Introducere
Cu o cerere crescută pentru infrastructuri fiabile și performante concepute pentru a deservi sisteme critice, termenii de scalabilitate și înaltă disponibilitate nu ar putea fi mai populari. În timp ce gestionarea încărcăturii crescute a sistemului este o preocupare comună, diminuarea timpilor de nefuncționare și eliminarea punctelor unice de eșec sunt la fel de importante. Disponibilitatea ridicată este o calitate a proiectării infrastructurii la scară care abordează aceste din urmă considerente.
În acest ghid, vom discuta ce înseamnă exact disponibilitatea ridicată și cum poate îmbunătăți fiabilitatea infrastructurii dumneavoastră.
Ce este disponibilitatea ridicată?
În informatică, termenul de disponibilitate este utilizat pentru a descrie perioada de timp în care un serviciu este disponibil, precum și timpul necesar unui sistem pentru a răspunde la o solicitare făcută de un utilizator. Disponibilitatea ridicată este o calitate a unui sistem sau a unei componente care asigură un nivel ridicat de performanță operațională pentru o anumită perioadă de timp.
Măsurarea disponibilității
Disponibilitatea este adesea exprimată ca un procent care indică cât de mult timp de funcționare se așteaptă de la un anumit sistem sau componentă într-o anumită perioadă de timp, unde o valoare de 100% ar indica faptul că sistemul nu se defectează niciodată. De exemplu, un sistem care garantează o disponibilitate de 99% într-o perioadă de un an poate avea până la 3,65 zile de indisponibilitate (1%).
Aceste valori sunt calculate pe baza mai multor factori, inclusiv perioadele de mentenanță programate și neprogramate, precum și timpul de recuperare după o eventuală defecțiune a sistemului.
Cum funcționează înalta disponibilitate?
Înalta disponibilitate funcționează ca un mecanism de răspuns la defecțiuni pentru infrastructură. Modul în care funcționează este destul de simplu din punct de vedere conceptual, dar necesită, de obicei, un software și o configurație specializată.
Când este importantă înalta disponibilitate?
Când se configurează sisteme de producție robuste, reducerea la minimum a timpilor de nefuncționare și a întreruperilor de servicii este adesea o prioritate ridicată. Indiferent de cât de fiabile sunt sistemele și software-ul dumneavoastră, pot apărea probleme care să vă pună la pământ aplicațiile sau serverele.
Implementarea unei disponibilități ridicate pentru infrastructura dumneavoastră este o strategie utilă pentru a reduce impactul acestor tipuri de evenimente. Sistemele cu disponibilitate ridicată se pot recupera automat în cazul unei defecțiuni a unui server sau a unei componente.
Ce face un sistem cu disponibilitate ridicată?
Unul dintre obiectivele disponibilității ridicate este eliminarea punctelor unice de defecțiune din infrastructura dumneavoastră. Un punct unic de eșec este o componentă a stivei dumneavoastră tehnologice care ar provoca o întrerupere a serviciului dacă ar deveni indisponibilă. Ca atare, orice componentă care este necesară pentru buna funcționalitate a aplicației dvs. și care nu are redundanță este considerată a fi un punct unic de eșec.
Pentru a elimina punctele unice de eșec, fiecare strat al stivei dvs. trebuie să fie pregătit pentru redundanță. De exemplu, imaginați-vă că aveți o infrastructură formată din două servere web identice, redundante, în spatele unui load balancer. Traficul care vine de la clienți va fi distribuit în mod egal între serverele web, dar dacă unul dintre servere cade, echilibrul de sarcină va redirecționa tot traficul către serverul rămas online.
În acest scenariu, stratul serverului web nu reprezintă un singur punct de eșec deoarece:
- există componente redundante pentru aceeași sarcină
- mecanismul de deasupra acestui strat (echilibrul de sarcină) este capabil să detecteze eșecurile componentelor și să își adapteze comportamentul pentru o recuperare în timp util
Dar ce se întâmplă dacă echilibrul de sarcină rămâne offline?
Cu scenariul descris, care nu este neobișnuit în viața reală, stratul de echilibrare a sarcinii în sine rămâne un singur punct de eșec. Cu toate acestea, eliminarea acestui punct unic de eșec rămas poate fi o provocare; chiar dacă puteți configura cu ușurință un dispozitiv de echilibrare a sarcinii suplimentar pentru a obține redundanță, nu există un punct evident deasupra dispozitivului de echilibrare a sarcinii pentru a implementa detectarea și recuperarea eșecurilor.
