W tym artykule dowiemy się, jak zidentyfikować i rozwiązać problem fragmentacji indeksów w SQL Server. Identyfikacja fragmentacji indeksów oraz ich konserwacja są ważnymi częściami zadań związanych z utrzymaniem bazy danych. Microsoft SQL Server aktualizuje statystyki indeksów podczas operacji wstawiania, aktualizacji lub usuwania danych z tabeli. Fragmentacja indeksu jest wartością procentową wydajności indeksu, która może być pobrana przez SQL Server DMV. Zgodnie z wartością wydajności indeksu, użytkownicy mogą wykonać konserwację indeksów poprzez zmianę wartości procentowej fragmentacji za pomocą operacji Rebuild lub Reorganize.
Dlaczego wartość procentowa fragmentacji indeksu się zmienia?
Wartość procentowa fragmentacji indeksu zmienia się, gdy logiczne kolejność stron nie jest skoordynowana z fizyczną kolejnością stron w alokacji strony indeksu. W przypadku modyfikacji danych w tabeli można zmienić rozmiar informacji na stronie danych. Strona ta była zapełniona przed operacją aktualizacji tabeli. Jednak po operacji aktualizacji tabeli na stronie danych można było znaleźć wolne miejsce. Użytkownicy mogą zaobserwować zakłócenia porządku strony przy masowej operacji usuwania tabeli. Wraz z operacjami aktualizacji i usuwania, strona danych nie będzie ani wypełniona od góry, ani pusta. Dlatego też, niewykorzystana wolna przestrzeń podnosi niedopasowanie kolejności między logiczną stroną a fizyczną stroną wraz ze wzrostem fragmentacji, a to może spowodować najgorszą wydajność zapytania i zużywa więcej zasobów serwera, jak również.
Bardziej istotne jest, aby podkreślić, że fragmentacja indeksu wpływa na wydajność zapytania tylko z skanowania strony. W takich przypadkach, zwiększa to szanse na niską wydajność innych zapytań SQL, ponieważ zapytanie z wysokim pofragmentowanym indeksem nad tabelą zajmuje więcej czasu na wykonanie i zużywa więcej zasobów takich jak Cache, CPU i IO. Dlatego też, pozostałe zapytania SQL mają trudności z zakończeniem operacji przy niespójnych zasobach serwera. Nawet blokowanie może wystąpić przez operacje Update i Delete, ponieważ optymalizator nie będzie zbierał informacji o fragmentacji indeksu podczas generowania planu wykonania dla zapytania.
Może być wiele indeksów utworzonych na jednej tabeli z kombinacją różnych kolumn, a każdy indeks może mieć inny procent fragmentacji. Teraz, przed uczynieniem go odpowiednim lub podjęciem indeksu w konserwacji, użytkownicy muszą znaleźć tę wartość progową z bazy danych. Poniższa instrukcja T-SQL jest skutecznym sposobem na znalezienie jej z dokładnością do obiektu.SQL
|
1
2
3
4
5
6
. 7
8
9
10
11
12
13
14
|
SELECT S.name as 'Schema’,
T.name as 'Table’,
I.name as 'Index’,
DDIPS.avg_fragmentation_in_percent,
DDIPS.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS DDIPS
INNER JOIN sys.tables T on T.object_id = DDIPS.object_id
INNER JOIN sys.schemas S on T.schema_id = S.schema_id
INNER JOIN sys.indexes I ON I.object_id = DDIPS.object_id
AND DDIPS.index_id = I.index_id
WHERE DDIPS.database_id = DB_ID()
and I.name is not null
AND DDIPS.avg_fragmentation_in_percent > 0
ORDER BY DDIPS.avg_fragmentation_in_percent desc
|
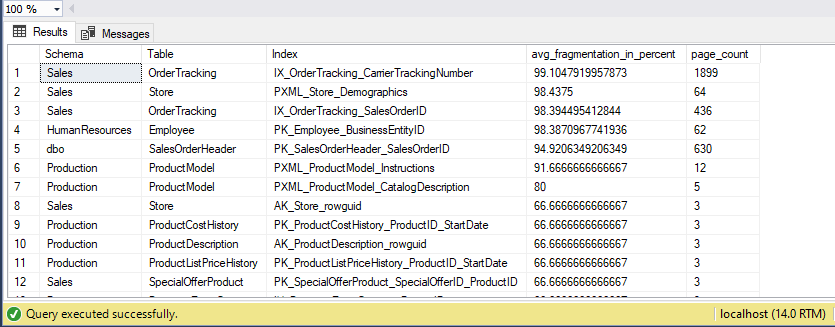
Tutaj widzimy, że maksymalny średni procent fragmentacji jest zauważalny jako 99%, który musi być zaangażowany z działaniem mającym na celu zmniejszenie fragmentacji z wyborem REBUILD lub REORGANIZE. REBUILD lub REORGANIZE jest poleceniem konserwacji indeksu, które może być wykonane za pomocą instrukcji ALTER INDEX. Użytkownicy mogą wykonać to polecenie również przy użyciu SSMS.
