Ich beschäftige mich in letzter Zeit viel mit dem Thema Norm und es ist an der Zeit, darüber zu sprechen. In diesem Beitrag werden wir über eine ganze Familie von Normen sprechen.
Was ist eine Norm?
Mathematisch ist eine Norm die Gesamtgröße oder Länge aller Vektoren in einem Vektorraum oder Matrizen. Der Einfachheit halber kann man sagen, dass je höher die Norm ist, desto größer ist die (Wert in) Matrix oder der Vektor. Die Norm kann in vielen Formen und unter vielen Namen auftreten, einschließlich dieser populären Namen: Euklidischer Abstand, mittlerer quadratischer Fehler usw.
Meistens wird die Norm in einer Gleichung wie dieser erscheinen:
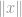 wobei
wobei  ein Vektor oder eine Matrix sein kann.
ein Vektor oder eine Matrix sein kann.
Zum Beispiel ist die euklidische Norm eines Vektors 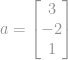
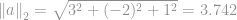 , was der Größe des Vektors
, was der Größe des Vektors 
Das obige Beispiel zeigt, wie man eine euklidische Norm, oder formal eine 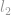 -Norm genannt, berechnet. Es gibt noch viele andere Arten von Normen, die hier nicht erklärt werden können, aber für jede einzelne reelle Zahl gibt es eine entsprechende Norm (Beachten Sie das betonte Wort reelle Zahl, das bedeutet, dass es nicht nur auf ganze Zahlen beschränkt ist.)
-Norm genannt, berechnet. Es gibt noch viele andere Arten von Normen, die hier nicht erklärt werden können, aber für jede einzelne reelle Zahl gibt es eine entsprechende Norm (Beachten Sie das betonte Wort reelle Zahl, das bedeutet, dass es nicht nur auf ganze Zahlen beschränkt ist.)
Formell ist die  -Norm von
-Norm von  wie folgt definiert:
wie folgt definiert:
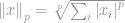 wobei
wobei 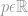
Das war’s! Die p-te Wurzel einer Summierung aller Elemente zur p-ten Potenz nennen wir eine Norm.
Das Interessante ist, dass, obwohl alle -Normen einander sehr ähnlich sind, ihre mathematischen Eigenschaften sehr unterschiedlich sind und sich daher auch ihre Anwendung dramatisch unterscheidet. Im Folgenden werden wir uns einige dieser Normen im Detail ansehen.
l0-Norm
Die erste Norm, die wir besprechen werden, ist eine 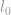 -Norm. Per Definition ist die -Norm von
-Norm. Per Definition ist die -Norm von
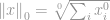
Streng genommen ist die -Norm keine eigentliche Norm. Es handelt sich um eine Kardinalitätsfunktion, die in der Form von -norm definiert ist, obwohl viele Leute sie als Norm bezeichnen. Es ist ein bisschen schwierig, mit ihr zu arbeiten, weil sie eine Null-Potenz und eine Null-Wurzel enthält. Natürlich wird jede 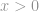 -Norm zu einer solchen, aber die Probleme mit der Definition der nullten Potenz und insbesondere der nullten Wurzel bringen die Dinge hier durcheinander. In der Realität verwenden die meisten Mathematiker und Ingenieure stattdessen diese Definition der -Norm:
-Norm zu einer solchen, aber die Probleme mit der Definition der nullten Potenz und insbesondere der nullten Wurzel bringen die Dinge hier durcheinander. In der Realität verwenden die meisten Mathematiker und Ingenieure stattdessen diese Definition der -Norm:
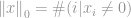
Das ist die Gesamtzahl der Nicht-Null-Elemente in einem Vektor.
Da es sich um eine Zahl von Nicht-Null-Elementen handelt, gibt es viele Anwendungen, die die -Norm verwenden. In letzter Zeit ist sie noch mehr in den Fokus gerückt, weil das Compressive Sensing Schema aufkam, das versucht, die spärlichste Lösung des unterbestimmten linearen Systems zu finden. Die spärlichste Lösung ist die Lösung mit den wenigsten Nicht-Null-Einträgen, d.h. mit der niedrigsten -Norm. Dieses Problem wird in der Regel als -Norm-Optimierungsproblem oder -Optimierung bezeichnet.
l0-Optimierung
Viele Anwendungen, einschließlich Compressive Sensing, versuchen, die -Norm eines Vektors zu minimieren, der einigen Nebenbedingungen entspricht, und werden daher „-Minimierung“ genannt. Ein Standard-Minimierungsproblem wird wie folgt formuliert:
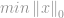 unter
unter 
Das ist jedoch keine leichte Aufgabe. Aufgrund der fehlenden mathematischen Repräsentation der -Norm wird die -Minimierung von Informatikern als NP-hartes Problem angesehen, was einfach bedeutet, dass es zu komplex und fast unmöglich zu lösen ist.
In vielen Fällen wird das -Minimierungsproblem zu einem Norm-Problem höherer Ordnung entspannt, wie z.B. 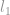 -Minimierung und -Minimierung.
-Minimierung und -Minimierung.
l1-Norm
In Anlehnung an die Definition der Norm wird die -Norm von wie folgt definiert
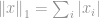
Diese Norm ist in der Norm-Familie recht verbreitet. Sie hat viele Namen und viele Formen in verschiedenen Bereichen, nämlich die Manhattan-Norm ist ihr Spitzname. Wenn die -Norm für eine Differenz zwischen zwei Vektoren oder Matrizen berechnet wird, d.h.
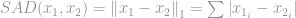
wird sie unter Informatikern als Summe der absoluten Differenz (SAD) bezeichnet.
Im allgemeineren Fall der Messung von Signaldifferenzen kann sie auf einen Einheitsvektor skaliert werden durch:
 wobei
wobei  eine Größe von ist.
eine Größe von ist.
Dies wird als Mean-Absolute Error (MAE) bezeichnet.
l2-Norm
Die populärste aller Normen ist die -Norm. Sie wird in fast allen Bereichen der Technik und der Wissenschaft insgesamt verwendet. Nach der grundlegenden Definition ist die -Norm definiert als
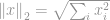
-Norm ist bekannt als euklidische Norm, die als Standardgröße zur Messung einer Vektordifferenz verwendet wird. Wenn die euklidische Norm für eine Vektordifferenz berechnet wird, spricht man wie bei der -Norm von einem euklidischen Abstand:
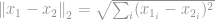
oder in seiner quadrierten Form, die unter Computer-Vision-Wissenschaftlern als Sum of Squared Difference (SSD) bekannt ist:

Seine bekannteste Anwendung im Bereich der Signalverarbeitung ist die Messung des mittleren quadratischen Fehlers (MSE), die zur Berechnung einer Ähnlichkeit, einer Qualität oder einer Korrelation zwischen zwei Signalen verwendet wird. MSE ist
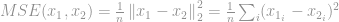
Wie bereits im Abschnitt -Optimierung besprochen, entspannen sich viele -Optimierungsprobleme aufgrund vieler Probleme sowohl aus rechnerischer als auch aus mathematischer Sicht und werden stattdessen zu – und -Optimierung. Aus diesem Grund werden wir nun die -Optimierung diskutieren.
l2-Optimierung
Wie im Fall der -Optimierung wird das Problem der Minimierung der -Norm formuliert durch
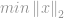 in Abhängigkeit von
in Abhängigkeit von
Angenommen, die Constraint-Matrix 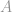 hat vollen Rang, so ist dieses Problem nun ein untergeordnetes System, das unendlich viele Lösungen hat. Das Ziel in diesem Fall ist es, die beste Lösung, d.h. mit der niedrigsten -Norm, aus diesen unendlich vielen Lösungen herauszufinden. Dies könnte eine sehr mühsame Arbeit sein, wenn sie direkt berechnet werden müsste. Zum Glück gibt es einen mathematischen Trick, der uns bei dieser Arbeit sehr helfen kann.
hat vollen Rang, so ist dieses Problem nun ein untergeordnetes System, das unendlich viele Lösungen hat. Das Ziel in diesem Fall ist es, die beste Lösung, d.h. mit der niedrigsten -Norm, aus diesen unendlich vielen Lösungen herauszufinden. Dies könnte eine sehr mühsame Arbeit sein, wenn sie direkt berechnet werden müsste. Zum Glück gibt es einen mathematischen Trick, der uns bei dieser Arbeit sehr helfen kann.
Mit Hilfe eines Tricks der Lagrange-Multiplikatoren können wir dann eine Lagrange-Gleichung

definieren, wobei  der eingeführte Lagrange-Multiplikator ist. Nehmen wir die Ableitung dieser Gleichung gleich Null, um eine optimale Lösung zu finden, so erhalten wir
der eingeführte Lagrange-Multiplikator ist. Nehmen wir die Ableitung dieser Gleichung gleich Null, um eine optimale Lösung zu finden, so erhalten wir
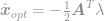
Setzen wir diese Lösung in die Nebenbedingung ein, so erhalten wir
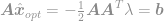
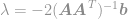
und schließlich
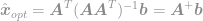
Mit Hilfe dieser Gleichung können wir nun sofort eine optimale Lösung für das -Optimierungsproblem berechnen. Diese Gleichung ist als Moore-Penrose-Pseudoinverse bekannt, und das Problem selbst wird gewöhnlich als Least-Square-Problem, Least-Square-Regression oder Least-Square-Optimierung bezeichnet.
Auch wenn die Lösung der Least-Square-Methode einfach zu berechnen ist, muss sie nicht unbedingt die beste Lösung sein. Wegen der glatten Natur der -Norm selbst ist es schwierig, eine einzige, beste Lösung für das Problem zu finden.

