at implementere fejlfinding og genopretning.
Redundans alene kan ikke garantere høj tilgængelighed. Der skal være en mekanisme til at opdage fejl og træffe foranstaltninger, når en af komponenterne i din stak bliver utilgængelig.
Fejldetektion og genopretning af fejl for redundante systemer kan implementeres ved hjælp af en tilgang fra top til bund: Laget øverst bliver ansvarlig for at overvåge det lag, der ligger umiddelbart under det, for fejl. I vores tidligere eksempelscenarie er load balancer-anlægget det øverste lag. Hvis en af webserverne (det nederste lag) bliver utilgængelig, vil load balanceren holde op med at videresende anmodninger til den pågældende server.
Denne tilgang har en tendens til at være enklere, men den har begrænsninger: Der vil være et punkt i din infrastruktur, hvor et øverste lag enten ikke eksisterer eller er uden for rækkevidde, hvilket er tilfældet med load balancer-laget. Oprettelse af en fejlopdagelsestjeneste for load balanceren i en ekstern server ville blot skabe et nyt single point of failure.
Med et sådant scenarie er det nødvendigt med en distribueret tilgang. Flere redundante knuder skal forbindes sammen som en klynge, hvor hver knude skal være lige så god til at opdage og genoprette fejl.
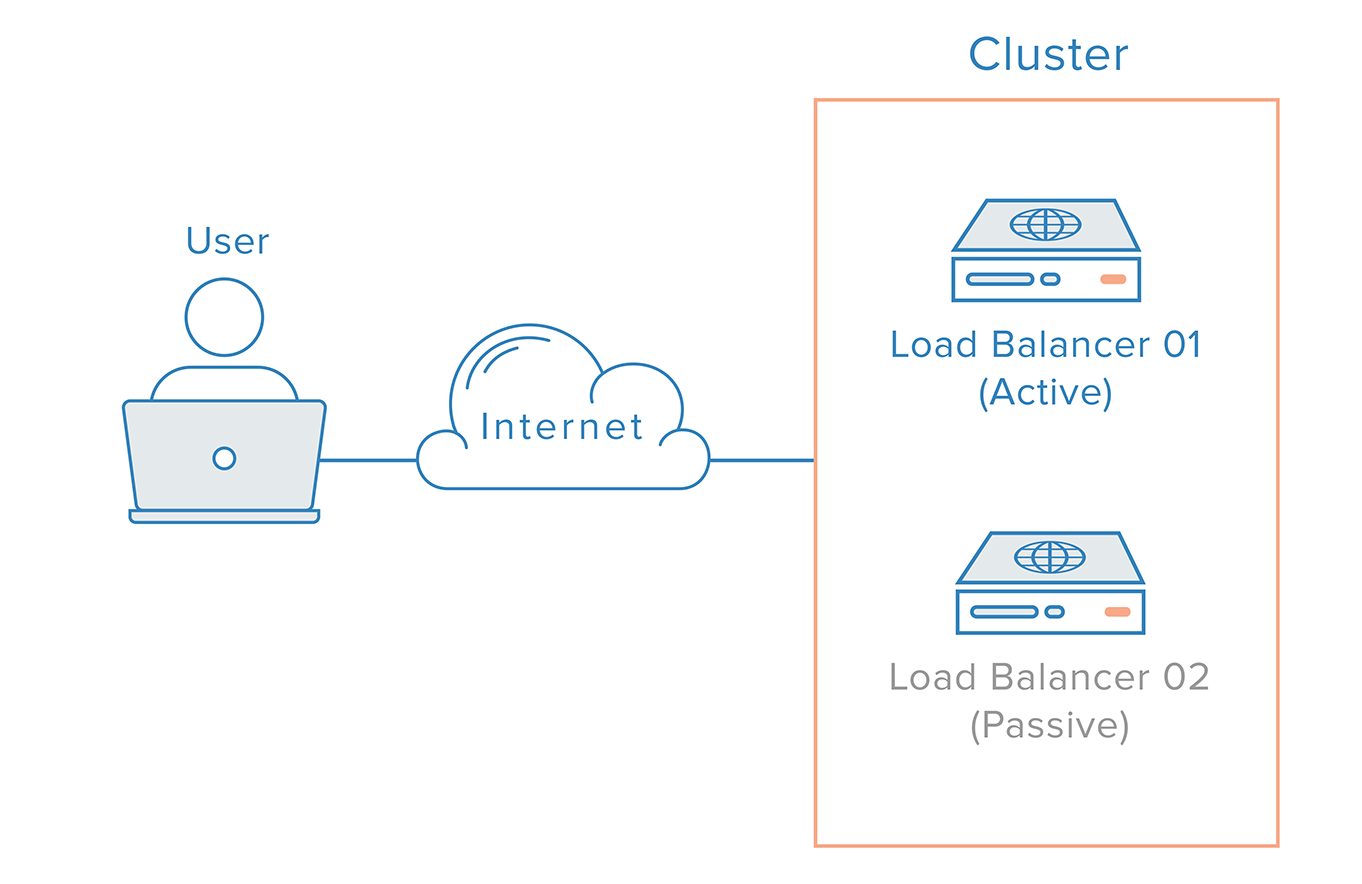
For load balancer-sagen er der dog en ekstra komplikation på grund af den måde, navneservere fungerer på. Genopretning efter en fejl i en load balancer betyder typisk en failover til en redundant load balancer, hvilket indebærer, at der skal foretages en DNS-ændring for at pege et domænenavn til den redundante load balancer’s IP-adresse. En sådan ændring kan tage lang tid at blive udbredt på internettet, hvilket ville medføre en alvorlig nedetid for dette system.
