Introdução
Com uma maior procura de infra-estruturas fiáveis e performantes concebidas para servir sistemas críticos, os termos escalabilidade e alta disponibilidade não poderiam ser mais populares. Embora o aumento da carga do sistema seja uma preocupação comum, diminuir o tempo de inatividade e eliminar pontos únicos de falha são igualmente importantes. Alta disponibilidade é uma qualidade de projeto de infra-estrutura em escala que aborda estas últimas considerações.
Neste guia, discutiremos o que exatamente significa alta disponibilidade e como ela pode melhorar a confiabilidade de sua infra-estrutura.
O que é alta disponibilidade?
Na computação, o termo disponibilidade é usado para descrever o período de tempo em que um serviço está disponível, bem como o tempo necessário por um sistema para responder a uma solicitação feita por um usuário. Alta disponibilidade é uma qualidade de um sistema ou componente que assegura um alto nível de desempenho operacional por um determinado período de tempo.
Medir a disponibilidade
A disponibilidade é muitas vezes expressa como uma porcentagem indicando quanto tempo de atividade é esperado de um determinado sistema ou componente em um determinado período de tempo, onde um valor de 100% indicaria que o sistema nunca falha. Por exemplo, um sistema que garante 99% de disponibilidade num período de um ano pode ter até 3,65 dias de inactividade (1%).
Estes valores são calculados com base em vários factores, incluindo períodos de manutenção programados e não programados, bem como o tempo de recuperação de uma possível falha do sistema.
Como funciona a Alta Disponibilidade ?
A alta disponibilidade funciona como um mecanismo de resposta a falhas para a infra-estrutura. A forma como funciona é bastante simples conceptualmente, mas normalmente requer algum software especializado e configuração.
Quando é importante a Alta Disponibilidade ?
Quando se configura sistemas de produção robustos, a minimização do tempo de paragem e das interrupções de serviço é frequentemente uma alta prioridade. Independentemente da confiabilidade de seus sistemas e softwares, podem ocorrer problemas que podem derrubar suas aplicações ou seus servidores.
Implementar alta disponibilidade para sua infra-estrutura é uma estratégia útil para reduzir o impacto desses tipos de eventos. Sistemas altamente disponíveis podem se recuperar automaticamente de falhas de servidores ou componentes.
O que torna um sistema altamente disponível?
Um dos objetivos da alta disponibilidade é eliminar pontos únicos de falha em sua infra-estrutura. Um único ponto de falha é um componente da sua pilha de tecnologia que causaria uma interrupção do serviço se ele se tornasse indisponível. Como tal, qualquer componente que seja um requisito para a funcionalidade adequada da sua aplicação que não tenha redundância é considerado como um único ponto de falha.
Para eliminar pontos únicos de falha, cada camada da sua pilha deve estar preparada para redundância. Por exemplo, imagine que você tenha uma infra-estrutura composta por dois servidores web idênticos e redundantes atrás de um balanceador de carga. O tráfego vindo dos clientes será igualmente distribuído entre os servidores web, mas se um dos servidores cair, o balanceador de carga redirecionará todo o tráfego para o servidor online restante.
A camada do servidor web neste cenário não é um único ponto de falha porque:
- componentes redundantes para a mesma tarefa estão no lugar
- o mecanismo no topo desta camada (o balanceador de carga) é capaz de detectar falhas nos componentes e adaptar seu comportamento para uma recuperação oportuna
Mas o que acontece se o balanceador de carga ficar offline?
Com o cenário descrito, que não é raro na vida real, a camada de balanceamento de carga em si permanece um único ponto de falha. Eliminar este ponto único de falha restante, entretanto, pode ser um desafio; mesmo que você possa facilmente configurar um balanceador de carga adicional para obter redundância, não há um ponto óbvio acima dos balanceadores de carga para implementar a detecção e recuperação de falhas.
Redundância por si só não pode garantir alta disponibilidade. Um mecanismo deve estar instalado para detectar falhas e agir quando um dos componentes da sua pilha se torna indisponível.
