Einführung
Mit der steigenden Nachfrage nach zuverlässigen und leistungsfähigen Infrastrukturen für kritische Systeme sind die Begriffe Skalierbarkeit und Hochverfügbarkeit in aller Munde. Während die Bewältigung einer erhöhten Systemlast ein allgemeines Anliegen ist, sind die Verringerung von Ausfallzeiten und die Beseitigung einzelner Fehlerpunkte ebenso wichtig. Hochverfügbarkeit ist eine Qualität des Infrastrukturdesigns bei der Skalierung, die letztere Überlegungen berücksichtigt.
In diesem Leitfaden wird erörtert, was Hochverfügbarkeit genau bedeutet und wie sie die Zuverlässigkeit Ihrer Infrastruktur verbessern kann.
Was ist Hochverfügbarkeit?
In der Informatik wird der Begriff Verfügbarkeit verwendet, um den Zeitraum zu beschreiben, in dem ein Dienst verfügbar ist, sowie die Zeit, die ein System benötigt, um auf eine Anfrage eines Benutzers zu reagieren. Hochverfügbarkeit ist eine Eigenschaft eines Systems oder einer Komponente, die ein hohes Maß an Betriebsleistung für einen bestimmten Zeitraum gewährleistet.
Messung der Verfügbarkeit
Verfügbarkeit wird oft als Prozentsatz ausgedrückt, der angibt, wie viel Betriebszeit von einem bestimmten System oder einer Komponente in einem bestimmten Zeitraum erwartet wird, wobei ein Wert von 100 % bedeuten würde, dass das System niemals ausfällt. Ein System, das eine Verfügbarkeit von 99 % über einen Zeitraum von einem Jahr garantiert, kann beispielsweise bis zu 3,65 Tage Ausfallzeit (1 %) haben.
Diese Werte werden auf der Grundlage mehrerer Faktoren berechnet, einschließlich geplanter und ungeplanter Wartungszeiträume sowie der Zeit für die Wiederherstellung nach einem möglichen Systemausfall.
Wie funktioniert Hochverfügbarkeit?
Hochverfügbarkeit funktioniert als Mechanismus zur Reaktion auf Ausfälle in der Infrastruktur. Die Funktionsweise ist konzeptionell recht einfach, erfordert aber in der Regel eine spezielle Software und Konfiguration.
Wann ist Hochverfügbarkeit wichtig?
Bei der Einrichtung robuster Produktionssysteme hat die Minimierung von Ausfallzeiten und Dienstunterbrechungen oft hohe Priorität. Unabhängig davon, wie zuverlässig Ihre Systeme und Software sind, können Probleme auftreten, die Ihre Anwendungen oder Server zum Erliegen bringen können.
Die Implementierung von Hochverfügbarkeit für Ihre Infrastruktur ist eine nützliche Strategie, um die Auswirkungen dieser Art von Ereignissen zu verringern. Hochverfügbare Systeme können sich nach einem Server- oder Komponentenausfall automatisch wiederherstellen.
Was macht ein System hochverfügbar?
Eines der Ziele von Hochverfügbarkeit ist die Beseitigung einzelner Fehlerquellen in Ihrer Infrastruktur. Ein Single Point of Failure ist eine Komponente Ihres Technologie-Stacks, die bei einem Ausfall eine Dienstunterbrechung verursachen würde. Jede Komponente, die für die ordnungsgemäße Funktionalität Ihrer Anwendung erforderlich ist und nicht redundant ist, wird als Single Point of Failure betrachtet.
Um Single Points of Failure auszuschließen, muss jede Schicht Ihres Stacks auf Redundanz vorbereitet sein. Stellen Sie sich vor, Sie haben eine Infrastruktur, die aus zwei identischen, redundanten Webservern hinter einem Load Balancer besteht. Der von den Kunden kommende Verkehr wird gleichmäßig auf die Webserver verteilt, aber wenn einer der Server ausfällt, leitet der Load Balancer den gesamten Verkehr auf den verbleibenden Online-Server um.