Redundanța singură nu poate garanta o disponibilitate ridicată. Trebuie să existe un mecanism pentru a detecta defecțiunile și a acționa atunci când una dintre componentele stivei dvs. devine indisponibilă.
Detecția și recuperarea în caz de defecțiune pentru sistemele redundante pot fi implementate folosind o abordare de sus în jos: stratul de sus devine responsabil pentru monitorizarea stratului imediat sub el pentru detectarea defecțiunilor. În scenariul din exemplul nostru anterior, echilibrul de sarcină este stratul de sus. Dacă unul dintre serverele web (stratul inferior) devine indisponibil, echilibrul de sarcină va înceta să redirecționeze cererile pentru acel server specific.
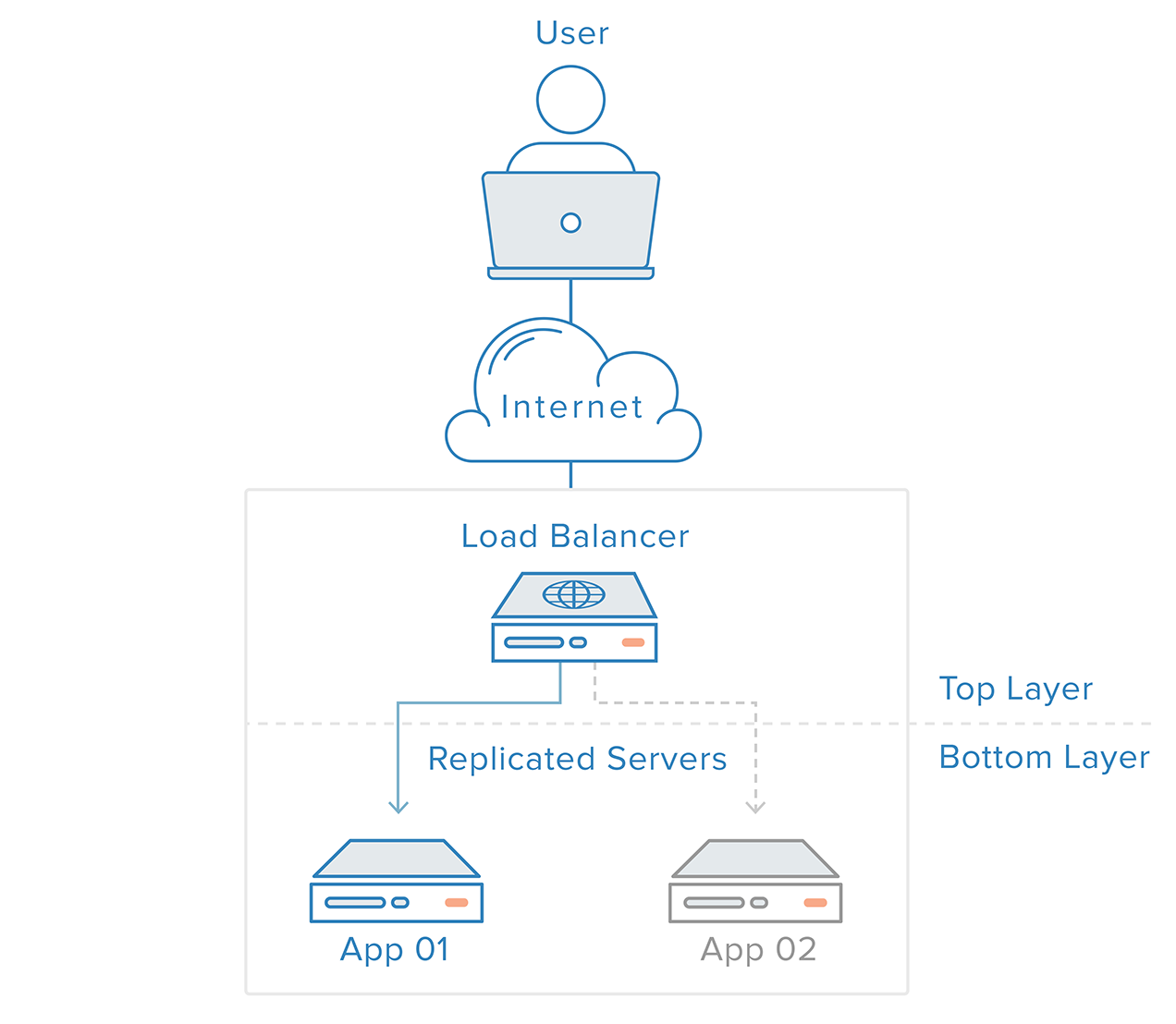
Această abordare tinde să fie mai simplă, dar are limitări: va exista un punct în infrastructura dvs. în care un strat superior este fie inexistent, fie imposibil de atins, ceea ce este cazul stratului de echilibrare a sarcinii. Crearea unui serviciu de detectare a eșecurilor pentru echilibrul de sarcină într-un server extern ar crea pur și simplu un nou punct unic de eșec.
