Jag har jobbat mycket med saker som har med norm att göra på sistone och det är dags att prata om det. I det här inlägget kommer vi att diskutera en hel familj av normer.
Vad är en norm?
Matematiskt sett är en norm den totala storleken eller längden på alla vektorer i ett vektorrum eller matriser. För enkelhetens skull kan vi säga att ju högre normen är, desto större är (värdet i) matrisen eller vektorn. Norm kan komma i många former och med många namn, inklusive dessa populära namn: Euklidiskt avstånd, medelkvadratiskt fel, etc.
För det mesta kommer du att se att normen förekommer i en ekvation som denna:
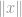 där
där  kan vara en vektor eller en matris.
kan vara en vektor eller en matris.
En euklidisk norm för en vektor 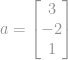 är till exempel
är till exempel 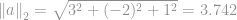 vilket är storleken på vektor
vilket är storleken på vektor 
Ovanstående exempel visar hur man beräknar en euklidisk norm, eller formellt kallad  -norm. Det finns många andra typer av normer som vi inte kan förklara här, faktiskt finns det en norm som motsvarar varje enskilt reellt tal (lägg märke till det betonade ordet reellt tal, det betyder att det inte är begränsat till bara heltal).
-norm. Det finns många andra typer av normer som vi inte kan förklara här, faktiskt finns det en norm som motsvarar varje enskilt reellt tal (lägg märke till det betonade ordet reellt tal, det betyder att det inte är begränsat till bara heltal).
Formellt definieras  -normen för
-normen för  som:
som:
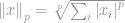 där
där 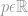
Det är allt! En p-te rot av en summering av alla element till p-te potensen är vad vi kallar en norm.
Den intressanta punkten är att även om alla -normer ser väldigt lika ut, så är deras matematiska egenskaper väldigt olika och därmed är deras tillämpning också dramatiskt annorlunda. Härmed ska vi titta närmare på några av dessa normer.
l0-norm
Den första normen vi ska diskutera är en 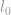 -norm. Per definition är -normen för
-norm. Per definition är -normen för
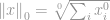
Strikt sett är -normen egentligen inte en norm. Det är en kardinalitetsfunktion som har sin definition i form av -norm, även om många kallar det för en norm. Den är lite knepig att arbeta med eftersom det finns en förekomst av zeroth-power och zeroth-root i den. Självklart kommer alla 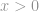 att bli en sådan, men problemen med definitionen av zeroth-power och särskilt zeroth-root ställer till det här. Så i verkligheten använder de flesta matematiker och ingenjörer denna definition av -norm i stället:
att bli en sådan, men problemen med definitionen av zeroth-power och särskilt zeroth-root ställer till det här. Så i verkligheten använder de flesta matematiker och ingenjörer denna definition av -norm i stället:
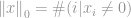
Det är ett totalt antal icke-noll-element i en vektor.
Då det är ett antal icke-noll-element, finns det så många tillämpningar som använder -norm. På senare tid har den hamnat ännu mer i fokus på grund av Compressive Sensing-principen, som går ut på att hitta den sparsammaste lösningen på det underbestämda linjära systemet. Med den sparsammaste lösningen menas den lösning som har minst antal icke-nollposter, dvs. den lägsta -normen. Detta problem betraktas vanligen som ett optimeringsproblem med -norm eller -optimering.
l0-optimering
Många tillämpningar, inklusive Compressive Sensing, försöker minimera -normen för en vektor som motsvarar vissa begränsningar, och kallas därför ”-minimering”. Ett standardminimeringsproblem formuleras som:
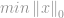 med
med 
Det är dock ingen lätt uppgift att göra detta. På grund av bristen på -normens matematiska representation betraktas -minimering av datavetare som ett NP-hårt problem, vilket helt enkelt innebär att det är för komplext och nästan omöjligt att lösa.
I många fall är -minimeringsproblem avslappnat till högre ordningens normproblem som 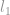 -minimering och -minimering.
-minimering och -minimering.
l1-norm
Följande definitionen av norm definieras -norm för som
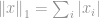
Denna norm är ganska vanlig bland normfamiljen. Den har många namn och många former bland olika områden, nämligen Manhattan norm är dess smeknamn. Om -normen beräknas för en skillnad mellan två vektorer eller matriser, det vill säga
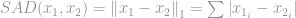
, kallas den för Sum of Absolute Difference (SAD) bland forskare inom datorseende.
I ett mer allmänt fall av mätning av signaldifferens kan den skalas till en enhetsvektor genom:
 där
där  är en storlek på .
är en storlek på .
vilket är känt som Mean-Absolute Error (MAE).
l2-norm
Den mest populära av alla normer är -normen. Den används inom nästan alla områden inom teknik och vetenskap som helhet. Enligt den grundläggande definitionen definieras -normen som
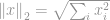
-normen är välkänd som en euklidisk norm, som används som en standardmängd för att mäta en vektordifferens. Liksom i -norm, om den euklidiska normen beräknas för en vektordifferens, är den känd som ett euklidiskt avstånd:
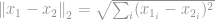
eller i sin kvadratiska form, känd som en summa av kvadratisk skillnad (Sum of Squared Difference, SSD) bland forskare inom datorseende:

Den mest kända tillämpningen inom signalbehandlingsområdet är MSE-måttet (Mean-Squared Error), som används för att beräkna en likhet, en kvalitet eller en korrelation mellan två signaler. MSE är
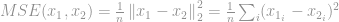
Som tidigare diskuterats i -optimeringsavsnittet, på grund av många problem från både en beräkningssynpunkt och en matematisk synpunkt, slappnar många -optimeringsproblem av för att istället bli – och -optimering. På grund av detta kommer vi nu att diskutera om optimering av .
l2-optimering
Som i -optimeringsfallet formuleras problemet med att minimera -normen genom
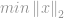 med förbehåll för
med förbehåll för
Antag att tvångsmatrisen  har full rang, är detta problem nu ett underderminerat system som har oändliga lösningar. Målet i detta fall är att ur dessa oändligt många lösningar dra ut den bästa lösningen, dvs. som har lägst -norm, från dessa oändligt många lösningar. Detta skulle kunna bli ett mycket tråkigt arbete om det skulle beräknas direkt. Som tur är finns det ett matematiskt knep som kan hjälpa oss mycket i detta arbete.
har full rang, är detta problem nu ett underderminerat system som har oändliga lösningar. Målet i detta fall är att ur dessa oändligt många lösningar dra ut den bästa lösningen, dvs. som har lägst -norm, från dessa oändligt många lösningar. Detta skulle kunna bli ett mycket tråkigt arbete om det skulle beräknas direkt. Som tur är finns det ett matematiskt knep som kan hjälpa oss mycket i detta arbete.
Med hjälp av ett knep med Lagrange-multiplikatorer kan vi sedan definiera en lagrangian

där  är den införda Lagrange-multiplikatorn. Ta derivatan av denna ekvation lika med noll för att hitta en optimal lösning och få
är den införda Lagrange-multiplikatorn. Ta derivatan av denna ekvation lika med noll för att hitta en optimal lösning och få
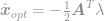
plugga in denna lösning i begränsningen för att få
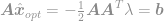
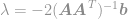
och slutligen
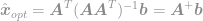
Med hjälp av denna ekvation kan vi nu omedelbart beräkna en optimal lösning av -optimeringsproblemet. Denna ekvation är välkänd som Moore-Penrose Pseudoinverse och själva problemet brukar kallas Least Square-problem, Least Square-regression eller Least Square-optimering.
Men även om lösningen med Least Square-metoden är lätt att beräkna är det inte nödvändigtvis den bästa lösningen. På grund av -normens jämna natur i sig är det svårt att hitta en enda, bästa lösning för problemet.

Tvärtom kan -optimering ge ett mycket bättre resultat än denna lösning.
l1-optimering
Som vanligt formuleras -minimeringsproblemet som
 med förbehåll för
med förbehåll för
Om -normens karaktär inte är lika jämn som i -normfallet är lösningen på detta problem mycket bättre och mer unik än -optimeringen.

Men även om problemet med -minimering har nästan samma form som -minimering är det mycket svårare att lösa. Eftersom detta problem inte har en jämn funktion är det trick vi använde för att lösa -problemet inte längre giltigt. Det enda sättet som återstår för att hitta dess lösning är att söka efter den direkt. Att söka efter lösningen innebär att vi måste beräkna varje enskild möjlig lösning för att hitta den bästa från poolen av ”oändligt många” möjliga lösningar.
Då det inte finns något enkelt sätt att matematiskt hitta lösningen på detta problem, är användbarheten av -optimering mycket begränsad under årtionden. Fram till nyligen har utvecklingen av datorer med hög beräkningskraft gjort det möjligt för oss att ”svepa” igenom alla lösningar. Genom att använda många användbara algoritmer, nämligen den konvexa optimeringsalgoritmen såsom linjär programmering, eller icke-linjär programmering, etc. är det nu möjligt att hitta den bästa lösningen på denna fråga. Många tillämpningar som bygger på -optimering, bland annat Compressive Sensing, är nu möjliga.
Det finns många verktygslådor för -optimering tillgängliga nuförtiden. Dessa verktygslådor använder vanligtvis olika metoder och/eller algoritmer för att lösa samma fråga. Exempel på dessa verktygslådor är l1-magic, SparseLab, ISAL1,
Nu har vi diskuterat många medlemmar av normfamiljen, med utgångspunkt i -norm, -norm och -norm. Det är dags att gå vidare till nästa. Eftersom vi redan i början diskuterade att det kan finnas vilken l-vad-norm som helst som följer samma grundläggande definition av norm, kommer det att ta mycket tid att prata om dem alla. Lyckligtvis är det så att bortsett från -, – och -norm är resten av dem oftast ovanliga och har därför inte så många intressanta saker att titta på. Så vi ska titta på extremfallet av norm som är en  -norm (l-infinity norm).
-norm (l-infinity norm).
l-infinity norm
Som alltid är definitionen för -norm
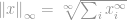
Nu ser den här definitionen återigen knepig ut, men den är faktiskt ganska rak. Betrakta vektorn  , låt oss säga om
, låt oss säga om 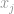 är den högsta posten i vektorn , genom egenskapen oändligheten själv, kan vi säga att
är den högsta posten i vektorn , genom egenskapen oändligheten själv, kan vi säga att
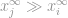

då
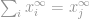
då
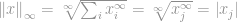
Nu kan vi helt enkelt säga att -normen är

därmed är den högsta postens storlek i denna vektor. Det avmystifierade säkert innebörden av -norm
Nu har vi diskuterat hela familjen av norm från till , jag hoppas att den här diskussionen hjälper till att förstå innebörden av norm, dess matematiska egenskaper och dess implikationer i den verkliga världen.
Referenser och vidare läsning:
Matematisk norm – wikipedia
Matematisk norm – MathWorld
Michael Elad – ”Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing” , Springer, 2010.
Linear Programming – MathWorld
Compressive Sensing – Rice University
Redigera (15/02/15) : Korrigerade felaktigheter i innehållet.