Rebuild and Reorganize Index using SQL Server Management Studio (SSMS)
Znajdź i rozwiń tabelę w Object Explorer >> Otwórz Indeksy >> Kliknij prawym przyciskiem myszy na nazwę indeksu docelowego >> Przebuduj lub przeorganizuj.
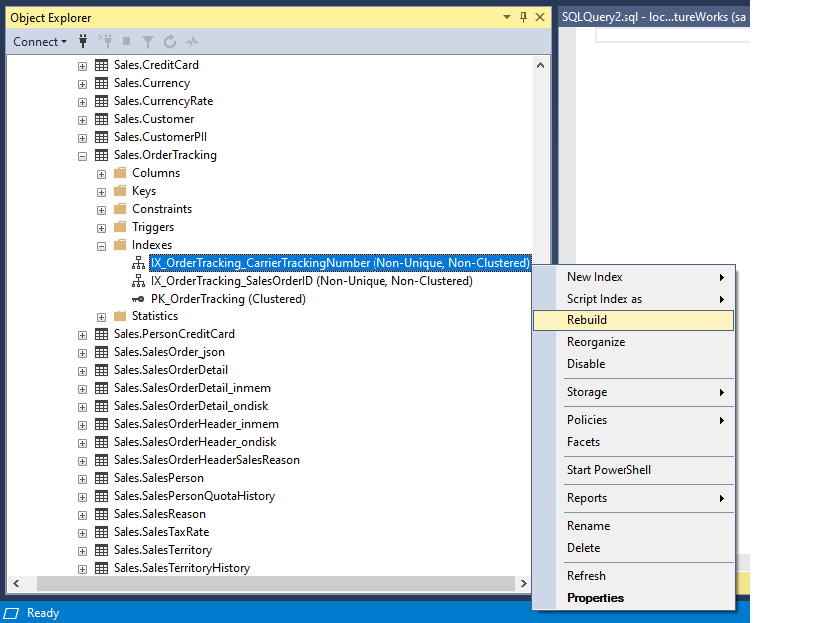
Jak widać na powyższym obrazku, REBUILD i REORGANIZE są dwoma dostępnymi opcjami do przeprowadzenia operacji przycinania na stronie. Idealnie byłoby, gdyby operacja ta została wykonana poza godzinami szczytu, aby uniknąć jej wpływu na inne transakcje i użytkowników. Microsoft SQL Server Enterprise Edition obsługuje funkcje indeksowania online i offline za pomocą REBUILD.
REBUILD INDEX
INDEX REBUILD zawsze usuwa indeks i odtwarza go z nowymi stronami indeksu. Czynność ta może być wykonywana równolegle przy użyciu opcji online (Enterprise Edition) z poleceniem ALTER INDEX, co nie ma wpływu na działające żądania i zadania podobnej tabeli.
REBUILD Indeks może być ustawiony w trybie online lub offline przy użyciu poniższych poleceń SQL:
|
1
2
3
4
5
|
–Podstawowa komenda rebuild
ALTER INDEX Index_Name ON Table_Name REBUILD
-.-REBUILD Index with ONLINE OPTION
ALTER INDEX Index_Name ON Table_Name REBUILD WITH(ONLINE=ON) | WITH(ONLINE=ON)
|
Jeśli użytkownik wykona REBUILD INDEX w trybie offline, wówczas zasób obiektowy (tabela) indeksu nie będzie dostępny do końca zakończenia procesu REBUILD. Wpływa to również na wiele innych transakcji, które są powiązane z tym obiektem. Operacja odbudowy indeksu powoduje odtworzenie indeksu. W związku z tym generuje nowe statystyki i dołącza zapisy dziennika indeksu do pliku dziennika transakcji bazy danych.