Detecção e recuperação de falhas para sistemas redundantes pode ser implementado usando uma abordagem de cima para baixo: a camada superior torna-se responsável por monitorar a camada imediatamente abaixo dela para detectar falhas. No nosso cenário de exemplo anterior, o balanceador de carga é a camada superior. Se um dos servidores web (camada inferior) ficar indisponível, o balanceador de carga deixará de redirecionar as solicitações para aquele servidor específico.
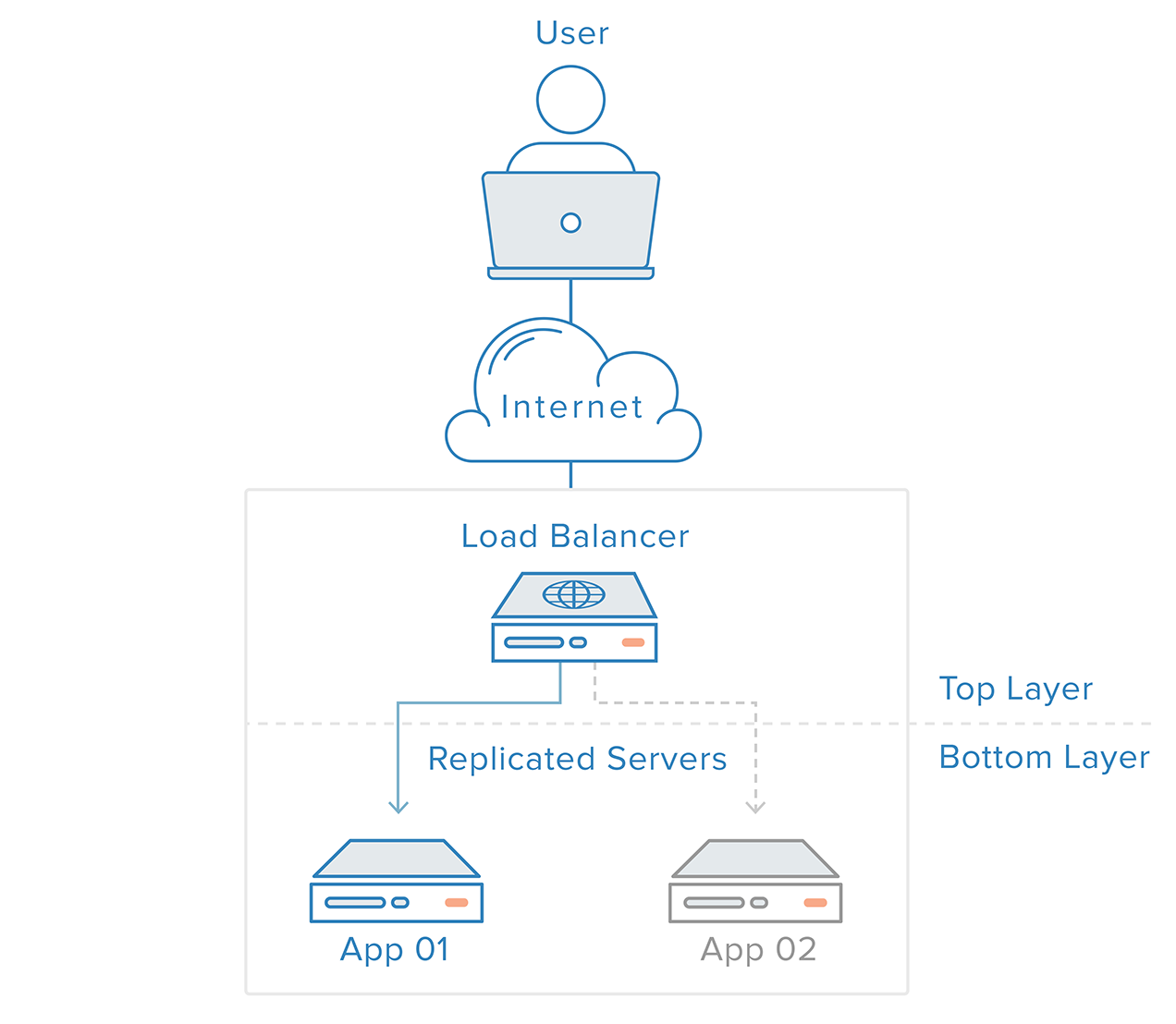
Esta abordagem tende a ser mais simples, mas tem limitações: haverá um ponto em sua infra-estrutura onde uma camada superior ou não existe ou está fora de alcance, que é o caso da camada de balanceamento de carga. Criar um serviço de detecção de falhas para o balanceador de carga em um servidor externo simplesmente criaria um novo ponto único de falha.