En mulig løsning er at anvende DNS round-robin load balancing. Denne fremgangsmåde er imidlertid ikke pålidelig, da den overlader failover til klientsideapplikationen.
En mere robust og pålidelig løsning er at anvende systemer, der giver mulighed for fleksibel genplacering af IP-adresser, f.eks. flydende IP’er. Ved at genanvende IP-adresser efter behov fjernes de problemer med udbredelse og caching, der er forbundet med DNS-ændringer, ved at give en statisk IP-adresse, som nemt kan genanvendes, når der er behov for det. Domænenavnet kan forblive tilknyttet den samme IP-adresse, mens selve IP-adressen flyttes mellem servere.
Sådan ser en infrastruktur med høj tilgængelighed ved hjælp af flydende IP’er ud:

Hvilke systemkomponenter er nødvendige for høj tilgængelighed?
Der er flere komponenter, der skal tages nøje i betragtning for at implementere høj tilgængelighed i praksis. Høj tilgængelighed er langt mere end en softwareimplementering og afhænger af faktorer som:
- Miljø: Hvis alle dine servere er placeret i det samme geografiske område, kan en miljømæssig tilstand som f.eks. et jordskælv eller en oversvømmelse ødelægge hele dit system. Hvis du har redundante servere i forskellige datacentre og geografiske områder, vil det øge pålideligheden.
- Hardware: Højtilgængelige servere skal være modstandsdygtige over for strømafbrydelser og hardwarefejl, herunder harddiske og netværksgrænseflader.
- Software: Hele softwarestakken, herunder operativsystemet og selve applikationen, skal være forberedt på at kunne håndtere uventede fejl, som f.eks. kan kræve en genstart af systemet.
- Data: Datatab og inkonsistens kan skyldes flere faktorer, og det er ikke begrænset til fejl på harddisken. Højtilgængelige systemer skal tage højde for datasikkerhed i tilfælde af en fejl.
- Netværk: Uplanlagte netværksafbrydelser udgør et andet muligt fejlpunkt for højtilgængelige systemer. Det er vigtigt, at der er en redundant netværksstrategi for mulige svigt.
Hvilken software kan bruges til at konfigurere høj tilgængelighed?
Hvert lag af et system med høj tilgængelighed vil have forskellige behov med hensyn til software og konfiguration. På applikationsniveauet er load balancers imidlertid et vigtigt stykke software til oprettelse af enhver højtilgængelighedsopsætning.
HAProxy (High Availability Proxy) er et almindeligt valg til belastningsbalancering, da den kan håndtere belastningsbalancering på flere lag og for forskellige typer servere, herunder databaseservere.
Ved at bevæge sig opad i systemstakken er det vigtigt at implementere en pålidelig redundant løsning for dit applikationsindgangspunkt, normalt belastningsbalanceren. For at fjerne dette single point of failure skal vi som tidligere nævnt implementere en klynge af load balancere bag en Floating IP. Corosync og Pacemaker er populære valg til at skabe en sådan opsætning på både Ubuntu- og CentOS-servere.
Konklusion
Høj tilgængelighed er en vigtig delmængde af pålidelighedsteknik, der fokuserer på at sikre, at et system eller en komponent har et højt niveau af operationel ydeevne i et givet tidsrum. Ved første øjekast kan gennemførelsen heraf virke ret kompleks; den kan imidlertid give enorme fordele for systemer, der kræver øget pålidelighed.