Na przykład, przed przebudową indeksu, weźmy aktualny przydział stron dla indeksu bazy danych AdventureWorks, tabeli Sales.OrderTracking i indeksu IX_OrderTracking_CarrierTrackingNumber o nazwie.
|
1
2
3
4
5
|
SELECT OBJECT_NAME(IX.object_id) as db_name, si.name, extent_page_id, allocated_page_page_id, previous_page_page_id, next_page_page_id
FROM sys.dm_db_database_page_allocations(DB_ID(’AdventureWorks’), OBJECT_ID(’Sales.OrderTracking’),NULL, NULL, 'DETAILED’) IX
INNER JOIN sys.indexes si on IX.object_id = si.object_id AND IX.index_id = si.index_id
WHERE si.name = 'IX_OrderTracking_CarrierTrackingNumber’
ORDER BY allocated_page_id
|
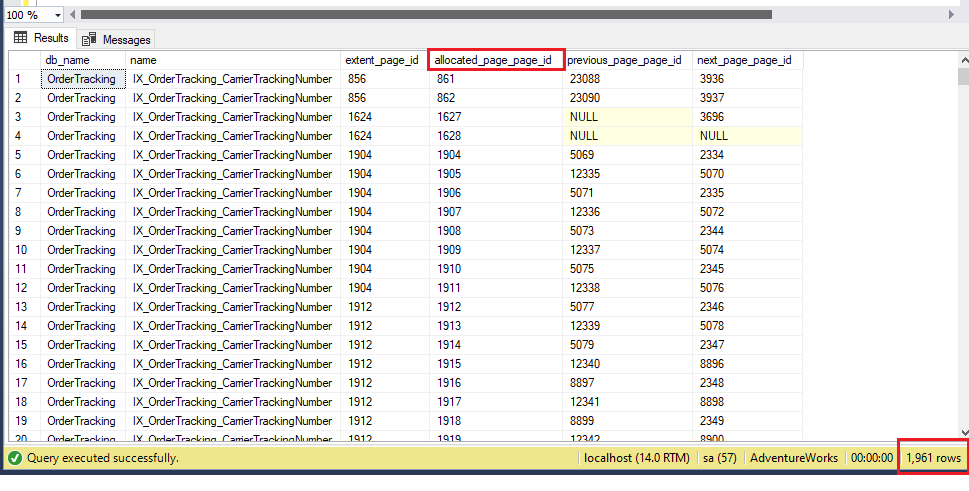
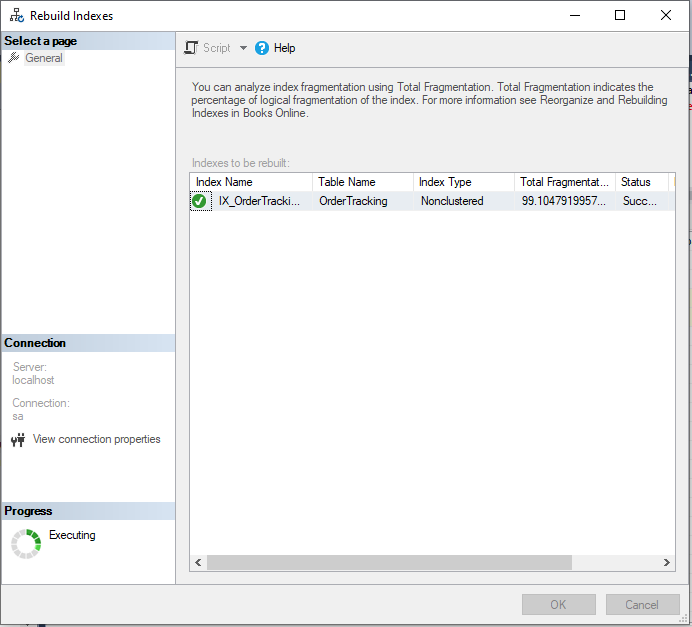
Tutaj, 1961 stron istnieje w pliku bazy danych dla tego indeksu, a pierwsze 5 stron to 861, 862, 1627, 1628 i 1904 w kolejności numerów stron. Teraz odbudujmy indeks za pomocą SSMS.
