Ik ben de laatste tijd veel bezig met dingen die met norm te maken hebben en het is tijd om het er eens over te hebben. In dit bericht gaan we het hebben over een hele familie van norm.
Wat is een norm?
Mathematisch gezien is een norm de totale grootte of lengte van alle vectoren in een vectorruimte of matrices. Voor het gemak kunnen we zeggen dat hoe hoger de norm is, hoe groter de (waarde in) matrix of vector is. Norm kan komen in vele vormen en vele namen, met inbegrip van deze populaire naam: Euclidische afstand, Mean-squared Error, enz.
Meestal zul je zien de norm verschijnt in een vergelijking als deze:
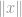 waar
waar  kan een vector of een matrix zijn.
kan een vector of een matrix zijn.
Voorbeeld, een Euclidische norm van een vector 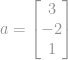 is
is 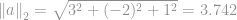 wat de grootte is van vector
wat de grootte is van vector 
Het bovenstaande voorbeeld laat zien hoe een Euclidische norm, of formeel een 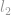 -norm genoemd, berekend kan worden. Er zijn vele andere soorten normen die onze uitleg hier te boven gaan, in feite is er voor elk reëel getal een norm die ermee overeenkomt (let op het benadrukte woord reëel getal, dat betekent dat het niet beperkt is tot alleen gehele getallen.)
-norm genoemd, berekend kan worden. Er zijn vele andere soorten normen die onze uitleg hier te boven gaan, in feite is er voor elk reëel getal een norm die ermee overeenkomt (let op het benadrukte woord reëel getal, dat betekent dat het niet beperkt is tot alleen gehele getallen.)
Formaal is de  -norm van
-norm van  gedefinieerd als:
gedefinieerd als:
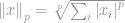 waarbij
waarbij 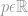
Dat is het! Een p-de-wortel van een sommatie van alle elementen tot de p-de macht is wat we een norm noemen.
Het interessante punt is dat, ook al lijken alle -normen erg op elkaar, hun wiskundige eigenschappen zeer verschillend zijn en dus hun toepassing ook dramatisch verschillend. We gaan nu een aantal van deze normen in detail bekijken.
l0-norm
De eerste norm die we gaan bespreken is een 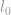 -norm. Per definitie is -norm van
-norm. Per definitie is -norm van
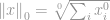
Strikt genomen is -norm niet echt een norm. Het is een cardinaliteitsfunctie die zijn definitie heeft in de vorm van -norm, hoewel veel mensen het een norm noemen. Het is een beetje lastig om ermee te werken omdat er een nulmacht en een nulwortel in voorkomen. Uiteraard zal elke 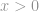 er een worden, maar de definitieproblemen van de nulde macht en vooral van de nulde wortel brengen hier de zaak in de war. Dus in werkelijkheid gebruiken de meeste wiskundigen en ingenieurs in plaats daarvan deze definitie van -norm:
er een worden, maar de definitieproblemen van de nulde macht en vooral van de nulde wortel brengen hier de zaak in de war. Dus in werkelijkheid gebruiken de meeste wiskundigen en ingenieurs in plaats daarvan deze definitie van -norm:
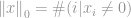
dat is het totale aantal niet-nul elementen in een vector.
Omdat het een aantal niet-nul elementen is, zijn er zo veel toepassingen die -norm gebruiken. De laatste tijd is het nog meer in de belangstelling door de opkomst van de Compressive Sensing regeling, die probeert te vinden van de spaarzaamste oplossing van de onder-bepaalde lineaire systeem. De spaarzaamste oplossing is de oplossing met de minste niet-nul-ingangen, d.w.z. de laagste -norm. Dit probleem wordt gewoonlijk beschouwd als een optimalisatieprobleem van -norm of -optimalisatie.
l0-optimalisatie
Veel toepassingen, waaronder Compressive Sensing, proberen de -norm van een vector te minimaliseren die overeenkomt met bepaalde beperkingen, vandaar de naam “-minimalisatie”. Een standaardminimalisatieprobleem wordt geformuleerd als:
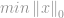 onderworpen aan
onderworpen aan 
Het is echter geen gemakkelijke opgave om dit te doen. Door het ontbreken van een wiskundige voorstelling van -norm wordt -minimalisatie door computerwetenschappers beschouwd als een NP-hard probleem, wat eenvoudigweg betekent dat het te complex en bijna onmogelijk op te lossen is.
In veel gevallen wordt -minimalisatie probleem ontspannen tot hogere-orde norm probleem, zoals 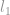 -minimalisatie en -minimalisatie.
-minimalisatie en -minimalisatie.
l1-norm
Naar aanleiding van de definitie van norm, -norm van wordt gedefinieerd als
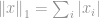
Deze norm is heel gebruikelijk onder de norm familie. Hij heeft vele namen en vele vormen op verschillende gebieden, namelijk Manhattan norm is zijn bijnaam. Als de -norm wordt berekend voor een verschil tussen twee vectoren of matrices, dat is
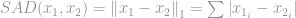
wordt hij onder computervisiewetenschappers Sum of Absolute Difference (SAD) genoemd.
In een algemener geval van signaalverschilmeting kan het worden geschaald naar een eenheidsvector door:
 waarbij
waarbij  een grootte heeft van .
een grootte heeft van .
die bekend staat als Mean-Absolute Error (MAE).
l2-norm
De meest populaire van alle normen is de -norm. Hij wordt in bijna alle sectoren van de techniek en de wetenschap als geheel gebruikt. Volgens de basisdefinitie wordt de -norm gedefinieerd als
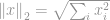
-norm is bekend als een Euclidische norm, die wordt gebruikt als een standaardgrootheid voor het meten van een vectorverschil. Net als bij de -norm staat de Euclidische norm, wanneer deze voor een vectorverschil wordt berekend, bekend als een Euclidische afstand:
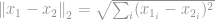
of in zijn gekwadrateerde vorm, onder computervisitiewetenschappers bekend als een Som van Kwadraat Verschil (SSD):

