Inleiding
Met een toenemende vraag naar betrouwbare en krachtige infrastructuren voor kritieke systemen, zijn de termen schaalbaarheid en hoge beschikbaarheid erg in trek. Hoewel het omgaan met een verhoogde systeembelasting een veelgehoorde zorg is, zijn het verminderen van downtime en het elimineren van single points of failure net zo belangrijk. Hoge beschikbaarheid is een kwaliteit van infrastructuurontwerp op schaal die deze laatste overwegingen aanpakt.
In deze gids bespreken we wat hoge beschikbaarheid precies inhoudt en hoe het de betrouwbaarheid van uw infrastructuur kan verbeteren.
Wat is hoge beschikbaarheid?
In de informatica wordt de term beschikbaarheid gebruikt om de tijdsperiode te beschrijven waarin een service beschikbaar is, evenals de tijd die een systeem nodig heeft om op een verzoek van een gebruiker te reageren. Hoge beschikbaarheid is een kwaliteit van een systeem of component die een hoog niveau van operationele prestaties gedurende een bepaalde periode garandeert.
Beschikbaarheid meten
Beschikbaarheid wordt vaak uitgedrukt als een percentage dat aangeeft hoeveel uptime van een bepaald systeem of component in een bepaalde periode wordt verwacht, waarbij een waarde van 100% zou betekenen dat het systeem nooit uitvalt. Zo kan een systeem dat 99% beschikbaarheid garandeert in een periode van een jaar tot 3,65 dagen downtime hebben (1%).
Deze waarden worden berekend op basis van verschillende factoren, waaronder zowel geplande als ongeplande onderhoudsperioden, evenals de tijd om te herstellen van een mogelijke systeemstoring.
Hoe werkt hoge beschikbaarheid ?
Hoge beschikbaarheid functioneert als een storingsreactiemechanisme voor infrastructuur. De manier waarop het werkt is conceptueel vrij eenvoudig, maar vereist doorgaans enige gespecialiseerde software en configuratie.
Wanneer is hoge beschikbaarheid belangrijk ?
Bij het opzetten van robuuste productiesystemen is het minimaliseren van downtime en service-onderbrekingen vaak een hoge prioriteit. Hoe betrouwbaar uw systemen en software ook zijn, er kunnen zich problemen voordoen die uw toepassingen of servers platleggen.
Hoge beschikbaarheid voor uw infrastructuur implementeren is een nuttige strategie om de impact van dit soort gebeurtenissen te beperken. Systemen met een hoge beschikbaarheid kunnen zich automatisch herstellen van server- of componentstoringen.
Wat maakt een systeem hoogbeschikbaar?
Eén van de doelstellingen van hoge beschikbaarheid is het elimineren van single points of failure in uw infrastructuur. Een single point of failure is een onderdeel van uw technologiestack dat een serviceonderbreking zou veroorzaken als het niet beschikbaar zou zijn. Als zodanig wordt elke component die nodig is voor de goede werking van uw toepassing en geen redundantie heeft, beschouwd als een single point of failure.
Om single points of failure te elimineren, moet elke laag van uw stack voorbereid zijn op redundantie. Stel bijvoorbeeld dat u een infrastructuur hebt die bestaat uit twee identieke, redundante webservers achter een load balancer. Het verkeer van klanten wordt gelijkelijk verdeeld over de webservers, maar als een van de servers uitvalt, leidt de load balancer al het verkeer om naar de overgebleven online server.
De webserverlaag in dit scenario is geen single point of failure omdat:
- redundante componenten voor dezelfde taak aanwezig zijn
- het mechanisme bovenop deze laag (de load balancer) in staat is om storingen in de componenten te detecteren en zijn gedrag aan te passen voor een tijdig herstel
Maar wat gebeurt er als de load balancer offline gaat?
In het beschreven scenario, dat in het echte leven niet ongebruikelijk is, blijft de load balancing laag zelf een single point of failure. Het elimineren van dit resterende single point of failure kan echter een uitdaging zijn; ook al kunt u eenvoudig een extra load balancer configureren om redundantie te bereiken, er is geen voor de hand liggend punt boven de load balancers om faaldetectie en herstel te implementeren.
Redundantie alleen kan geen hoge beschikbaarheid garanderen. Er moet een mechanisme zijn om storingen te detecteren en actie te ondernemen wanneer een van de componenten van uw stack niet meer beschikbaar is.