Operacja Index REBUILD została zakończona pomyślnie i pobierz ponownie referencje alokacji stron dla tego samego indeksu za pomocą tego samego zapytania T-SQL.
|
1
2
3
4
5
6
|
SELECT OBJECT_NAME(IX.object_id) as db_name, si.name, extent_page_id, allocated_page_page_id,
previous_page_page_id, next_page_page_id
FROM sys.dm_db_database_page_allocations(DB_ID(’AdventureWorks’), OBJECT_ID(’Sales.OrderTracking’),NULL, NULL, 'DETAILED’) IX
INNER JOIN sys.indexes si on IX.object_id = si.object_id AND IX.index_id = si.index_id
WHERE si.name = 'IX_OrderTracking_CarrierTrackingNumber’
ORDER BY allocated_page_id
|
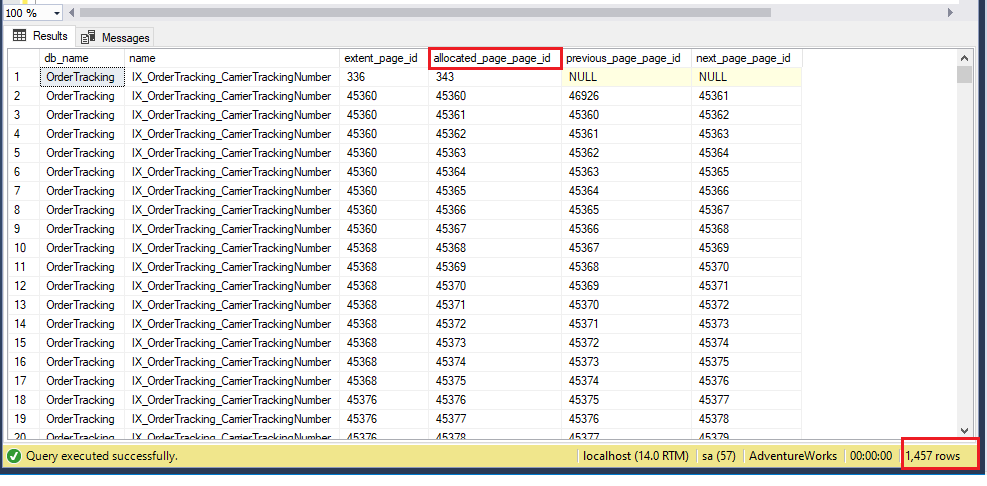
Po przebudowie indeksu odświeżona liczba stron wynosi 1457, która wcześniej wynosiła 1961. Jeśli sprawdzisz pierwsze 5 przydzielonych stron tego samego indeksu, został on zmieniony z nowymi referencjami stron. Zakłada to, że indeks jest porzucany i tworzony ponownie. Powinniśmy sprawdzić odświeżony procent fragmentacji dla tego samego indeksu, i jak widać poniżej, wynosi on teraz 0.1%.
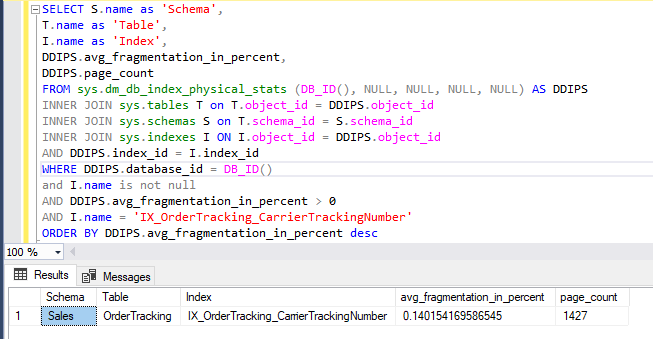
REBUILD clustered index nad tabelą wpływa również na inne indeksy tabeli, ponieważ REBUILD clustered index przebudowuje również nieklastrowy indeks tabeli. Wykonaj operację przebudowy wszystkich indeksów tabeli lub bazy danych łącznie; użytkownik może użyć polecenia DBCC DBREINDEX().
|
1
|
DBCC DBREINDEX (’DatabaseName’, 'TableName’);
|
REORGANIZED INDEX
Polecenie REORGANIZE INDEX zmienia kolejność stron indeksu poprzez usunięcie wolnego lub nieużywanego miejsca na stronie. W idealnym przypadku strony indeksu są fizycznie uporządkowane w pliku danych. Polecenie REORGANIZE nie usuwa i nie tworzy indeksu, lecz jedynie zmienia układ informacji na stronie. REORGANIZE nie ma możliwości wyboru opcji offline, a REORGANIZE nie wpływa na statystyki w porównaniu z opcją REBUILD. REORGANIZE wykonuje się zawsze w trybie online.