În cazul unui astfel de scenariu, este necesară o abordare distribuită. Mai multe noduri redundante trebuie să fie conectate între ele sub forma unui cluster în care fiecare nod trebuie să fie la fel de capabil să detecteze și să recupereze defecțiunile.
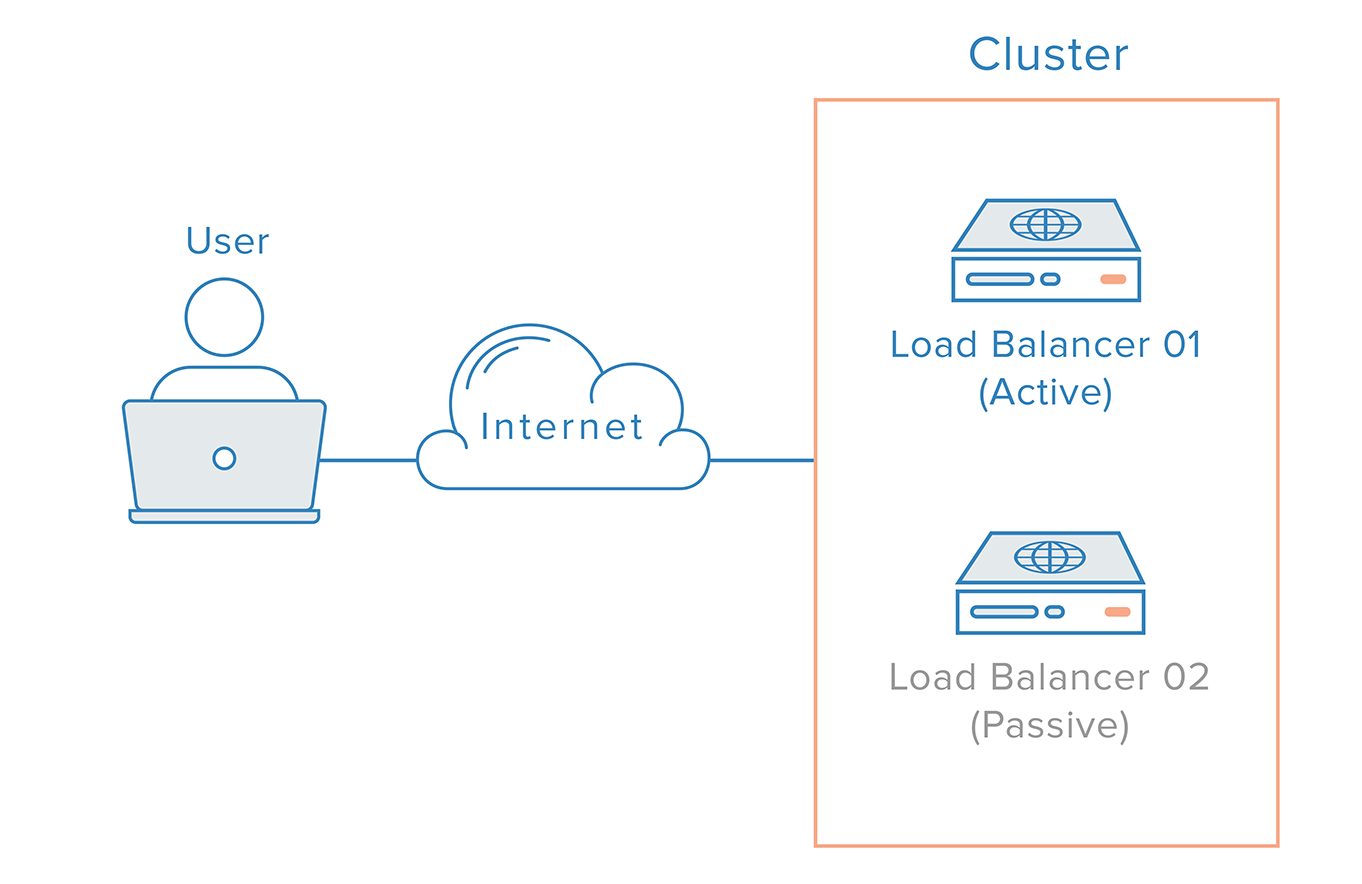
Pentru cazul echilibrului de sarcină, există însă o complicație suplimentară, datorită modului în care funcționează nameserverele. Recuperarea în urma unei defecțiuni a unui balanțator de sarcină înseamnă, de obicei, un failover către un balanțator de sarcină redundant, ceea ce implică faptul că trebuie efectuată o modificare DNS pentru a îndrepta un nume de domeniu către adresa IP a balanțatorului de sarcină redundant. O astfel de modificare poate dura o perioadă de timp considerabilă pentru a fi propagată pe Internet, ceea ce ar cauza o întrerupere serioasă a acestui sistem.
