Inledning
Med en ökad efterfrågan på tillförlitliga och effektiva infrastrukturer som är utformade för att betjäna kritiska system kan termerna skalbarhet och hög tillgänglighet inte vara mer populära. Även om hanteringen av ökad systembelastning är ett vanligt bekymmer är det lika viktigt att minska stilleståndstiden och eliminera enstaka felpunkter. Hög tillgänglighet är en kvalitet på infrastrukturdesign i skala som behandlar dessa senare överväganden.
I den här guiden kommer vi att diskutera vad exakt hög tillgänglighet innebär och hur den kan förbättra din infrastrukturs tillförlitlighet.
Vad är hög tillgänglighet?
Inom datateknik används begreppet tillgänglighet för att beskriva den tidsperiod under vilken en tjänst är tillgänglig, samt den tid som krävs för att ett system ska kunna svara på en förfrågan som görs av en användare. Hög tillgänglighet är en kvalitet hos ett system eller en komponent som garanterar en hög nivå av driftsprestanda under en viss tidsperiod.
Mätning av tillgänglighet
Ansvarighet uttrycks ofta som en procentsats som anger hur mycket drifttid som förväntas av ett visst system eller en viss komponent under en viss tidsperiod, där ett värde på 100 % skulle betyda att systemet aldrig går sönder. Till exempel kan ett system som garanterar 99 % tillgänglighet under en period av ett år ha upp till 3,65 dagars driftstopp (1 %).
Dessa värden beräknas utifrån flera faktorer, inklusive både schemalagda och oplanerade underhållsperioder, samt tiden för att återhämta sig från ett eventuellt systemfel.
Hur fungerar hög tillgänglighet?
Hög tillgänglighet fungerar som en mekanism för att reagera på fel i infrastrukturen. Det sätt på vilket det fungerar är ganska enkelt konceptuellt men kräver vanligtvis viss specialiserad programvara och konfiguration.
När är hög tillgänglighet viktigt?
När man inrättar robusta produktionssystem är det ofta en hög prioritet att minimera stilleståndstid och tjänsteavbrott. Oavsett hur tillförlitliga dina system och programvaror är kan problem uppstå som kan få dina program eller servrar att stanna.
Installation av hög tillgänglighet för din infrastruktur är en användbar strategi för att minska effekterna av dessa typer av händelser. Högtillgängliga system kan återhämta sig automatiskt från server- eller komponentfel.
Vad gör ett system högtillgängligt?
Ett av målen med högtillgänglighet är att eliminera enskilda felpunkter i din infrastruktur. En single point of failure är en komponent i din teknikstack som skulle orsaka ett tjänsteavbrott om den blev otillgänglig. Alla komponenter som är nödvändiga för att din applikation ska fungera korrekt och som inte har redundans anses vara en enda felpunkt.
För att eliminera enskilda felpunkter måste varje lager i din stapel vara förberett för redundans. Tänk dig till exempel att du har en infrastruktur som består av två identiska, redundanta webbservrar bakom en lastutjämnare. Trafiken från kunderna kommer att fördelas lika mellan webbservrarna, men om en av servrarna går ner kommer lastbalansen att omdirigera all trafik till den återstående online-servern.
Webbserverlagret i detta scenario är inte en enda felpunkt eftersom:
- redundanta komponenter för samma uppgift finns på plats
- Mekanismen ovanpå detta lager (lastbalansen) kan upptäcka fel i komponenterna och anpassa sitt beteende för en snabb återhämtning
Men vad händer om lastbalansen går offline?
Med det beskrivna scenariot, som inte är ovanligt i verkligheten, förblir själva lastbalanseringslagret en enda felpunkt. Att eliminera denna återstående enda felpunkt kan dock vara en utmaning; även om du enkelt kan konfigurera ytterligare en lastbalanserare för att uppnå redundans, finns det ingen självklar punkt ovanför lastbalanserna för att implementera feldetektering och återställning.
Redundans ensam kan inte garantera hög tillgänglighet. Det måste finnas en mekanism för att upptäcka fel och vidta åtgärder när en av komponenterna i din stack blir otillgänglig.