Die Webserver-Schicht ist in diesem Szenario kein Single Point of Failure, weil:
- redundante Komponenten für dieselbe Aufgabe vorhanden sind
- der Mechanismus über dieser Schicht (der Load Balancer) in der Lage ist, Ausfälle in den Komponenten zu erkennen und sein Verhalten für eine rechtzeitige Wiederherstellung anzupassen
Aber was passiert, wenn der Load Balancer offline geht?
Bei dem beschriebenen Szenario, das in der Praxis nicht ungewöhnlich ist, bleibt die Lastausgleichsschicht selbst ein Single Point of Failure. Diesen verbleibenden Single Point of Failure zu eliminieren, kann jedoch eine Herausforderung sein; auch wenn man leicht einen zusätzlichen Load Balancer konfigurieren kann, um Redundanz zu erreichen, gibt es keinen offensichtlichen Punkt oberhalb der Load Balancer, um Ausfallerkennung und Wiederherstellung zu implementieren.
Redundanz allein kann keine hohe Verfügbarkeit garantieren. Es muss ein Mechanismus vorhanden sein, um Ausfälle zu erkennen und Maßnahmen zu ergreifen, wenn eine der Komponenten Ihres Stacks nicht mehr verfügbar ist.
Fehlererkennung und Wiederherstellung für redundante Systeme können mit einem Top-to-Bottom-Ansatz implementiert werden: Die oberste Schicht ist dafür verantwortlich, die unmittelbar darunter liegende Schicht auf Ausfälle zu überwachen. In unserem vorherigen Beispielszenario ist der Load Balancer die oberste Schicht. Wenn einer der Webserver (untere Schicht) nicht mehr verfügbar ist, wird der Load Balancer die Umleitung von Anfragen für diesen Server einstellen.
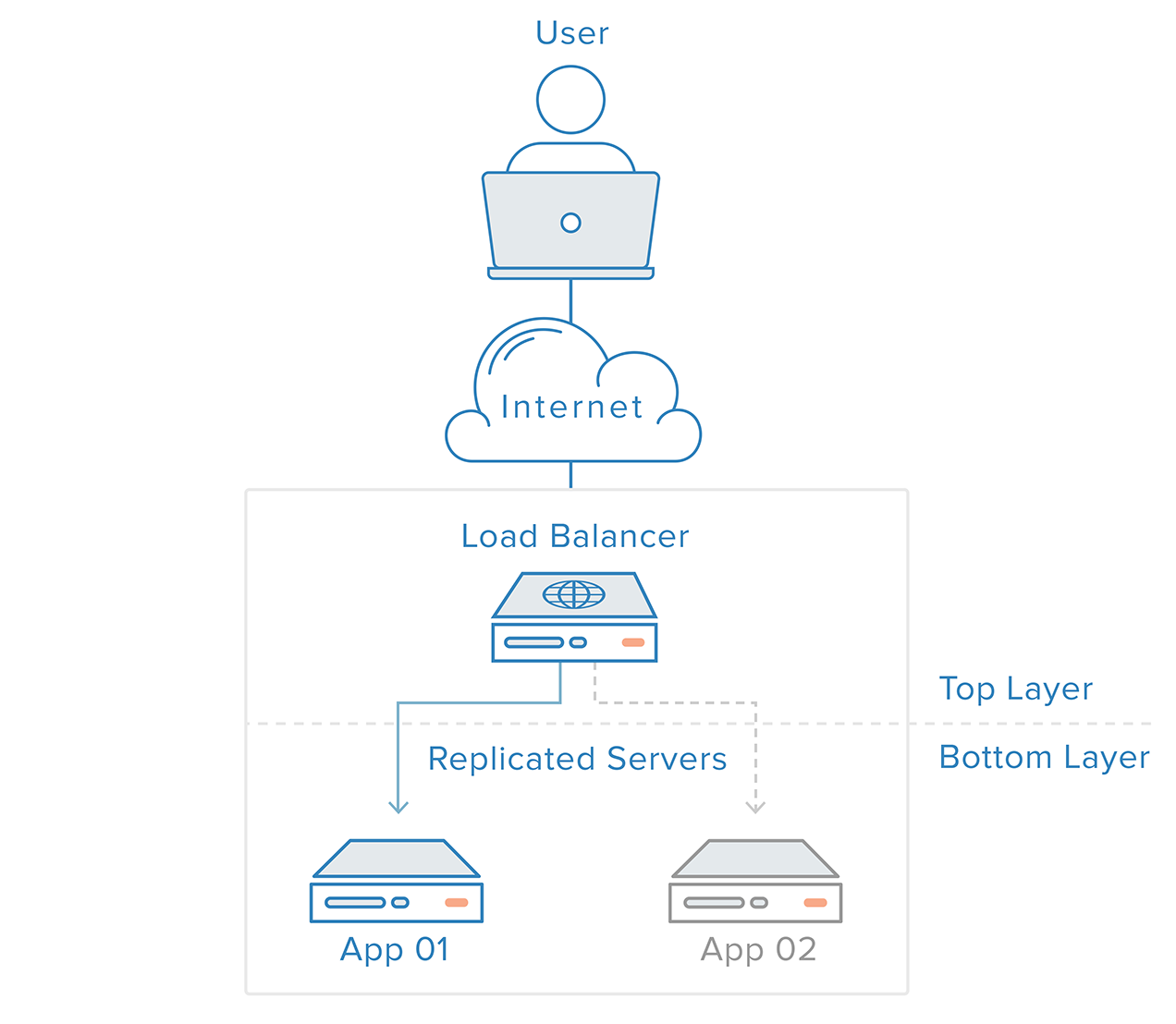
Dieser Ansatz ist tendenziell einfacher, hat aber seine Grenzen: Es wird einen Punkt in Ihrer Infrastruktur geben, an dem die oberste Schicht entweder nicht mehr existiert oder nicht mehr erreichbar ist, was bei der Load-Balancer-Schicht der Fall ist. Die Einrichtung eines Fehlererkennungsdienstes für den Load Balancer auf einem externen Server würde lediglich einen neuen Single Point of Failure schaffen.
