Ostatnio dużo pracuję nad rzeczami związanymi z normą i nadszedł czas, aby o tym porozmawiać. W tym poście zamierzamy omówić całą rodzinę norm.
Co to jest norma?
Matematycznie norma to całkowity rozmiar lub długość wszystkich wektorów w przestrzeni wektorowej lub macierzy. Dla uproszczenia możemy powiedzieć, że im wyższa jest norma, tym większa jest (wartość w) macierzy lub wektorze. Norma może występować w wielu formach i wielu nazwach, w tym te popularne nazwy: odległość euklidesowa, średni błąd kwadratowy, itp.
Większość czasu zobaczysz norma pojawia się w równaniu, jak to:
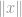 gdzie
gdzie  może być wektorem lub macierzą.
może być wektorem lub macierzą.
Na przykład norma euklidesowa wektora 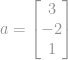 wynosi
wynosi 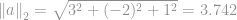 , co jest rozmiarem wektora
, co jest rozmiarem wektora 
Powyższy przykład pokazuje, jak obliczyć normę euklidesową, lub formalnie nazywaną normą 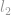 . Istnieje wiele innych typów norm, które wykraczają poza nasze wyjaśnienia tutaj, faktycznie dla każdej liczby rzeczywistej, istnieje norma jej odpowiadająca (Zauważ, że podkreślone słowo liczba rzeczywista, oznacza to, że nie ogranicza się tylko do liczb całkowitych.)
. Istnieje wiele innych typów norm, które wykraczają poza nasze wyjaśnienia tutaj, faktycznie dla każdej liczby rzeczywistej, istnieje norma jej odpowiadająca (Zauważ, że podkreślone słowo liczba rzeczywista, oznacza to, że nie ogranicza się tylko do liczb całkowitych.)
Formalnie norma  dla
dla  jest zdefiniowana jako:
jest zdefiniowana jako:
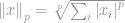 gdzie
gdzie 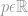
To wszystko! P-root sumy wszystkich elementów do p-tej potęgi jest tym, co nazywamy normą.
Ciekawy punkt jest taki, że nawet jeśli każda -norma jest bardzo podobna do siebie, ich właściwości matematyczne są bardzo różne, a zatem ich zastosowanie jest również dramatycznie różne. Poniżej zamierzamy przyjrzeć się niektórym z tych norm w szczegółach.
l0-norma
Pierwszą normą, którą zamierzamy omówić jest 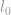 -norma. Z definicji, -norma z jest
-norma. Z definicji, -norma z jest
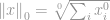
Ściśle mówiąc, -norma nie jest w rzeczywistości normą. Jest to funkcja kardynalności, która ma swoją definicję w postaci -normy, choć wiele osób nazywa ją normą. Jest to trochę trudne do pracy, ponieważ występuje w nim obecność zerowej mocy i zerowej korzeni. Oczywiście każdy 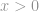 stanie się jednym z nich, ale problemy z definicją zerowej mocy, a zwłaszcza zerowej podstawy, powodują bałagan tutaj. Więc w rzeczywistości większość matematyków i inżynierów używa tej definicji -normy zamiast:
stanie się jednym z nich, ale problemy z definicją zerowej mocy, a zwłaszcza zerowej podstawy, powodują bałagan tutaj. Więc w rzeczywistości większość matematyków i inżynierów używa tej definicji -normy zamiast:
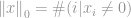
to całkowita liczba niezerowych elementów w wektorze.
Ponieważ jest to liczba niezerowego elementu, jest tak wiele aplikacji, które używają -normy. Ostatnio jest to jeszcze bardziej w centrum uwagi ze względu na wzrost Compressive Sensing schematu, który jest spróbować znaleźć najsłabsze rozwiązanie under-determined układu liniowego. Najskromniejsze rozwiązanie oznacza rozwiązanie, które ma najmniejszą liczbę niezerowych pozycji, czyli najmniejszą normę. Problem ten jest zwykle traktowany jako problem optymalizacji normy lub -optymalizacji.
l0-optymalizacja
W wielu aplikacjach, w tym Compressive Sensing, próbuje się zminimalizować normę wektora odpowiadającego pewnym ograniczeniom, stąd nazywa się to „-minimalizacją”. Standardowy problem minimalizacji jest sformułowany jako:
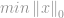 subject to
subject to 
Jednak wykonanie takiego zadania nie jest łatwe. Ze względu na brak matematycznej reprezentacji -normy, -minimalizacja jest uważana przez informatyków za problem NP-hard, co po prostu mówi, że jest to problem zbyt złożony i prawie niemożliwy do rozwiązania.
W wielu przypadkach problem -minimalizacji jest zrelaksowany do bycia problemem norm wyższego rzędu, takim jak 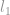 -minimalizacja i -minimalizacja.
-minimalizacja i -minimalizacja.
l1-norma
Podążając za definicją normy, -norma z jest zdefiniowana jako
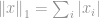
Ta norma jest dość powszechna wśród rodziny norm. Ma wiele nazw i wiele form wśród różnych dziedzin, a mianowicie Manhattan norm jest jej pseudonimem. Jeśli norma jest obliczana dla różnicy między dwoma wektorami lub macierzami, to jest
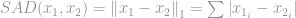
nazywana jest Sumą Różnicy Absolutnej (SAD) wśród naukowców zajmujących się widzeniem komputerowym.
W bardziej ogólnym przypadku pomiaru różnicy sygnałów, może być ona przeskalowana do wektora jednostkowego przez:
 gdzie
gdzie  jest wielkością .
jest wielkością .
która jest znana jako Mean-Absolute Error (MAE).
l2-norma
Najpopularniejszą ze wszystkich norm jest -norma. Jest ona stosowana w prawie każdej dziedzinie inżynierii i nauki jako całości. Po podstawowej definicji, -norma jest zdefiniowana jako
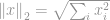
-norma jest dobrze znana jako norma euklidesowa, która jest używana jako standardowa wielkość do pomiaru różnicy wektorów. Podobnie jak w -normie, jeśli norma euklidesowa jest obliczana dla różnicy wektorów, jest ona znana jako odległość euklidesowa:
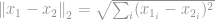
lub w postaci podniesionej do kwadratu, znanej jako suma różnicy kwadratowej (SSD) wśród naukowców zajmujących się widzeniem komputerowym:

