Wprowadzenie
Wraz ze zwiększonym zapotrzebowaniem na niezawodne i wydajne infrastruktury zaprojektowane do obsługi krytycznych systemów, terminy skalowalność i wysoka dostępność nie mogłyby być bardziej popularne. Podczas gdy obsługa zwiększonego obciążenia systemu jest powszechnym problemem, zmniejszanie czasu przestojów i eliminowanie pojedynczych punktów awarii są równie ważne. Wysoka dostępność to jakość projektowania infrastruktury w skali, która uwzględnia te ostatnie kwestie.
W tym przewodniku omówimy, co dokładnie oznacza wysoka dostępność i jak może ona poprawić niezawodność Twojej infrastruktury.
Co to jest wysoka dostępność?
W informatyce termin dostępność jest używany do opisania okresu czasu, w którym usługa jest dostępna, a także czasu wymaganego przez system do odpowiedzi na żądanie zgłoszone przez użytkownika. Wysoka dostępność jest jakością systemu lub komponentu, która zapewnia wysoki poziom wydajności operacyjnej w danym okresie czasu.
Mierzenie dostępności
Dostępność jest często wyrażana jako wartość procentowa wskazująca, ile czasu bezawaryjnej pracy jest oczekiwane od danego systemu lub komponentu w danym okresie czasu, gdzie wartość 100% wskazywałaby, że system nigdy nie zawiedzie. Na przykład system, który gwarantuje 99% dostępności w okresie jednego roku, może mieć do 3,65 dnia przestoju (1%).
Wartości te są obliczane na podstawie kilku czynników, w tym zarówno zaplanowanych, jak i niezaplanowanych okresów konserwacji, a także czasu na odzyskanie sprawności po ewentualnej awarii systemu.
Jak działa wysoka dostępność ?
Wysoka dostępność funkcjonuje jako mechanizm reagowania na awarie dla infrastruktury. Sposób, w jaki to działa, jest dość prosty koncepcyjnie, ale zazwyczaj wymaga pewnego specjalistycznego oprogramowania i konfiguracji.
Kiedy wysoka dostępność jest ważna ?
Przy tworzeniu solidnych systemów produkcyjnych minimalizacja przestojów i przerw w świadczeniu usług jest często wysokim priorytetem. Niezależnie od tego, jak niezawodne są systemy i oprogramowanie, mogą wystąpić problemy, które mogą spowodować awarię aplikacji lub serwerów.
Wdrożenie wysokiej dostępności infrastruktury jest użyteczną strategią zmniejszającą wpływ tego typu zdarzeń. Systemy o wysokiej dostępności mogą automatycznie odzyskiwać dane po awarii serwera lub komponentów.
Co sprawia, że system jest wysoce dostępny?
Jednym z celów wysokiej dostępności jest wyeliminowanie pojedynczych punktów awarii w infrastrukturze. Pojedynczy punkt awarii to komponent stosu technologicznego, który spowodowałby przerwę w świadczeniu usług, gdyby stał się niedostępny. W związku z tym, każdy komponent, który jest niezbędny do prawidłowego działania aplikacji, a nie posiada redundancji, jest uważany za pojedynczy punkt awarii.
Aby wyeliminować pojedyncze punkty awarii, każda warstwa stosu musi być przygotowana na redundancję. Na przykład, wyobraź sobie, że masz infrastrukturę składającą się z dwóch identycznych, redundantnych serwerów internetowych za load balancerem. Ruch przychodzący od klientów będzie równo rozdzielany między serwery WWW, ale jeśli jeden z serwerów ulegnie awarii, load balancer przekieruje cały ruch do pozostałego serwera online.
Warstwa serwera WWW w tym scenariuszu nie jest pojedynczym punktem awarii, ponieważ:
- występują redundantne komponenty do tego samego zadania
- mechanizm na szczycie tej warstwy (load balancer) jest w stanie wykryć awarie w komponentach i dostosować swoje zachowanie w celu odzyskania ruchu w odpowiednim czasie
Ale co się stanie, jeśli load balancer przejdzie w tryb offline?
W przypadku opisanego scenariusza, który nie jest rzadkością w prawdziwym życiu, warstwa równoważenia obciążenia sama w sobie pozostaje pojedynczym punktem awarii. Wyeliminowanie tego pozostałego pojedynczego punktu awarii może jednak stanowić wyzwanie; nawet jeśli można łatwo skonfigurować dodatkowy load balancer, aby osiągnąć redundancję, nie ma oczywistego punktu powyżej load balancerów, aby wdrożyć wykrywanie awarii i odzyskiwanie.