De bekendste toepassing op het gebied van signaalverwerking is de meting van de Mean-Squared Error (MSE), die wordt gebruikt om een overeenkomst, een kwaliteit of een correlatie tussen twee signalen te berekenen. MSE is
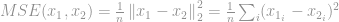
Zoals eerder besproken in -optimalisatie, vanwege vele problemen vanuit zowel computationeel als wiskundig oogpunt, versoepelen veel -optimalisatieproblemen zich tot – en -optimalisatie. Daarom zullen we het nu hebben over de optimalisatie van .
l2-optimalisatie
Zoals in het geval van -optimalisatie wordt het probleem van de minimalisatie van -norm geformuleerd door
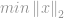 onder
onder
Aannemelijk dat de constraintmatrix 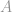 volledige rang heeft, is dit probleem nu een ondergedetermineerd systeem dat oneindig veel oplossingen heeft. Het doel in dit geval is om de beste oplossing, d.w.z. met de laagste -norm, uit deze oneindig vele oplossingen te halen. Dit zou een zeer vervelend werk kunnen zijn als het rechtstreeks berekend zou moeten worden. Gelukkig is er een wiskundige truc die ons bij dit werk veel kan helpen.
volledige rang heeft, is dit probleem nu een ondergedetermineerd systeem dat oneindig veel oplossingen heeft. Het doel in dit geval is om de beste oplossing, d.w.z. met de laagste -norm, uit deze oneindig vele oplossingen te halen. Dit zou een zeer vervelend werk kunnen zijn als het rechtstreeks berekend zou moeten worden. Gelukkig is er een wiskundige truc die ons bij dit werk veel kan helpen.
Met behulp van een truc van Lagrange-multiplicatoren kunnen we dan een Lagrangiaan

definiëren waarbij  de ingevoerde Lagrange-multiplicatoren is. Neem de afgeleide van deze vergelijking gelijk aan nul om een optimale oplossing te vinden en krijg
de ingevoerde Lagrange-multiplicatoren is. Neem de afgeleide van deze vergelijking gelijk aan nul om een optimale oplossing te vinden en krijg
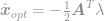
plug deze oplossing in de beperking om
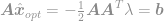
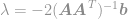
en tenslotte
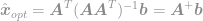
Met behulp van deze vergelijking kunnen we nu onmiddellijk een optimale oplossing berekenen van het -optimisatieprobleem. Deze vergelijking staat bekend als de Moore-Penrose Pseudoinverse en het probleem zelf staat gewoonlijk bekend als Least Square probleem, Least Square regressie, of Least Square optimalisatie.
Hoewel de oplossing van de Least Square methode gemakkelijk te berekenen is, is het echter niet noodzakelijk de beste oplossing. Door de vloeiende aard van de -norm zelf, is het moeilijk om één enkele, beste oplossing voor het probleem te vinden.