Com tal cenário, uma abordagem distribuída é necessária. Vários nós redundantes devem ser conectados juntos como um cluster onde cada nó deve ser igualmente capaz de detecção e recuperação de falhas.
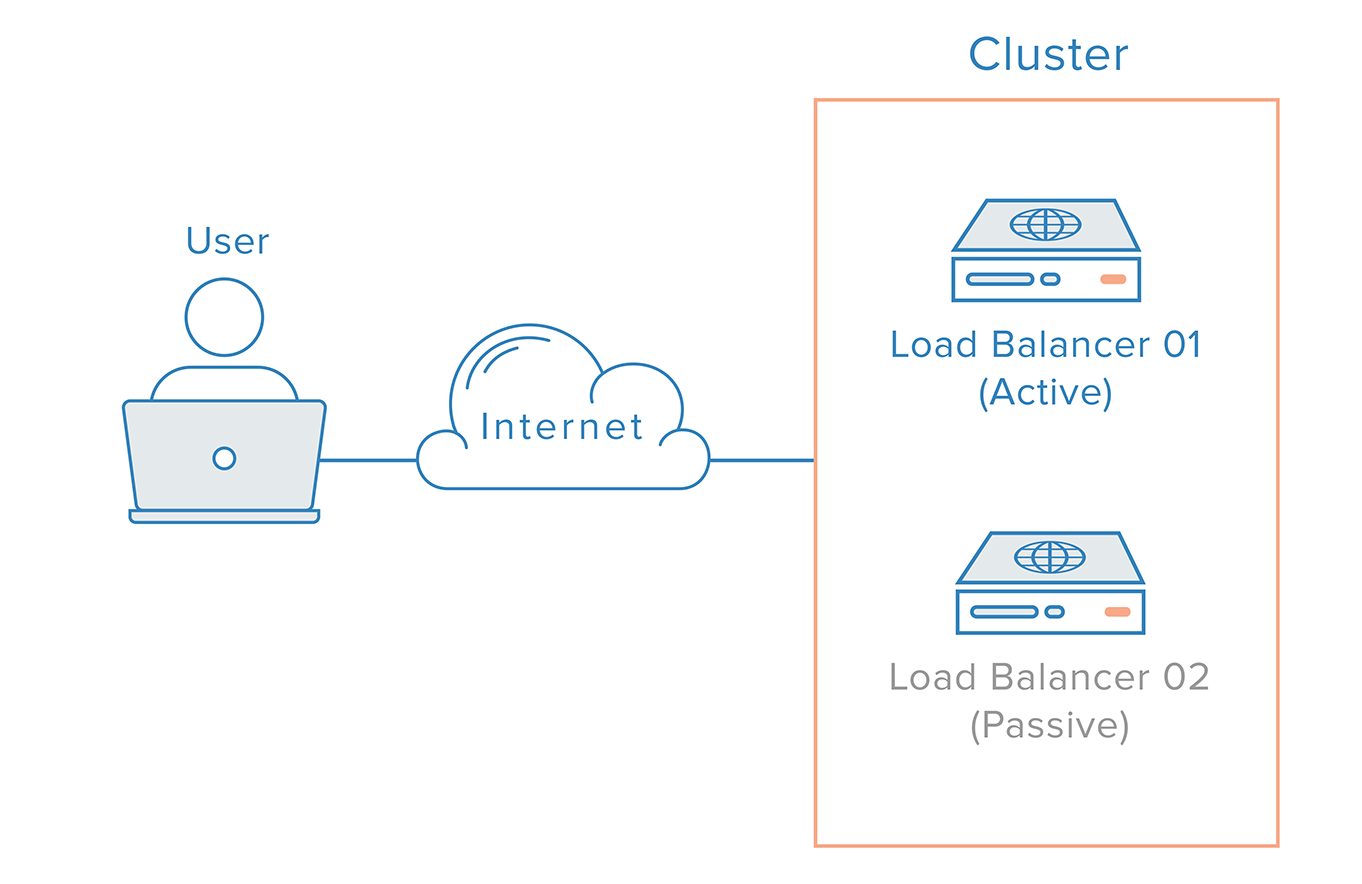
Para o caso do balanceador de carga, no entanto, há uma complicação adicional, devido à forma como os nameservers funcionam. Recuperar de uma falha do balanceador de carga significa tipicamente uma falha para um balanceador de carga redundante, o que implica que uma mudança de DNS deve ser feita para apontar um nome de domínio para o endereço IP do balanceador de carga redundante. Uma mudança como esta pode levar um tempo considerável para ser propagada na Internet, o que causaria uma séria parada neste sistema.