Im Gegenteil, die -Optimierung kann viel bessere Ergebnisse als diese Lösung liefern.
l1-Optimierung
Wie üblich wird das -Minimierungsproblem formuliert als
 vorbehaltlich
vorbehaltlich
Da die Natur der -Norm nicht glatt ist wie im Fall der -Norm, ist die Lösung dieses Problems viel besser und eindeutiger als die -Optimierung.

Aber obwohl das Problem der -Minimierung fast die gleiche Form hat wie die -Minimierung, ist es viel schwieriger zu lösen. Da dieses Problem keine glatte Funktion hat, ist der Trick, den wir zur Lösung des -Problems verwendet haben, nicht mehr gültig. Die einzige Möglichkeit, die Lösung zu finden, besteht darin, direkt nach ihr zu suchen. Die Suche nach der Lösung bedeutet, dass wir jede einzelne mögliche Lösung berechnen müssen, um die beste aus dem Pool der „unendlich vielen“ möglichen Lösungen zu finden.
Da es keinen einfachen Weg gibt, die Lösung für dieses Problem mathematisch zu finden, ist der Nutzen der -Optimierung seit Jahrzehnten sehr begrenzt. Erst in jüngster Zeit hat die Entwicklung von Computern mit hoher Rechenleistung es ermöglicht, alle Lösungen zu „durchforsten“. Durch den Einsatz vieler hilfreicher Algorithmen, insbesondere der konvexen Optimierung, wie z. B. der linearen Programmierung oder der nichtlinearen Programmierung usw., ist es nun möglich, die beste Lösung für diese Frage zu finden. Viele Anwendungen, die auf -Optimierung beruhen, einschließlich des Compressive Sensing, sind jetzt möglich.
Es gibt heutzutage viele Toolboxen für -Optimierung. Diese Toolboxen verwenden in der Regel unterschiedliche Ansätze und/oder Algorithmen, um die gleiche Fragestellung zu lösen. Beispiele für diese Toolboxen sind l1-magic, SparseLab, ISAL1,
Nun haben wir viele Mitglieder der Normenfamilie besprochen, beginnend mit -Norm, -Norm und -Norm. Es ist an der Zeit, zum nächsten überzugehen. Da wir ganz am Anfang besprochen haben, dass es jede beliebige l-was-auch-immer-Norm geben kann, die der gleichen grundlegenden Definition von Norm folgt, wird es viel Zeit in Anspruch nehmen, über sie alle zu sprechen. Glücklicherweise sind die übrigen Normen, abgesehen von -, – und -Norm, eher unüblich und daher nicht so interessant. Wir werden uns also den Extremfall der Norm ansehen, die 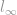 -Norm (l-unendlich-Norm).
-Norm (l-unendlich-Norm).
l-unendlich-Norm
Wie immer lautet die Definition für die -Norm
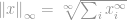
Nun sieht diese Definition wieder knifflig aus, aber eigentlich ist sie ziemlich einfach. Betrachten wir den Vektor  , sagen wir, wenn
, sagen wir, wenn 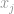 der höchste Eintrag im Vektor ist, durch die Eigenschaft der Unendlichkeit selbst, können wir sagen, dass
der höchste Eintrag im Vektor ist, durch die Eigenschaft der Unendlichkeit selbst, können wir sagen, dass
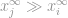

dann
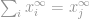
dann
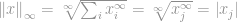
Jetzt können wir einfach sagen, dass die -Norm

das ist der maximale Betrag der Einträge in diesem Vektor. Damit ist die Bedeutung der -Norm
sicher entmystifiziert. Jetzt haben wir die ganze Familie der Normen von bis besprochen, und ich hoffe, dass diese Diskussion dazu beiträgt, die Bedeutung der Norm, ihre mathematischen Eigenschaften und ihre Auswirkungen in der Praxis zu verstehen.
Referenz und weiterführende Literatur:
Mathematische Norm – wikipedia
Mathematische Norm – MathWorld
Michael Elad – „Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing“ , Springer, 2010.
Linear Programming – MathWorld
Compressive Sensing – Rice University
Edit (15/02/15) : Ungenauigkeiten im Inhalt korrigiert.