Sama redundancja nie może zagwarantować wysokiej dostępności. Musi istnieć mechanizm wykrywania awarii i podejmowania działań, gdy jeden z komponentów stosu staje się niedostępny.
Detekcja awarii i odzyskiwanie danych w systemach redundantnych mogą być realizowane przy użyciu podejścia „od góry do dołu”: warstwa na górze staje się odpowiedzialna za monitorowanie warstwy bezpośrednio pod nią pod kątem awarii. W naszym poprzednim scenariuszu przykładowym, load balancer jest warstwą górną. Jeśli jeden z serwerów WWW (warstwa dolna) stanie się niedostępny, load balancer przestanie przekierowywać żądania do tego konkretnego serwera.
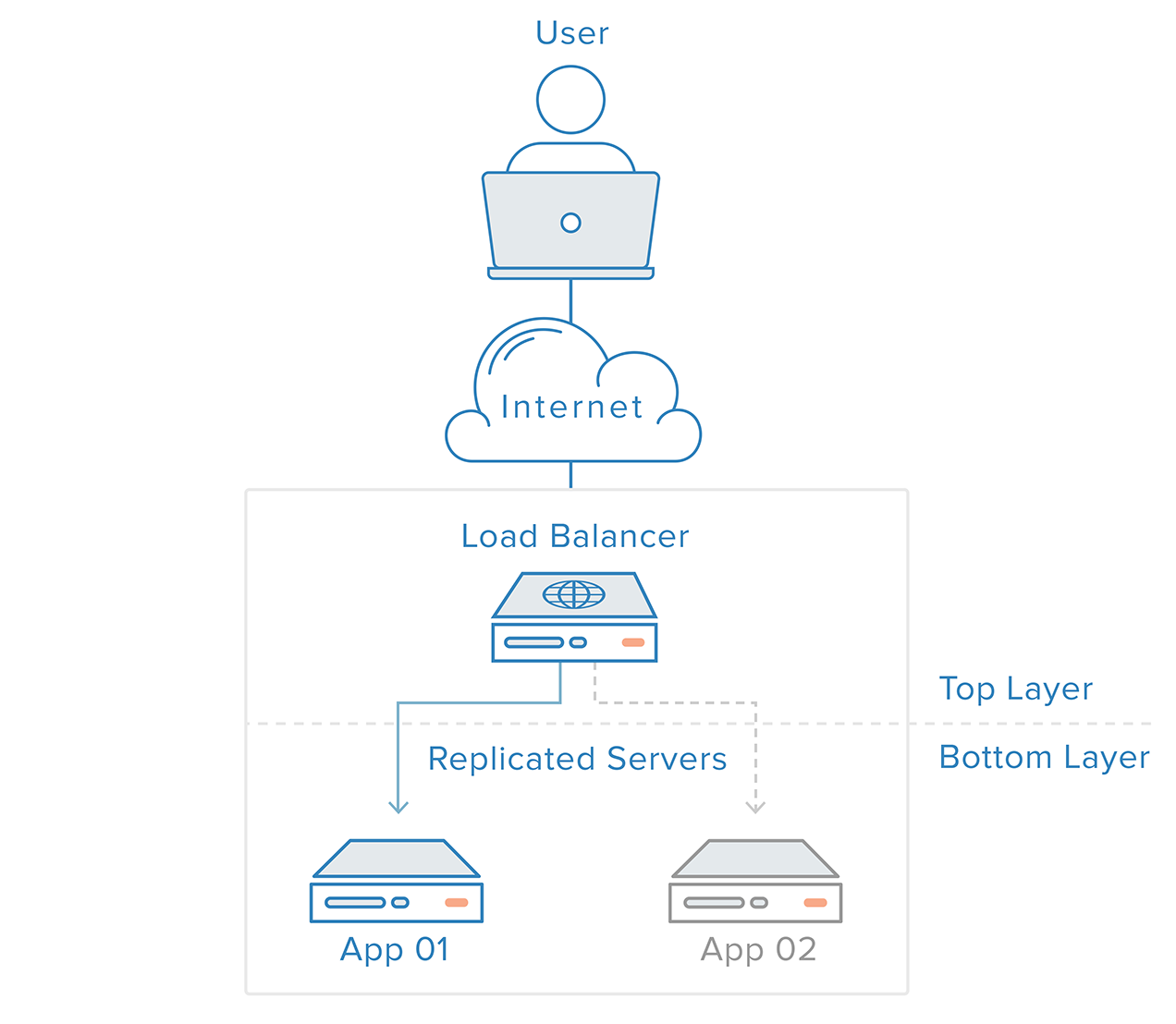
To podejście jest zwykle prostsze, ale ma ograniczenia: w twojej infrastrukturze będzie punkt, w którym górna warstwa albo nie istnieje, albo jest poza zasięgiem, co ma miejsce w przypadku warstwy load balancera. Tworzenie usługi wykrywania awarii dla load balancera w zewnętrznym serwerze po prostu stworzyłoby nowy pojedynczy punkt awarii.