Uma solução possível é usar o balanceamento de carga de round-robin DNS. No entanto, esta abordagem não é confiável, pois deixa a aplicação do lado do cliente com falhas.
Uma solução mais robusta e confiável é usar sistemas que permitam o remapeamento flexível de endereços IP, tais como IPs flutuantes. O remapeamento de endereços IP sob demanda elimina os problemas de propagação e cache inerentes às mudanças de DNS, fornecendo um endereço IP estático que pode ser facilmente remapeado quando necessário. O nome de domínio pode permanecer associado ao mesmo endereço IP, enquanto o próprio endereço IP é movido entre servidores.
Esta é a aparência de uma infra-estrutura altamente disponível usando IPs flutuantes:

Quais os componentes do sistema são necessários para alta disponibilidade?
Existem vários componentes que devem ser cuidadosamente levados em consideração para implementar alta disponibilidade na prática. Muito mais do que uma implementação de software, a alta disponibilidade depende de fatores como:
- Ambiente: se todos os seus servidores estiverem localizados na mesma área geográfica, uma condição ambiental como um terremoto ou uma inundação pode derrubar todo o seu sistema. Ter servidores redundantes em diferentes datacenters e áreas geográficas aumentará a confiabilidade.
- Hardware: servidores altamente disponíveis devem ser resistentes a quedas de energia e falhas de hardware, incluindo discos rígidos e interfaces de rede.
- Software: toda a pilha de software, incluindo o sistema operacional e a própria aplicação, deve estar preparada para lidar com falhas inesperadas que possam potencialmente requerer uma reinicialização do sistema, por exemplo.
- Dados: a perda e inconsistência de dados pode ser causada por vários fatores, e não está restrita a falhas no disco rígido. Sistemas altamente disponíveis devem ser responsáveis pela segurança dos dados no caso de uma falha.
- Rede: interrupções não planejadas na rede representam outro possível ponto de falha para sistemas altamente disponíveis. É importante que exista uma estratégia de rede redundante para possíveis falhas.
Que software pode ser usado para configurar a alta disponibilidade?
Cada camada de um sistema altamente disponível terá necessidades diferentes em termos de software e configuração. No entanto, ao nível da aplicação, os balanceadores de carga representam uma peça essencial de software para criar qualquer configuração de alta disponibilidade.
HAProxy (High Availability Proxy) é uma escolha comum para balanceamento de carga, pois pode lidar com balanceamento de carga em múltiplas camadas, e para diferentes tipos de servidores, incluindo servidores de banco de dados.
Movendo-se na pilha do sistema, é importante implementar uma solução redundante confiável para o ponto de entrada de sua aplicação, normalmente o balanceador de carga. Para remover este ponto único de falha, como mencionado anteriormente, precisamos implementar um cluster de balanceadores de carga atrás de um IP flutuante. Corosync e Pacemaker são escolhas populares para criar tal configuração, tanto em servidores Ubuntu como CentOS.
Conclusion
Alta disponibilidade é um subconjunto importante de engenharia de confiabilidade, focado em garantir que um sistema ou componente tenha um alto nível de desempenho operacional em um determinado período de tempo. À primeira vista, sua implementação pode parecer bastante complexa; entretanto, pode trazer enormes benefícios para sistemas que requerem maior confiabilidade.