Felupptäckt och återhämtning för redundanta system kan implementeras med hjälp av ett tillvägagångssätt uppifrån och ned: lagret ovanpå blir ansvarigt för att övervaka lagret omedelbart under det för fel. I vårt tidigare exempelscenario är lastutjämnaren det översta lagret. Om en av webbservrarna (det nedre lagret) blir otillgänglig kommer lastbalansen att sluta omdirigera förfrågningar till den specifika servern.
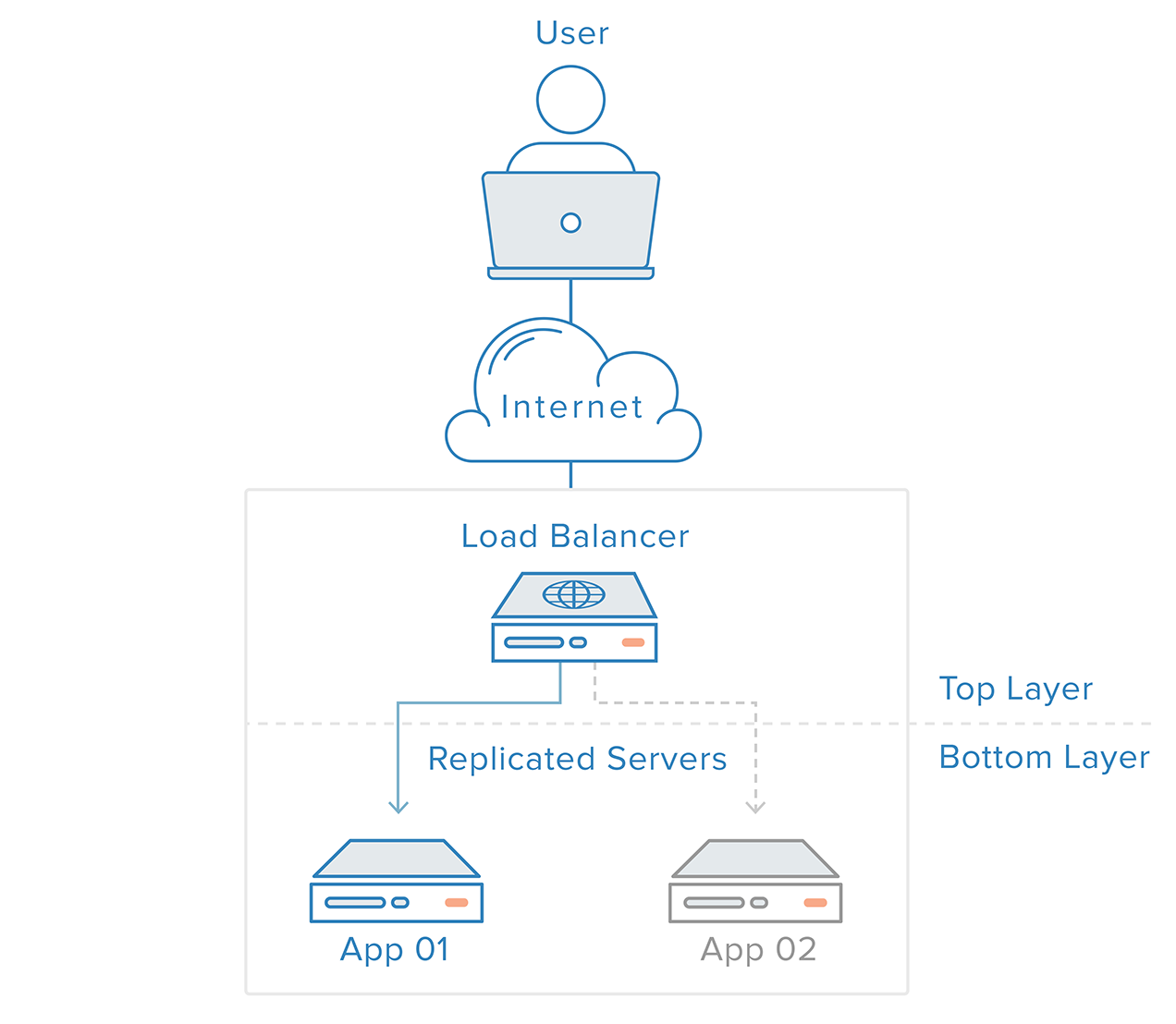
Detta tillvägagångssätt tenderar att vara enklare, men det har begränsningar: det kommer att finnas en punkt i din infrastruktur där ett toppskikt antingen inte existerar eller är utom räckhåll, vilket är fallet med lastbalanseringsskiktet. Att skapa en tjänst för upptäckt av fel för lastutjämnaren i en extern server skulle helt enkelt skapa en ny enda felpunkt.