Integendeel, de -optimalisatie kan een veel beter resultaat opleveren dan deze oplossing.
l1-optimalisatie
Zoals gebruikelijk wordt het -minimalisatieprobleem geformuleerd als
 onderworpen aan
onderworpen aan
Omdat de aard van -norm niet glad is als in het -norm geval, is de oplossing van dit probleem veel beter en unieker dan de -optimalisatie.

Hoewel het probleem van de -minimalisatie bijna dezelfde vorm heeft als de -minimalisatie, is het echter veel moeilijker op te lossen. Omdat dit probleem geen gladde functie heeft, is de truc die we gebruikten om het -probleem op te lossen niet langer geldig. De enige manier die overblijft om de oplossing te vinden is door er direct naar te zoeken. Zoeken naar de oplossing betekent dat we alle mogelijke oplossingen moeten berekenen om de beste te vinden uit de poel van “oneindig veel” mogelijke oplossingen.
Omdat er geen gemakkelijke manier is om de oplossing voor dit probleem wiskundig te vinden, is het nut van -optimalisatie al tientallen jaren zeer beperkt. Tot voor kort stelt de vooruitgang van de computer met grote rekenkracht ons in staat om alle oplossingen te “sweepen”. Door gebruik te maken van vele nuttige algoritmen, namelijk het Convex Optimalisatie-algoritme zoals lineair programmeren, of niet-lineair programmeren, enz. is het nu mogelijk om de beste oplossing voor deze vraag te vinden. Veel toepassingen die op -optimalisatie berusten, waaronder de Compressive Sensing, zijn nu mogelijk.
Er zijn tegenwoordig veel toolboxes voor -optimalisatie beschikbaar. Deze toolboxes gebruiken gewoonlijk verschillende benaderingen en/of algoritmen om hetzelfde vraagstuk op te lossen. Voorbeelden van deze toolboxes zijn l1-magic, SparseLab, ISAL1,
Nu we veel leden van de norm-familie hebben besproken, te beginnen met -norm, -norm, en -norm. Het is tijd om over te gaan naar de volgende. Aangezien we in het begin al hebben besproken dat er elke l-wat norm kan zijn die dezelfde basisdefinitie van norm volgt, gaat het veel tijd kosten om ze allemaal te bespreken. Gelukkig zijn, afgezien van -, – , en -norm, de rest meestal ongebruikelijk en daarom niet zo interessant om naar te kijken. Dus gaan we kijken naar het extreme geval van norm, namelijk een 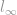 -norm (l-infinity norm).
-norm (l-infinity norm).
l-infinity norm
Zoals altijd is de definitie voor -norm
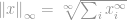
Nu ziet deze definitie er weer lastig uit, maar eigenlijk is hij vrij recht-toe-recht-aan. Beschouw de vector  , laten we zeggen dat als
, laten we zeggen dat als 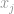 de hoogste waarde is in de vector , door de eigenschap van de oneindigheid zelf, kunnen we zeggen dat
de hoogste waarde is in de vector , door de eigenschap van de oneindigheid zelf, kunnen we zeggen dat
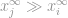

dan
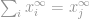
dan
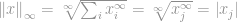
Nu kunnen we eenvoudigweg zeggen dat de -norm

dat is de maximale grootte van de ingangen van die vector. Daarmee is de betekenis van -norm
Nu we de hele normfamilie van tot hebben besproken, hoop ik dat deze bespreking zal bijdragen tot een beter begrip van de betekenis van norm, van zijn wiskundige eigenschappen en van zijn implicaties in de echte wereld.
Referentie en verder lezen:
Mathematical Norm – wikipedia
Mathematical Norm – MathWorld
Michael Elad – “Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing” , Springer, 2010.
Lineair Programmeren – MathWorld
Compressive Sensing – Rice University
Bewerking (15/02/15) : Onnauwkeurigheden in de inhoud gecorrigeerd.