Bei einem solchen Szenario ist ein verteilter Ansatz erforderlich. Mehrere redundante Knoten müssen zu einem Cluster zusammengeschlossen werden, wobei jeder Knoten gleichermaßen in der Lage sein sollte, Ausfälle zu erkennen und wiederherzustellen.
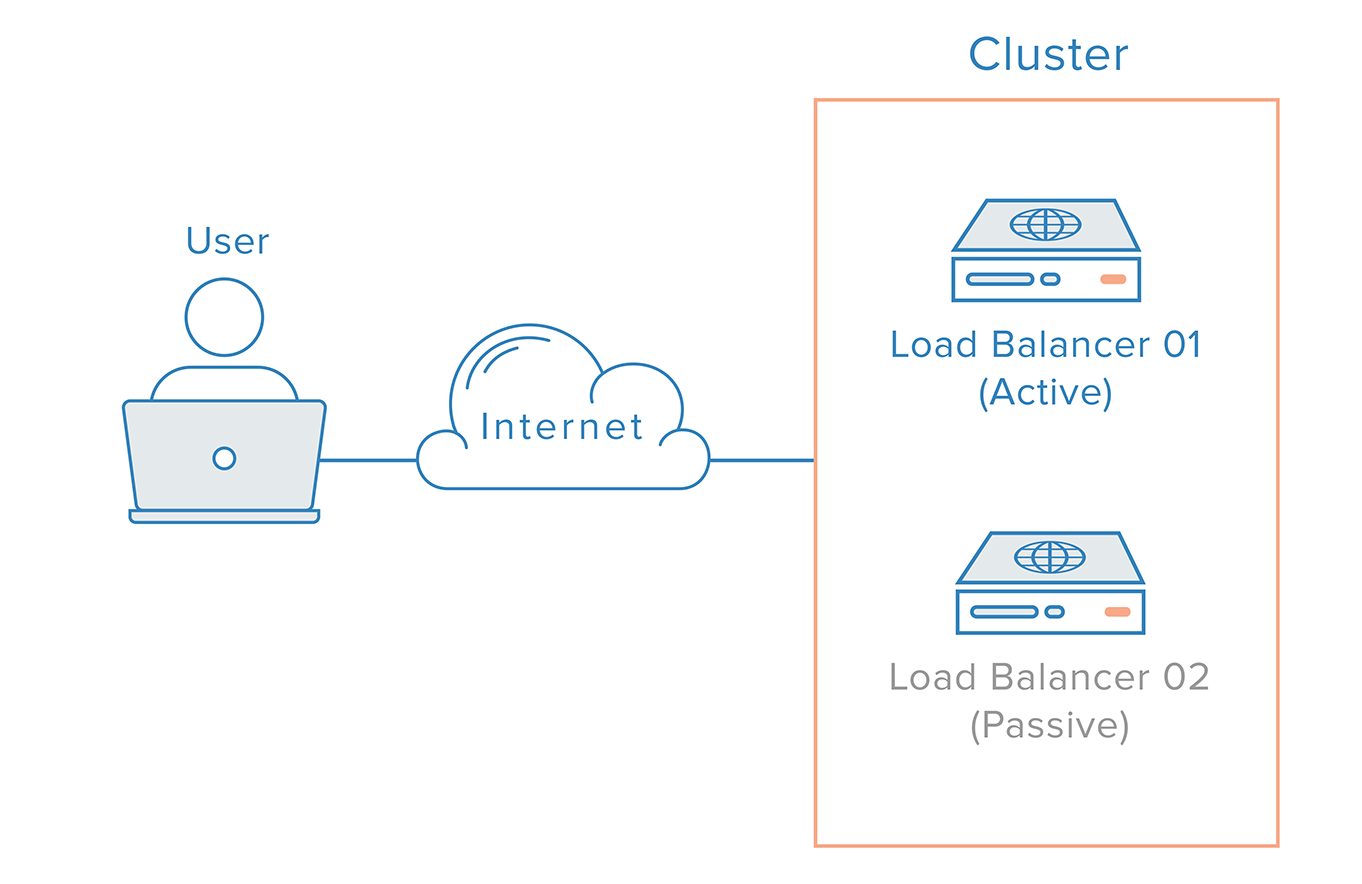
Für den Fall des Load Balancer gibt es jedoch eine zusätzliche Komplikation, die auf die Funktionsweise von Nameservern zurückzuführen ist. Die Wiederherstellung nach einem Load-Balancer-Ausfall bedeutet in der Regel einen Failover auf einen redundanten Load-Balancer, was bedeutet, dass eine DNS-Änderung vorgenommen werden muss, um einen Domänennamen auf die IP-Adresse des redundanten Load-Balancers zu verweisen. Eine solche Änderung kann eine beträchtliche Zeit in Anspruch nehmen, um sich im Internet zu verbreiten, was zu einer ernsthaften Ausfallzeit für dieses System führen würde.
Eine mögliche Lösung ist die Verwendung von DNS-Round-Robin-Lastausgleich. Dieser Ansatz ist jedoch nicht zuverlässig, da er die Ausfallsicherung der clientseitigen Anwendung überlässt.