W przypadku takiego scenariusza konieczne jest zastosowanie podejścia rozproszonego. Wiele redundantnych węzłów musi być połączonych razem jako klaster, gdzie każdy węzeł powinien być równie zdolny do wykrywania awarii i odzyskiwania.
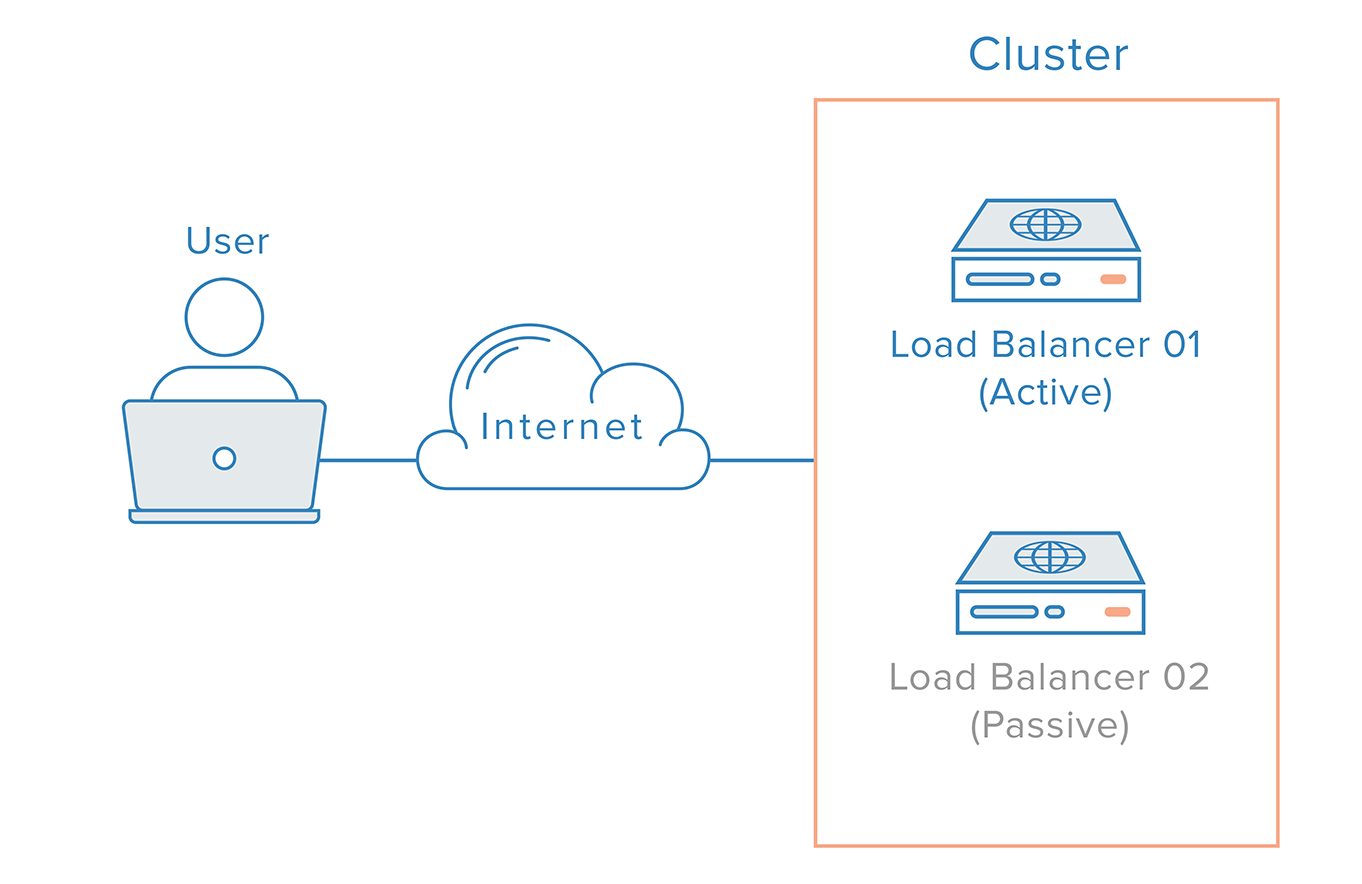
Dla przypadku load balancera istnieje jednak dodatkowa komplikacja, wynikająca ze sposobu działania serwerów nazw. Odzyskiwanie z awarii load balancera zazwyczaj oznacza failover do redundantnego load balancera, co oznacza, że zmiana DNS musi być dokonana w celu wskazania nazwy domeny na adres IP redundantnego load balancera. Zmiana taka może zająć znaczną ilość czasu, aby być propagowane w Internecie, co spowodowałoby poważne przestoje w tym systemie.