Med ett sådant scenario är ett distribuerat tillvägagångssätt nödvändigt. Flera redundanta noder måste anslutas till varandra som ett kluster där varje nod bör ha samma förmåga att upptäcka och återställa fel.
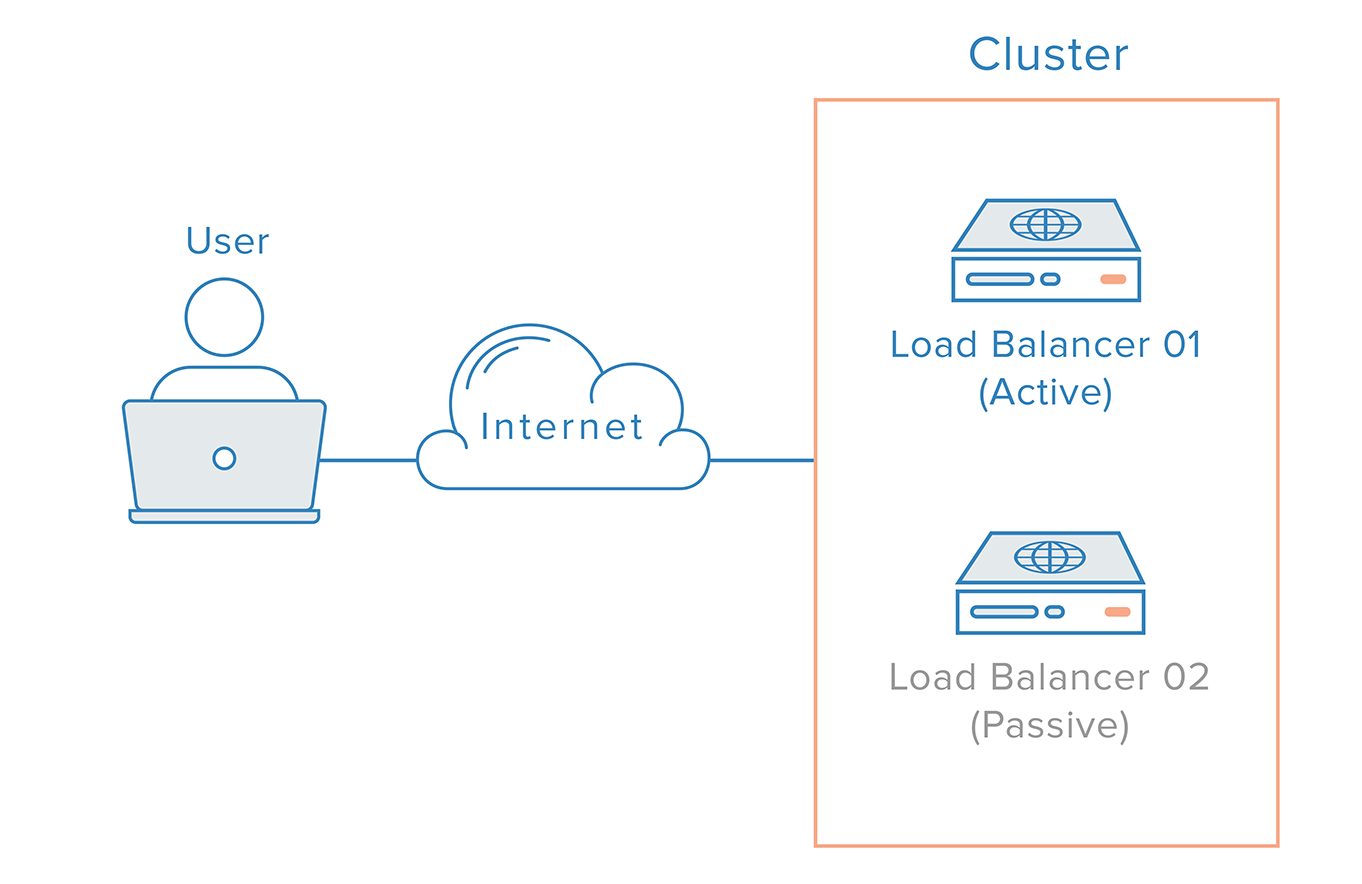
För load balancer-fallet finns det dock ytterligare en komplikation på grund av hur namnservrar fungerar. Återhämtning från ett lastbalanserarfel innebär vanligtvis en övergång till en redundant lastbalanserar, vilket innebär att en DNS-ändring måste göras för att peka ett domännamn till den redundanta lastbalanserarens IP-adress. En sådan ändring kan ta avsevärd tid innan den sprids på Internet, vilket skulle orsaka en allvarlig nedtid för detta system.