O posibilă soluție este utilizarea echilibrării de sarcină DNS round-robin. Cu toate acestea, această abordare nu este fiabilă, deoarece lasă failoverul în sarcina aplicației din partea clientului.
O soluție mai robustă și mai fiabilă este utilizarea unor sisteme care permit refacerea flexibilă a adreselor IP, cum ar fi IP-urile flotante. Refacerea la cerere a adreselor IP elimină problemele de propagare și de caching inerente modificărilor DNS prin furnizarea unei adrese IP statice care poate fi refăcută cu ușurință atunci când este necesar. Numele de domeniu poate rămâne asociat cu aceeași adresă IP, în timp ce adresa IP în sine este mutată între servere.
Acesta este modul în care arată o infrastructură cu disponibilitate ridicată care utilizează IP-uri flotante:

Ce componente de sistem sunt necesare pentru disponibilitate ridicată?
Există mai multe componente care trebuie luate în considerare cu atenție pentru implementarea disponibilității ridicate în practică. Mult mai mult decât o implementare software, disponibilitatea ridicată depinde de factori precum:
- Mediul înconjurător: dacă toate serverele dvs. sunt localizate în aceeași zonă geografică, o condiție de mediu, cum ar fi un cutremur sau o inundație, ar putea pune la pământ întregul sistem. Faptul de a avea servere redundante în centre de date și zone geografice diferite va crește fiabilitatea.
- Hardware: serverele cu disponibilitate ridicată ar trebui să fie rezistente la întreruperi de curent și la defecțiuni hardware, inclusiv hard disk-uri și interfețe de rețea.
- Software: întreaga stivă de software, inclusiv sistemul de operare și aplicația în sine, trebuie să fie pregătită să gestioneze defecțiuni neașteptate care ar putea necesita, de exemplu, o repornire a sistemului.
- Date: pierderea și inconsistența datelor pot fi cauzate de mai mulți factori, și nu se limitează la defecțiuni ale hard disk-ului. Sistemele cu disponibilitate ridicată trebuie să țină cont de siguranța datelor în cazul unei defecțiuni.
- Rețea: întreruperile neplanificate ale rețelei reprezintă un alt punct posibil de eșec pentru sistemele cu disponibilitate ridicată. Este important să existe o strategie de rețea redundantă pentru eventualele defecțiuni.
Ce software poate fi utilizat pentru a configura disponibilitatea ridicată?
Care strat al unui sistem cu disponibilitate ridicată va avea nevoi diferite în ceea ce privește software-ul și configurația. Cu toate acestea, la nivelul aplicațiilor, echilibratoarele de sarcină reprezintă o piesă software esențială pentru crearea oricărei configurații de înaltă disponibilitate.
HAProxy (High Availability Proxy) este o alegere obișnuită pentru echilibrarea încărcăturii, deoarece poate gestiona echilibrarea încărcăturii la mai multe niveluri și pentru diferite tipuri de servere, inclusiv servere de baze de date.
Mai sus în stiva sistemului, este important să se implementeze o soluție redundantă fiabilă pentru punctul de intrare al aplicației, în mod normal echilibrul de sarcină. Pentru a elimina acest punct unic de eșec, așa cum am menționat anterior, trebuie să implementăm un cluster de load balancers în spatele unui IP flotant. Corosync și Pacemaker sunt alegeri populare pentru crearea unei astfel de configurații, atât pe serverele Ubuntu, cât și pe cele CentOS.
Concluzie
Disponibilitatea ridicată este un subset important al ingineriei fiabilității, axat pe asigurarea faptului că un sistem sau o componentă are un nivel ridicat de performanță operațională într-o anumită perioadă de timp. La prima vedere, implementarea sa ar putea părea destul de complexă; cu toate acestea, poate aduce beneficii extraordinare pentru sistemele care necesită o fiabilitate sporită
.