Na przykład przed wykonaniem REORGANIZE nad indeksem wykonajmy odczyt fragmentacji dla bazy danych „AdventureWorks”, tabeli „Sales.OrderTracking” i indeksu o nazwie „IX_OrderTracking_SalesOrderID”.
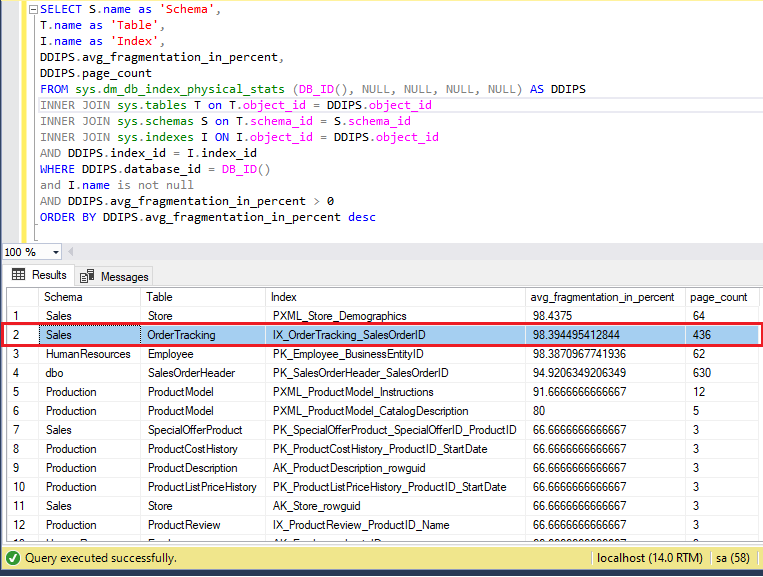
W tym przypadku procent fragmentacji indeksu wynosi 98,39 przed wykonaniem REORGANIZE. Poniższa lista na obrazku to strony alokacji do indeksu.
|
1
2
3
4
5
6
|
SELECT OBJECT_NAME(IX.object_id) as db_name, si.name, extent_page_id, allocated_page_page_id,
previous_page_page_id, next_page_page_id
FROM sys.dm_db_database_page_allocations(DB_ID(’AdventureWorks’), OBJECT_ID(’Sales.OrderTracking’),NULL, NULL, 'DETAILED’) IX
INNER JOIN sys.indexes si on IX.object_id = si.object_id AND IX.index_id = si.index_id
WHERE si.name = 'IX_OrderTracking_CarrierTrackingNumber’
ORDER BY allocated_page_page_id
|
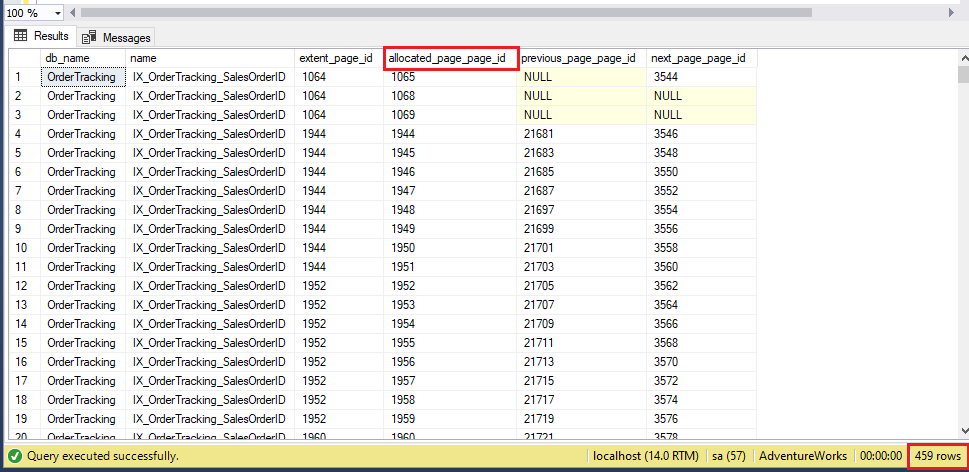
Tutaj, na powyższym obrazie wymienionych jest łącznie 459 stron, a pierwsze pięć stron to 1065, 1068, 1069, 1944 i 1945. Wykonajmy teraz polecenie REORGANIZE na indeksie za pomocą poniższej instrukcji T-SQL i ponownie przyjrzyjmy się alokacji stron.