Możliwym rozwiązaniem jest użycie DNS round-robin load balancing. Jednak to podejście nie jest niezawodne, ponieważ pozostawia failover aplikacji po stronie klienta.
Bardziej solidnym i niezawodnym rozwiązaniem jest użycie systemów, które pozwalają na elastyczne przemapowanie adresów IP, takich jak pływające IP. Przemapowanie adresu IP na żądanie eliminuje problemy z propagacją i buforowaniem nieodłącznie związane ze zmianami DNS, zapewniając statyczny adres IP, który można łatwo przemapować w razie potrzeby. Nazwa domeny może pozostać powiązana z tym samym adresem IP, podczas gdy sam adres IP jest przenoszony między serwerami.
Tak wygląda wysoko dostępna infrastruktura wykorzystująca pływające adresy IP:

Jakie komponenty systemu są wymagane dla wysokiej dostępności?
Istnieje kilka komponentów, które muszą być dokładnie wzięte pod uwagę przy wdrażaniu wysokiej dostępności w praktyce. Znacznie bardziej niż implementacja oprogramowania, wysoka dostępność zależy od czynników takich jak:
- Środowisko: jeśli wszystkie serwery znajdują się w tym samym obszarze geograficznym, warunki środowiskowe, takie jak trzęsienie ziemi lub powódź, mogą spowodować awarię całego systemu. Posiadanie nadmiarowych serwerów w różnych centrach danych i obszarach geograficznych zwiększy niezawodność.
- Sprzęt: serwery o wysokiej dostępności powinny być odporne na przerwy w dostawie prądu i awarie sprzętu, w tym dysków twardych i interfejsów sieciowych.
- Oprogramowanie: cały stos oprogramowania, w tym system operacyjny i sama aplikacja, musi być przygotowany na obsługę nieoczekiwanych awarii, które potencjalnie mogą wymagać na przykład ponownego uruchomienia systemu.
- Dane: utrata danych i niespójność może być spowodowana wieloma czynnikami i nie ogranicza się do awarii dysków twardych. Systemy o wysokiej dostępności muszą uwzględniać bezpieczeństwo danych w przypadku awarii.
- Sieć: nieplanowane przerwy w działaniu sieci stanowią kolejny możliwy punkt awarii dla systemów o wysokiej dostępności. Ważne jest, aby istniała strategia sieci redundantnej na wypadek ewentualnych awarii.
Jakiego oprogramowania można użyć do skonfigurowania wysokiej dostępności?
Każda warstwa systemu o wysokiej dostępności będzie miała inne potrzeby w zakresie oprogramowania i konfiguracji. Jednak na poziomie aplikacji, load balancery stanowią niezbędny element oprogramowania do stworzenia dowolnej konfiguracji wysokiej dostępności.
HAProxy (High Availability Proxy) jest częstym wyborem do równoważenia obciążenia, ponieważ może obsługiwać równoważenie obciążenia na wielu warstwach i dla różnych rodzajów serwerów, w tym serwerów baz danych.
Przesuwając się w górę w stosie systemu, ważne jest, aby wdrożyć niezawodne rozwiązanie redundantne dla punktu wejścia aplikacji, zwykle load balancer. Aby usunąć ten pojedynczy punkt awarii, jak wspomniano wcześniej, musimy wdrożyć klaster load balancerów za Floating IP. Corosync i Pacemaker są popularnym wyborem do stworzenia takiej konfiguracji, zarówno na serwerach Ubuntu, jak i CentOS.
Podsumowanie
Wysoka dostępność jest ważnym podzbiorem inżynierii niezawodności, skoncentrowanym na zapewnieniu, że system lub komponent ma wysoki poziom wydajności operacyjnej w danym okresie czasu. Na pierwszy rzut oka jej wdrożenie może wydawać się dość skomplikowane, jednak może ona przynieść ogromne korzyści systemom, które wymagają zwiększonej niezawodności.
.