Najbardziej znanym jego zastosowaniem w dziedzinie przetwarzania sygnałów jest pomiar błędu średniokwadratowego (MSE), który jest używany do obliczania podobieństwa, jakości lub korelacji między dwoma sygnałami. MSE jest
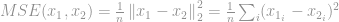
Jak wcześniej omówiono w sekcji -optymalizacja, z powodu wielu problemów zarówno z punktu widzenia obliczeniowego, jak i matematycznego, wiele problemów -optymalizacji rozluźnia się, aby zamiast tego stać się – i -optymalizacją. Z tego powodu omówimy teraz optymalizację .
l2-optymalizacja
Tak jak w przypadku -optymalizacji, problem minimalizacji -normy jest sformułowany przez
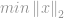 subject to
subject to
Zakładając, że macierz ograniczeń 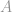 ma pełną rangę, problem ten jest teraz systemem underdertermined, który ma nieskończone rozwiązania. Celem w tym przypadku jest wyciągnięcie najlepszego rozwiązania, tj. mającego najniższą -normę, z tych nieskończenie wielu rozwiązań. Mogłoby to być bardzo żmudną pracą, gdyby miało być obliczane bezpośrednio. Na szczęście jest pewien matematyczny trik, który może nam bardzo pomóc w tej pracy.
ma pełną rangę, problem ten jest teraz systemem underdertermined, który ma nieskończone rozwiązania. Celem w tym przypadku jest wyciągnięcie najlepszego rozwiązania, tj. mającego najniższą -normę, z tych nieskończenie wielu rozwiązań. Mogłoby to być bardzo żmudną pracą, gdyby miało być obliczane bezpośrednio. Na szczęście jest pewien matematyczny trik, który może nam bardzo pomóc w tej pracy.
Używając triku z mnożnikami Lagrange’a, możemy wtedy zdefiniować Lagrangian

gdzie  jest wprowadzonym mnożnikiem Lagrange’a. Weźmy pochodną tego równania równą zero, aby znaleźć optymalne rozwiązanie i otrzymać
jest wprowadzonym mnożnikiem Lagrange’a. Weźmy pochodną tego równania równą zero, aby znaleźć optymalne rozwiązanie i otrzymać
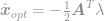
włączmy to rozwiązanie do ograniczenia, aby otrzymać
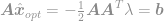
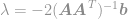
i w końcu
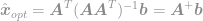
Korzystając z tego równania, możemy teraz natychmiast obliczyć optymalne rozwiązanie problemu optymalizacji . To równanie jest dobrze znane jako pseudoinwersja Moore’a-Penrose’a, a sam problem jest zwykle znany jako problem najmniejszej kwadratowości, regresja najmniejszej kwadratowości lub optymalizacja najmniejszej kwadratowości.
Jednakże, mimo że rozwiązanie metody najmniejszej kwadratowości jest łatwe do obliczenia, nie musi być najlepszym rozwiązaniem. Z powodu gładkiej natury -normy samej w sobie, trudno jest znaleźć jedno, najlepsze rozwiązanie dla problemu.