Failure detection and recovery voor redundante systemen kan worden geïmplementeerd met behulp van een top-to-bottom-benadering: de laag bovenaan wordt verantwoordelijk voor het monitoren van de laag direct eronder op storingen. In ons vorig voorbeeldscenario is de load balancer de bovenste laag. Als een van de webservers (onderste laag) onbeschikbaar wordt, stopt de load balancer met het doorsturen van verzoeken naar die specifieke server.
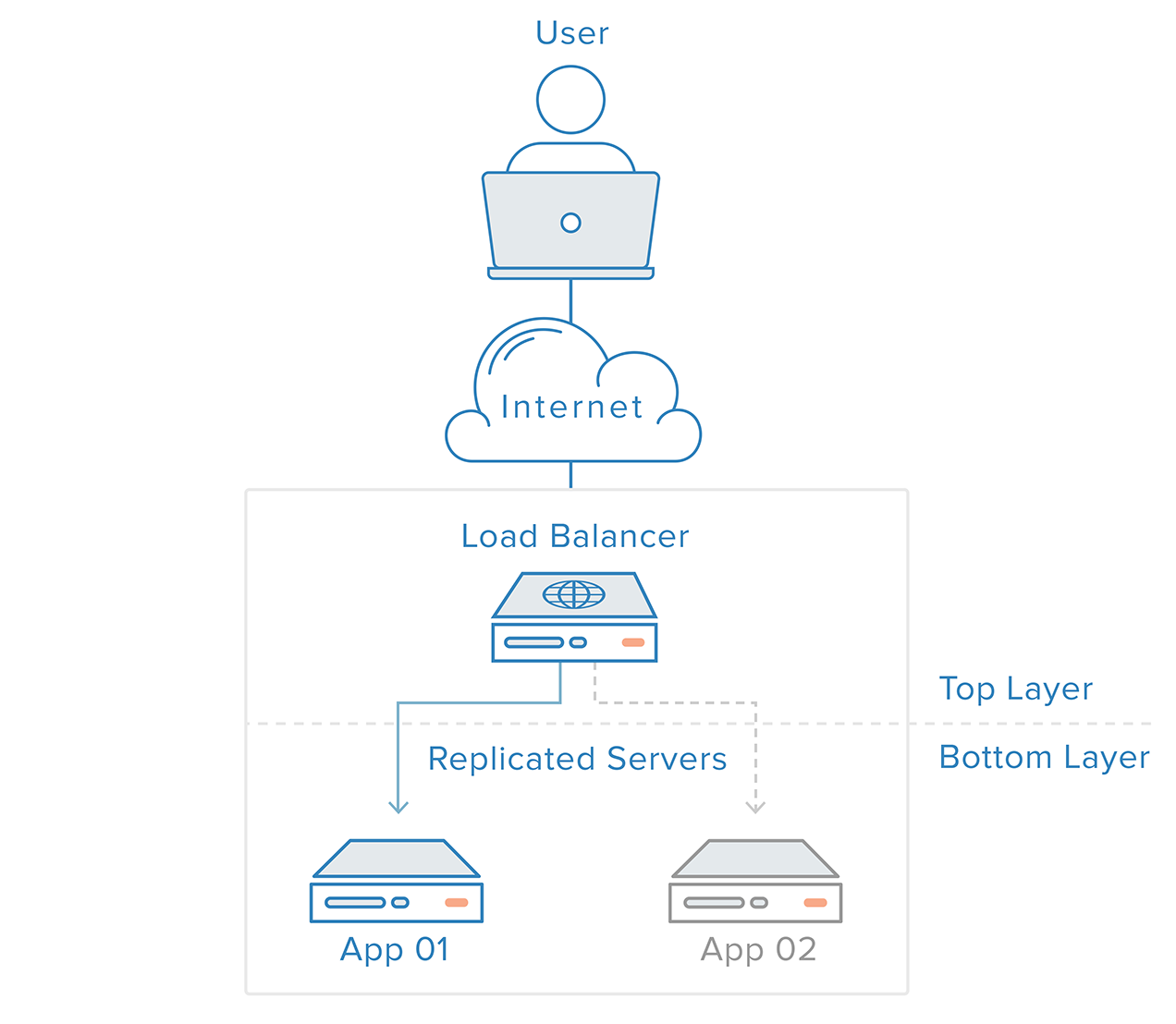
Deze aanpak is meestal eenvoudiger, maar heeft beperkingen: er komt een punt in uw infrastructuur waarop een toplaag ofwel niet meer bestaat of buiten bereik is, wat het geval is met de loadbalancer-laag. Het maken van een foutdetectiedienst voor de load balancer in een externe server zou gewoon een nieuw single point of failure creëren.