Eine robustere und zuverlässigere Lösung ist die Verwendung von Systemen, die eine flexible Neuzuordnung von IP-Adressen ermöglichen, wie z. B. Floating IPs. Durch die bedarfsorientierte Neuzuweisung von IP-Adressen werden die mit DNS-Änderungen verbundenen Probleme der Weitergabe und des Zwischenspeicherns beseitigt, indem eine statische IP-Adresse bereitgestellt wird, die bei Bedarf einfach neu zugewiesen werden kann. Der Domänenname kann mit derselben IP-Adresse verbunden bleiben, während die IP-Adresse selbst zwischen Servern verschoben wird.
So sieht eine hochverfügbare Infrastruktur mit Floating IPs aus:

Welche Systemkomponenten sind für Hochverfügbarkeit erforderlich?
Es gibt mehrere Komponenten, die bei der Implementierung von Hochverfügbarkeit in der Praxis sorgfältig berücksichtigt werden müssen. Hochverfügbarkeit ist nicht nur eine Software-Implementierung, sondern hängt auch von folgenden Faktoren ab:
- Umgebung: Wenn sich alle Ihre Server in demselben geografischen Gebiet befinden, könnte eine Umweltbedingung wie ein Erdbeben oder eine Überschwemmung Ihr gesamtes System zum Erliegen bringen. Redundante Server in verschiedenen Rechenzentren und geografischen Gebieten erhöhen die Zuverlässigkeit.
- Hardware: Hochverfügbare Server sollten widerstandsfähig gegenüber Stromausfällen und Hardwarefehlern sein, einschließlich Festplatten und Netzwerkschnittstellen.
- Software: Der gesamte Software-Stack, einschließlich des Betriebssystems und der Anwendung selbst, muss auf den Umgang mit unerwarteten Ausfällen vorbereitet sein, die beispielsweise einen Neustart des Systems erfordern könnten.
- Daten: Datenverlust und -inkonsistenz können durch verschiedene Faktoren verursacht werden und beschränken sich nicht auf Festplattenausfälle. Hochverfügbare Systeme müssen die Sicherheit der Daten im Falle eines Ausfalls gewährleisten.
- Netzwerk: Ungeplante Netzwerkausfälle sind eine weitere mögliche Fehlerquelle für hochverfügbare Systeme. Es ist wichtig, dass eine redundante Netzwerkstrategie für mögliche Ausfälle vorhanden ist.
Welche Software kann zur Konfiguration von Hochverfügbarkeit verwendet werden?
Jede Ebene eines hochverfügbaren Systems hat unterschiedliche Anforderungen an Software und Konfiguration. Auf der Anwendungsebene sind Load Balancer jedoch ein wesentlicher Bestandteil der Software für die Einrichtung einer Hochverfügbarkeitslösung.
HAProxy (High Availability Proxy) ist eine gängige Wahl für den Lastausgleich, da er den Lastausgleich auf mehreren Ebenen und für verschiedene Arten von Servern, einschließlich Datenbankservern, bewältigen kann.
Wenn man sich im Systemstapel nach oben bewegt, ist es wichtig, eine zuverlässige redundante Lösung für den Einstiegspunkt Ihrer Anwendung, normalerweise den Lastausgleich, zu implementieren. Um diesen Single Point of Failure zu beseitigen, müssen wir, wie bereits erwähnt, einen Cluster von Load Balancern hinter einer Floating IP implementieren. Corosync und Pacemaker sind sowohl auf Ubuntu- als auch auf CentOS-Servern eine beliebte Wahl, um ein solches Setup zu erstellen.
Abschluss
Hochverfügbarkeit ist ein wichtiger Teilbereich der Zuverlässigkeitstechnik, der darauf abzielt, dass ein System oder eine Komponente in einem bestimmten Zeitraum ein hohes Maß an betrieblicher Leistung aufweist. Auf den ersten Blick mag ihre Umsetzung recht komplex erscheinen; sie kann jedoch für Systeme, die eine erhöhte Zuverlässigkeit erfordern, enorme Vorteile bringen.