|
1
|
ALTER INDEX IX_OrderTracking_SalesOrderID ON Sales.OrderTracking REORGANIZE
|
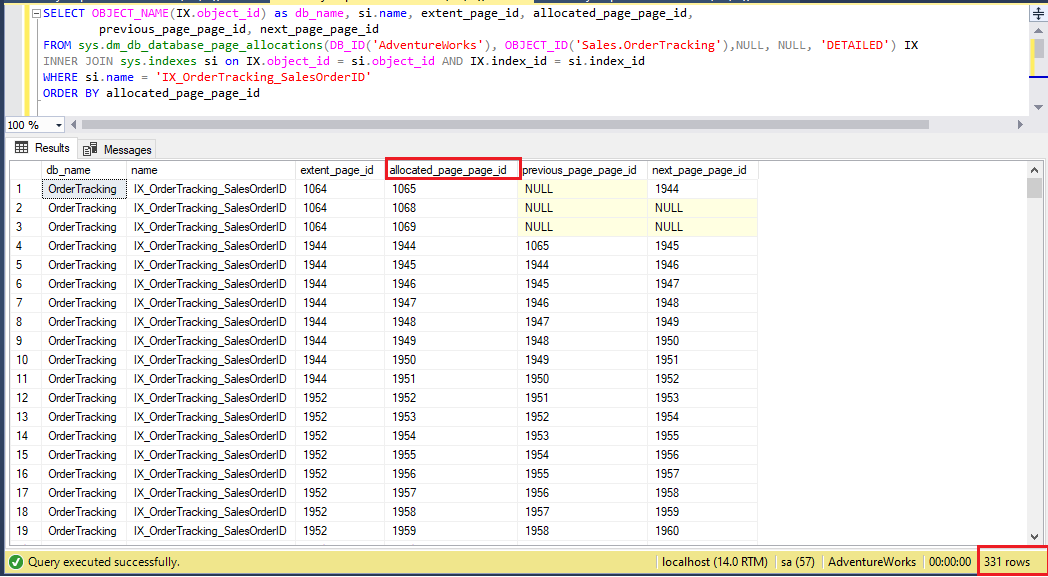
W tym miejscu całkowita liczba stron zmniejsza się do 331, która wcześniej wynosiła 459. Co więcej, nie widzimy nowych stron na liście pierwszych pięciu stron, co sugeruje, że dane są tylko restrukturyzowane – nie uzupełniane ponownie. Nawet można zobaczyć nowe strony, zdarza się to w sytuacji, gdy duży indeks jest mocno pofragmentowany, a przetasowanie danych powoduje użycie nowej strony.
Aby wykonać operację REORGANIZE indeksu na wszystkich indeksach tabeli lub bazy danych razem, użytkownik może użyć polecenia DBCC INDEXDEFRAG():
|
1
|
DBCC INDEXDEFRAG(’DatabaseName’, 'TableName’);
|
Jak widać, istnieje istotna różnica między REBUILD indeksów a REORGANIZE. Tutaj użytkownicy mają możliwość wyboru jednej z alternatyw w zależności od procentowej fragmentacji indeksu. Możemy zrozumieć, że nie ma udokumentowanych standardów; jednak administrator bazy danych stosuje standardowe równanie zgodnie z wymaganiami rozmiaru indeksu i typu informacji.
Zwykłe określenie użycia równania :
- Kiedy procent fragmentacji jest pomiędzy 15-30: REORGANIZE
- Gdy Fragmentacja jest większa niż 30: REBUILD
Opcja REBUILD jest bardziej przydatna z opcją ONLINE, gdy baza danych nie jest dostępna do podjęcia konserwacji indeksu w godzinach poza szczytem.
Wnioski
Fragmentacja indeksu to wewnętrzna fragmentacja w pliku danych. Podstawowymi parametrami szybkiej wydajności bazy danych są: architektura bazy danych, projekt bazy danych i pisanie zapytań. Dobry projekt indeksu wraz z jego utrzymaniem zawsze zwiększa wydajność zapytań w silniku bazy danych.
- Autor
- Recent Posts

View all posts by Jignesh Raiyani
- Page Life Expectancy (PLE) in SQL Server – July 17, 2020
- Jak zautomatyzować partycjonowanie tabel w SQL Server – 7 lipca, 2020
- Konfigurowanie SQL Server Always On Availability Groups na AWS EC2 – 6 lipca, 2020
.