Bij een dergelijk scenario is een gedistribueerde aanpak noodzakelijk. Meerdere redundante knooppunten moeten met elkaar worden verbonden als een cluster, waarbij elk knooppunt even goed in staat moet zijn om storingen op te sporen en te herstellen.
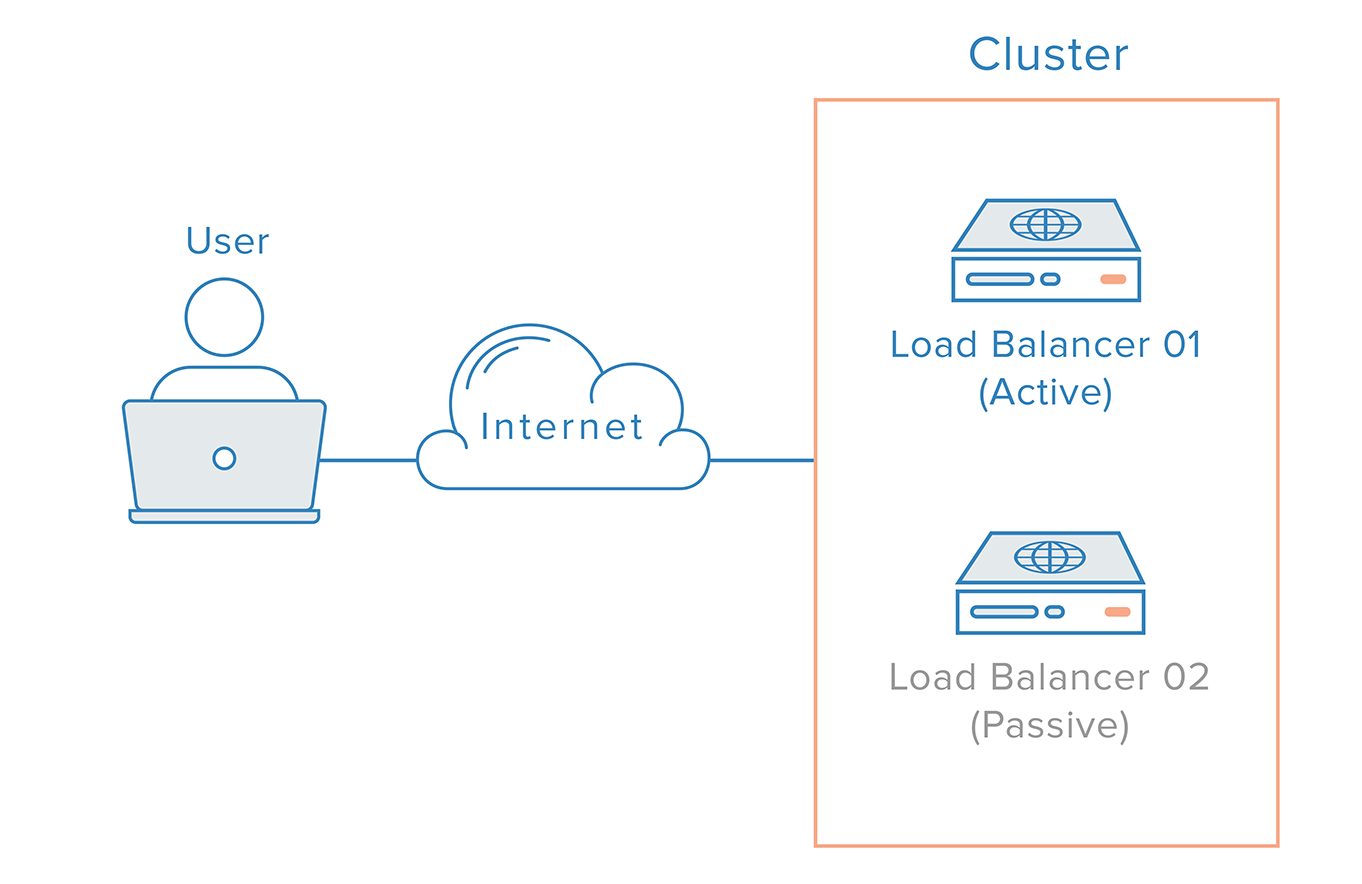
In het geval van een loadbalancer is er echter nog een extra complicatie, vanwege de manier waarop nameservers werken. Herstellen van een storing in een loadbalancer betekent meestal een failover naar een redundante loadbalancer, wat inhoudt dat een DNS-wijziging moet worden doorgevoerd om een domeinnaam naar het IP-adres van de redundante loadbalancer te verwijzen. Een dergelijke wijziging kan een aanzienlijke hoeveelheid tijd vergen om op het internet te worden verspreid, wat een ernstige downtime van dit systeem zou veroorzaken.