En möjlig lösning är att använda sig av DNS round-robin lastbalansering. Detta tillvägagångssätt är dock inte tillförlitligt eftersom det lämnar failover till applikationen på klientsidan.
En mer robust och tillförlitlig lösning är att använda system som tillåter flexibel omplacering av IP-adresser, t.ex. flytande IP-adresser. Om IP-adresser återskapas på begäran eliminerar man de problem med spridning och caching som följer av DNS-ändringar genom att tillhandahålla en statisk IP-adress som enkelt kan återskapas när det behövs. Domännamnet kan förbli förknippat med samma IP-adress, medan själva IP-adressen flyttas mellan servrar.
Så här ser en högtillgänglig infrastruktur ut som använder flytande IP-adresser:

Vilka systemkomponenter krävs för hög tillgänglighet?
Det finns flera komponenter som noga måste beaktas för att genomföra hög tillgänglighet i praktiken. Hög tillgänglighet är mycket mer än en programvaruimplementering och beror på faktorer som:
- Miljö: Om alla dina servrar är placerade i samma geografiska område kan ett miljöförhållande, t.ex. en jordbävning eller en översvämning, få hela systemet att stanna. Att ha redundanta servrar i olika datacenter och geografiska områden ökar tillförlitligheten.
- Hårdvara: Servrar med hög tillgänglighet bör vara motståndskraftiga mot strömavbrott och hårdvarufel, inklusive hårddiskar och nätverksgränssnitt.
- Mjukvara: Hela mjukvarustapeln, inklusive operativsystemet och själva applikationen, måste vara förberedd på att hantera oväntade fel som eventuellt kan kräva till exempel en omstart av systemet.
- Data: Dataförlust och inkonsekvens kan orsakas av flera faktorer, och det är inte begränsat till hårddiskfel. Högtillgängliga system måste ta hänsyn till datasäkerheten i händelse av fel.
- Nätverk: Oplanerade nätverksavbrott utgör en annan möjlig felpunkt för högtillgängliga system. Det är viktigt att det finns en redundant nätverksstrategi för eventuella fel.
Vilken programvara kan användas för att konfigurera hög tillgänglighet?
Varje lager i ett högtillgängligt system kommer att ha olika behov när det gäller programvara och konfiguration. På applikationsnivå är dock lastutjämnare en viktig del av programvaran för att skapa en högtillgänglig installation.
HAProxy (High Availability Proxy) är ett vanligt val för lastbalansering, eftersom den kan hantera lastbalansering på flera lager och för olika typer av servrar, inklusive databasservrar.
Om man rör sig uppåt i systemstapeln är det viktigt att implementera en tillförlitlig redundant lösning för din applikations ingångspunkt, vanligtvis lastbalansen. För att ta bort denna enda felpunkt måste vi, som tidigare nämnts, implementera ett kluster av lastutjämnare bakom en Floating IP. Corosync och Pacemaker är populära val för att skapa en sådan uppsättning, på både Ubuntu- och CentOS-servrar.
Slutsats
Hög tillgänglighet är en viktig delmängd av tillförlitlighetsteknik, inriktad på att säkerställa att ett system eller en komponent har en hög nivå av driftsprestanda under en viss tidsperiod. Vid en första anblick kan genomförandet av denna metod verka ganska komplicerat, men den kan ge enorma fördelar för system som kräver ökad tillförlitlighet.