W przeciwieństwie do tego, -optymalizacja może zapewnić znacznie lepszy wynik niż to rozwiązanie.
l1-optymalizacja
Jak zwykle, problem -minimalizacji jest sformułowany jako
 subject to
subject to
Ponieważ natura -normy nie jest gładka jak w przypadku -normy, rozwiązanie tego problemu jest znacznie lepsze i bardziej unikalne niż -optymalizacja.

Jednakże, mimo że problem -minimalizacji ma prawie taką samą postać jak -minimalizacji, jest on znacznie trudniejszy do rozwiązania. Ponieważ problem ten nie ma funkcji gładkiej, sztuczka, której użyliśmy do rozwiązania -problemu, nie ma już racji bytu. Jedynym sposobem na znalezienie jego rozwiązania jest bezpośrednie szukanie. Poszukiwanie rozwiązania oznacza, że musimy obliczyć każde możliwe rozwiązanie, aby znaleźć najlepsze z puli „nieskończenie wielu” możliwych rozwiązań.
Ponieważ nie ma łatwego sposobu na matematyczne znalezienie rozwiązania tego problemu, użyteczność -optymalizacji jest bardzo ograniczona przez dziesięciolecia. Do niedawna postęp w dziedzinie komputerów o dużej mocy obliczeniowej pozwala na „przeczesanie” wszystkich rozwiązań. Dzięki zastosowaniu wielu pomocnych algorytmów, a mianowicie algorytmu optymalizacji wypukłej, takich jak programowanie liniowe, lub programowanie nieliniowe, itp. możliwe jest obecnie znalezienie najlepszego rozwiązania tego pytania. Wiele aplikacji, które opierają się na -optymalizacji, w tym Compressive Sensing, jest teraz możliwe.
W dzisiejszych czasach dostępnych jest wiele zestawów narzędzi do -optymalizacji. Te skrzynki narzędziowe zazwyczaj używają różnych podejść i/lub algorytmów do rozwiązania tego samego problemu. Przykładem takich narzędzi są l1-magic, SparseLab, ISAL1,
Teraz omówiliśmy wielu członków rodziny norm, począwszy od -normy, -normy i -normy. Nadszedł czas, aby przejść do następnego. Ponieważ na samym początku rozmawialiśmy o tym, że może istnieć dowolna l-wszelka norma zgodna z tą samą podstawową definicją normy, omówienie ich wszystkich zajmie sporo czasu. Na szczęście, poza -, – , i -norma, pozostałe są zwykle rzadkie i dlatego nie ma tak wielu ciekawych rzeczy do oglądania. Przyjrzymy się więc skrajnemu przypadkowi normy, którym jest 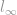 -norma (l-infinity norm).
-norma (l-infinity norm).
l-infinity norm
Jak zawsze, definicja dla -normy jest
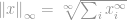
Teraz ta definicja znowu wygląda na podchwytliwą, ale w rzeczywistości jest całkiem prosta. Rozważmy wektor  , powiedzmy, że jeśli
, powiedzmy, że jeśli 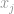 jest najwyższym wpisem w wektorze , przez własność samej nieskończoności, możemy powiedzieć, że
jest najwyższym wpisem w wektorze , przez własność samej nieskończoności, możemy powiedzieć, że
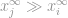

to
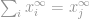
then
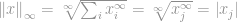
Teraz możemy po prostu powiedzieć, że -norma jest

czyli maksymalna wielkość wpisów tego wektora. To z pewnością zdemistyfikowało znaczenie -normy
Teraz omówiliśmy całą rodzinę norm od do , mam nadzieję, że ta dyskusja pomogłaby zrozumieć znaczenie normy, jej matematyczne właściwości i jej implikacje w świecie rzeczywistym.
Referencje i dalsza lektura:
Mathematical Norm – wikipedia
Mathematical Norm – MathWorld
Michael Elad – „Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing” , Springer, 2010.
Linear Programming – MathWorld
Compressive Sensing – Rice University
Edycja (15/02/15) : Poprawione nieścisłości w treści.