Een mogelijke oplossing is het gebruik van DNS round-robin load balancing. Deze aanpak is echter niet betrouwbaar, omdat het failover overlaten aan de client-side applicatie.
Een meer robuuste en betrouwbare oplossing is het gebruik van systemen die flexibele IP-adres remapping mogelijk maken, zoals floating IPs. Het op verzoek opnieuw toewijzen van IP-adressen elimineert de propagatie- en cachingproblemen die inherent zijn aan DNS-wijzigingen door een statisch IP-adres te bieden dat gemakkelijk opnieuw kan worden toegewezen wanneer dat nodig is. De domeinnaam kan aan hetzelfde IP-adres gekoppeld blijven, terwijl het IP-adres zelf tussen servers wordt verplaatst.
Zo ziet een infrastructuur met hoge beschikbaarheid die gebruikmaakt van Floating IP’s eruit:

Welke systeemcomponenten zijn nodig voor hoge beschikbaarheid?
Er zijn verschillende componenten die zorgvuldig in aanmerking moeten worden genomen om hoge beschikbaarheid in de praktijk te implementeren. Veel meer dan een software-implementatie, hangt hoge beschikbaarheid af van factoren zoals:
- Omgeving: als al uw servers zich in hetzelfde geografische gebied bevinden, kan een omgevingsomstandigheid zoals een aardbeving of overstroming uw hele systeem platleggen. Het hebben van redundante servers in verschillende datacenters en geografische gebieden zal de betrouwbaarheid verhogen.
- Hardware: hoog beschikbare servers moeten bestand zijn tegen stroomuitval en hardwarestoringen, met inbegrip van harde schijven en netwerkinterfaces.
- Software: de hele softwarestack, met inbegrip van het besturingssysteem en de applicatie zelf, moet voorbereid zijn op het omgaan met onverwachte storingen die mogelijk een herstart van het systeem vereisen, bijvoorbeeld.
- Gegevens: verlies en inconsistentie van gegevens kunnen door verschillende factoren worden veroorzaakt, en niet alleen door defecten aan de harde schijf. Bij systemen met hoge beschikbaarheid moet rekening worden gehouden met de veiligheid van gegevens in geval van een storing.
- Netwerk: ongeplande netwerkstoringen vormen een ander mogelijk punt van falen voor systemen met hoge beschikbaarheid. Het is belangrijk dat er een redundante netwerkstrategie is voor mogelijke storingen.
Welke software kan worden gebruikt om hoge beschikbaarheid te configureren?
Elke laag van een systeem met hoge beschikbaarheid heeft andere behoeften op het gebied van software en configuratie. Op applicatieniveau zijn load balancers echter een essentieel onderdeel van de software voor het creëren van een hoge beschikbaarheid.
HAProxy (High Availability Proxy) is een veelgebruikte keuze voor load balancing, omdat het kan omgaan met load balancing op meerdere lagen, en voor verschillende soorten servers, waaronder database servers.
Opschuivend in de systeem stack, is het belangrijk om een betrouwbare redundante oplossing te implementeren voor uw applicatie entry point, normaal gesproken de load balancer. Om dit single point of failure te verwijderen, zoals eerder vermeld, moeten we een cluster van load balancers implementeren achter een Floating IP. Corosync en Pacemaker zijn populaire keuzes voor het maken van zo’n setup, op zowel Ubuntu als CentOS servers.
Conclusie
Hoge beschikbaarheid is een belangrijke subset van reliability engineering, gericht op het verzekeren dat een systeem of component een hoog niveau van operationele prestaties heeft in een bepaalde periode. Op het eerste gezicht kan de implementatie ervan vrij complex lijken; het kan echter enorme voordelen opleveren voor systemen die een hogere betrouwbaarheid vereisen.